More than 96% of all manufactured goods — ranging from everyday products, like laundry detergent and food packaging, to advanced industrial components, such as semiconductors, batteries and solar panels — rely on chemicals that cannot be replaced with alternative materials.
With AI and the latest technological advancements, researchers and developers are studying ways to create novel materials that could address the world’s toughest challenges, such as energy storage and environmental remediation.
Announced today at the Supercomputing 2024 conference in Atlanta, the NVIDIA ALCHEMI NIM microservice accelerates such research by optimizing AI inference for chemical simulations that could lead to more efficient and sustainable materials to support the renewable energy transition.
It’s one of the many ways NVIDIA is supporting researchers, developers and enterprises to boost energy and resource efficiency in their workflows, including to meet requirements aligned with the global Net Zero Initiative.
NVIDIA ALCHEMI for Material and Chemical Simulations
Exploring the universe of potential materials, using the nearly infinite combinations of chemicals — each with unique characteristics — can be extremely complex and time consuming. Novel materials are typically discovered through laborious, trial-and-error synthesis and testing in a traditional lab.
Many of today’s plastics, for example, are still based on material discoveries made in the mid-1900s.
More recently, AI has emerged as a promising accelerant for chemicals and materials innovation.
With the new ALCHEMI NIM microservice, researchers can test chemical compounds and material stability in simulation, in a virtual AI lab, which reduces costs, energy consumption and time to discovery.
For example, running MACE-MP-0, a pretrained foundation model for materials chemistry, on an NVIDIA H100 Tensor Core GPU, the new NIM microservice speeds evaluations of a potential composition’s simulated long-term stability 100x. The below figure shows a 25x speedup from using the NVIDIA Warp Python framework for high-performance simulation, followed by a 4x speedup with in-flight batching. All in all, evaluating 16 million structures would have taken months — with the NIM microservice, it can be done in just hours.

By letting scientists examine more structures in less time, the NIM microservice can boost research on materials for use with solar and electric batteries, for example, to bolster the renewable energy transition.
NVIDIA also plans to release NIM microservices that can be used to simulate the manufacturability of novel materials — to determine how they might be brought from test tubes into the real world in the form of batteries, solar panels, fertilizers, pesticides and other essential products that can contribute to a healthier, greener planet.
SES AI, a leading developer of lithium-metal batteries, is using the NVIDIA ALCHEMI NIM microservice with the AIMNet2 model to accelerate the identification of electrolyte materials used for electric vehicles.
“SES AI is dedicated to advancing lithium battery technology through AI-accelerated material discovery, using our Molecular Universe Project to explore and identify promising candidates for lithium metal electrolyte discovery,” said Qichao Hu, CEO of SES AI. “Using the ALCHEMI NIM microservice with AIMNet2 could drastically improve our ability to map molecular properties, reducing time and costs significantly and accelerating innovation.”
SES AI recently mapped 100,000 molecules in half a day, with the potential to achieve this in under an hour using ALCHEMI. This signals how the microservice is poised to have a transformative impact on material screening efficiency.
Looking ahead, SES AI aims to map the properties of up to 10 billion molecules within the next couple of years, pushing the boundaries of AI-driven, high-throughput discovery.
The new microservice will soon be available for researchers to test for free through the NVIDIA NGC catalog — be notified of ALCHEMI’s launch. It will also be downloadable from build.nvidia.com, and the production-grade NIM microservice will be offered through the NVIDIA AI Enterprise software platform.
Learn more about the NVIDIA ALCHEMI NIM microservice, and hear the latest on how AI and supercomputing are supercharging researchers and developers’ workflows by joining NVIDIA at SC24, running through Friday, Nov. 22.
See notice regarding software product information.
]]>Generative AI is taking root at national and corporate labs, accelerating high-performance computing for business and science.
Researchers at Sandia National Laboratories aim to automatically generate code in Kokkos, a parallel programming language designed for use across many of the world’s largest supercomputers.
It’s an ambitious effort. The specialized language, developed by researchers from several national labs, handles the nuances of running tasks across tens of thousands of processors.
Sandia is employing retrieval-augmented generation (RAG) to create and link a Kokkos database with AI models. As researchers experiment with different RAG approaches, initial tests show promising results.
Cloud-based services like NeMo Retriever are among the RAG options the scientists will evaluate.
“NVIDIA provides a rich set of tools to help us significantly accelerate the work of our HPC software developers,” said Robert Hoekstra, a senior manager of extreme scale computing at Sandia.
Building copilots via model tuning and RAG is just a start. Researchers eventually aim to employ foundation models trained with scientific data from fields such as climate, biology and material science.
Getting Ahead of the Storm
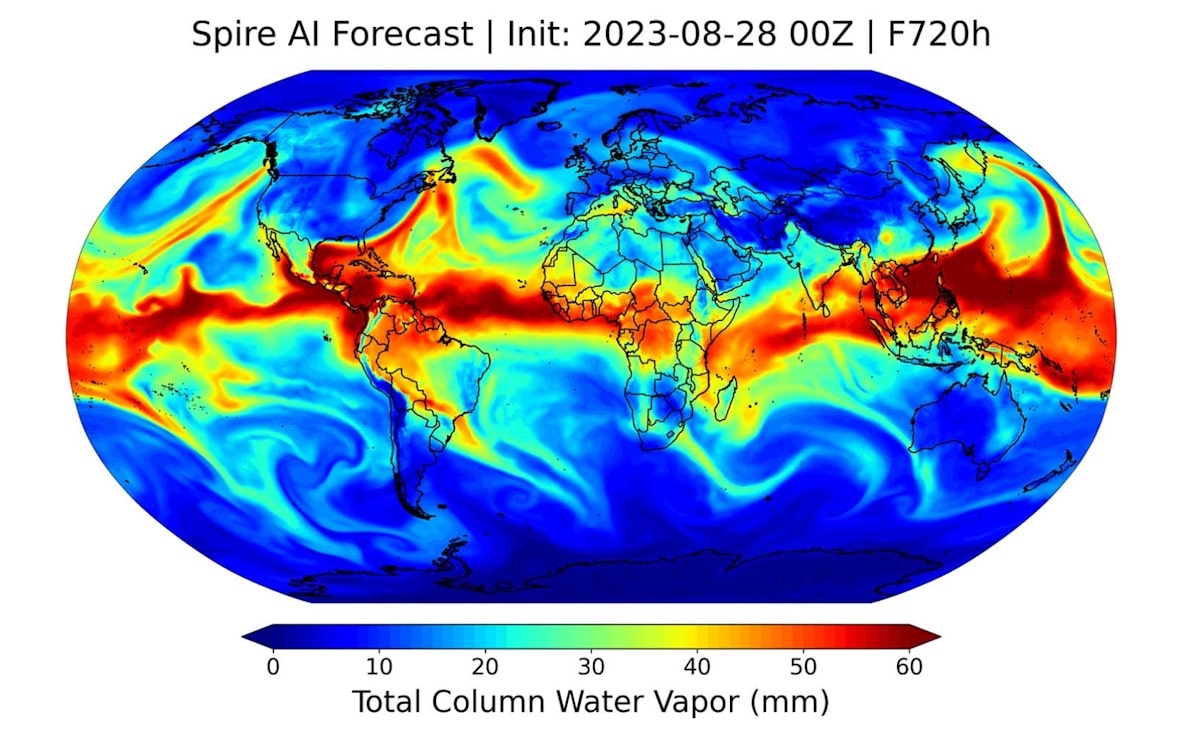
Researchers and companies in weather forecasting are embracing CorrDiff, a generative AI model that’s part of NVIDIA Earth-2, a set of services and software for weather and climate research.
CorrDiff can scale the 25km resolution of traditional atmosphere models down to 2 kilometers and expand by more than 100x the number of forecasts that can be combined to improve confidence in predictions.
“It’s a promising innovation … We plan to leverage such models in our global and regional AI forecasts for richer insights,” said Tom Gowan, machine learning and modeling lead for Spire, a company in Vienna, Va., that collects data from its own network of tiny satellites.
Generative AI enables faster, more accurate forecasts, he said in a recent interview.
“It really feels like a big jump in meteorology,” he added. “And by partnering with NVIDIA, we have access to the world’s best GPUs that are the most reliable, fastest and most efficient ones for both training and inference.”
Switzerland-based Meteomatics recently announced it also plans to use NVIDIA’s generative AI platform for its weather forecasting business.
“Our work with NVIDIA will help energy companies maximize their renewable energy operations and increase their profitability with quick and accurate insight into weather fluctuations,” said Martin Fengler, founder and CEO of Meteomatics.
Generating Genes to Improve Healthcare
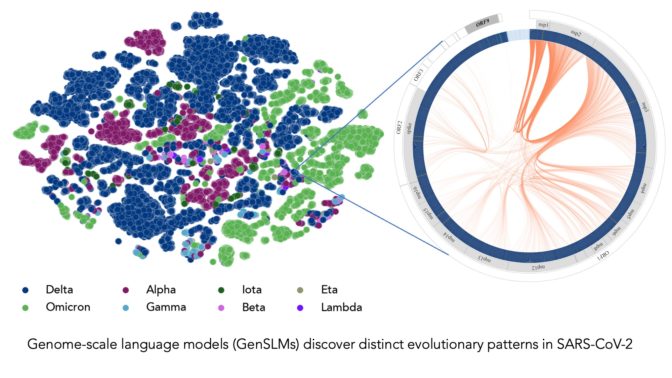
At Argonne National Laboratory, scientists are using the technology to generate gene sequences that help them better understand the virus behind COVID-19. Their award-winning models, called GenSLMs, spawned simulations that closely resemble real-world variants of SARS-CoV-2.
“Understanding how different parts of the genome are co-evolving gives us clues about how the virus may develop new vulnerabilities or new forms of resistance,” Arvind Ramanathan, a lead researcher, said in a blog.
GenSLMs were trained on more than 110 million genome sequences with NVIDIA A100 Tensor Core GPU-powered supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
Microsoft Proposes Novel Materials
Microsoft Research showed how generative AI can accelerate work in materials science.
Their MatterGen model generates novel, stable materials that exhibit desired properties. The approach enables specifying chemical, magnetic, electronic, mechanical and other desired properties.
“We believe MatterGen is an important step forward in AI for materials design,” the Microsoft Research team wrote of the model they trained on Azure AI infrastructure with NVIDIA A100 GPUs.
Companies such as Carbon3D are already finding opportunities, applying generative AI to materials science in commercial 3D printing operations.
It’s just the beginning of what researchers will be able to do for HPC and science with generative AI. The NVIDIA H200 Tensor Core GPUs available now and the upcoming NVIDIA Blackwell Architecture GPUs will take their work to new levels.
Learn more about tools like NVIDIA Modulus, a key component in the Earth-2 platform for building AI models that obey the laws of physics, and NVIDIA Megatron-Core, a NeMo library to tune and train large language models.
]]>Editor’s note: This post was updated on November 17 after the announcement of the Gordon Bell prize winners.
The winner of the Gordon Bell special prize for high performance computing-based COVID-19 research has taught large language models (LLMs) a new lingo — gene sequences — that can unlock insights in genomics, epidemiology and protein engineering.
Published in October, the groundbreaking work is a collaboration by more than two dozen academic and commercial researchers from Argonne National Laboratory, NVIDIA, the University of Chicago and others.
The research team trained an LLM to track genetic mutations and predict variants of concern in SARS-CoV-2, the virus behind COVID-19. While most LLMs applied to biology to date have been trained on datasets of small molecules or proteins, this project is one of the first models trained on raw nucleotide sequences — the smallest units of DNA and RNA.
“We hypothesized that moving from protein-level to gene-level data might help us build better models to understand COVID variants,” said Arvind Ramanathan, computational biologist at Argonne, who led the project. “By training our model to track the entire genome and all the changes that appear in its evolution, we can make better predictions about not just COVID, but any disease with enough genomic data.”
The Gordon Bell awards, regarded as the Nobel Prize of high performance computing, were presented at the SC22 conference by the Association for Computing Machinery, which represents around 100,000 computing experts worldwide. Since 2020, the group has awarded a special prize for outstanding research that advances the understanding of COVID with HPC.
Training LLMs on a Four-Letter Language
LLMs have long been trained on human languages, which usually comprise a couple dozen letters that can be arranged into tens of thousands of words, and joined together into longer sentences and paragraphs. The language of biology, on the other hand, has only four letters representing nucleotides — A, T, G and C in DNA, or A, U, G and C in RNA — arranged into different sequences as genes.
While fewer letters may seem like a simpler challenge for AI, language models for biology are actually far more complicated. That’s because the genome — made up of over 3 billion nucleotides in humans, and about 30,000 nucleotides in coronaviruses — is difficult to break down into distinct, meaningful units.
“When it comes to understanding the code of life, a major challenge is that the sequencing information in the genome is quite vast,” Ramanathan said. “The meaning of a nucleotide sequence can be affected by another sequence that’s much further away than the next sentence or paragraph would be in human text. It could reach over the equivalent of chapters in a book.”
NVIDIA collaborators on the project designed a hierarchical diffusion method that enabled the LLM to treat long strings of around 1,500 nucleotides as if they were sentences.
“Standard language models have trouble generating coherent long sequences and learning the underlying distribution of different variants,” said paper co-author Anima Anandkumar, senior director of AI research at NVIDIA and Bren professor in the computing + mathematical sciences department at Caltech. “We developed a diffusion model that operates at a higher level of detail that allows us to generate realistic variants and capture better statistics.”
Predicting COVID Variants of Concern
Using open-source data from the Bacterial and Viral Bioinformatics Resource Center, the team first pretrained its LLM on more than 110 million gene sequences from prokaryotes, which are single-celled organisms like bacteria. It then fine-tuned the model using 1.5 million high-quality genome sequences for the COVID virus.
By pretraining on a broader dataset, the researchers also ensured their model could generalize to other prediction tasks in future projects — making it one of the first whole-genome-scale models with this capability.
Once fine-tuned on COVID data, the LLM was able to distinguish between genome sequences of the virus’ variants. It was also able to generate its own nucleotide sequences, predicting potential mutations of the COVID genome that could help scientists anticipate future variants of concern.
“Most researchers have been tracking mutations in the spike protein of the COVID virus, specifically the domain that binds with human cells,” Ramanathan said. “But there are other proteins in the viral genome that go through frequent mutations and are important to understand.”
The model could also integrate with popular protein-structure-prediction models like AlphaFold and OpenFold, the paper stated, helping researchers simulate viral structure and study how genetic mutations impact a virus’ ability to infect its host. OpenFold is one of the pretrained language models included in the NVIDIA BioNeMo LLM service for developers applying LLMs to digital biology and chemistry applications.
Supercharging AI Training With GPU-Accelerated Supercomputers
The team developed its AI models on supercomputers powered by NVIDIA A100 Tensor Core GPUs — including Argonne’s Polaris, the U.S. Department of Energy’s Perlmutter, and NVIDIA’s in-house Selene system. By scaling up to these powerful systems, they achieved performance of more than 1,500 exaflops in training runs, creating the largest biological language models to date.
“We’re working with models today that have up to 25 billion parameters, and we expect this to significantly increase in the future,” said Ramanathan. “The model size, the genetic sequence lengths and the amount of training data needed means we really need the computational complexity provided by supercomputers with thousands of GPUs.”
The researchers estimate that training a version of their model with 2.5 billion parameters took over a month on around 4,000 GPUs. The team, which was already investigating LLMs for biology, spent about four months on the project before publicly releasing the paper and code. The GitHub page includes instructions for other researchers to run the model on Polaris and Perlmutter.
The NVIDIA BioNeMo framework, available in early access on the NVIDIA NGC hub for GPU-optimized software, supports researchers scaling large biomolecular language models across multiple GPUs. Part of the NVIDIA Clara Discovery collection of drug discovery tools, the framework will support chemistry, protein, DNA and RNA data formats.
Find NVIDIA at SC22 and watch a replay of the special address below:
Image at top represents COVID strains sequenced by the researchers’ LLM. Each dot is color-coded by COVID variant. Image courtesy of Argonne National Laboratory’s Bharat Kale, Max Zvyagin and Michael E. Papka.
]]>Collaboration among researchers, like the scientific community itself, spans the globe.
Universities and enterprises sharing work over long distances require a common language and secure pipeline to get every device — from microscopes and sensors to servers and campus networks — to see and understand the data each is transmitting. The increasing amount of data that needs to be stored, transmitted and analyzed only compounds the challenge.
To overcome this problem, NVIDIA has introduced a high performance computing platform that combines edge computing and AI to capture and consolidate streaming data from scientific edge instruments, and then allow the devices to talk to each other over long distances.
The platform consists of three major components. NVIDIA Holoscan is a software development kit that data scientists and domain experts can use to build GPU-accelerated pipelines for sensors that stream data. MetroX-3 is a new long-haul system that extends the connectivity of the NVIDIA Quantum-2 InfiniBand platform. And NVIDIA BlueField-3 DPUs provide secure and intelligent data migration.
Researchers can use the new NVIDIA platform for HPC edge computing to securely communicate and collaborate on solving problems and bring their disparate devices and algorithms together to operate as one large supercomputer.
Holoscan for HPC at the Edge
Accelerated by GPU computing platforms — including NVIDIA IGX, HGX, DGX systems — NVIDIA Holoscan delivers the extreme performance required to process massive streams of data generated by the world’s scientific instruments.
NVIDIA Holoscan for HPC includes new APIs for C++ and Python that HPC researchers can use to build sensor data processing workflows that are flexible enough for non-image formats and scalable enough to translate raw data into real-time insights.
Holoscan also manages memory allocation to ensure zero-copy data exchanges, so developers can focus on the workflow logic and not worry about managing file and memory I/O.
The new features in Holoscan will be available to all the HPC developers next month. Sign up to be notified of early access to Holoscan 0.4 SDK.
MetroX-3 Goes the Distance
The NVIDIA MetroX-3 long-haul system, available next month, extends the latest cloud-native capabilities of the NVIDIA Quantum-2 InfiniBand platform from the edge to the HPC data center core. It enables GPUs between sites to securely share data over the InfiniBand network up to 25 miles (40km) away.
Taking advantage of native remote direct memory access, users can easily migrate data and compute jobs from one InfiniBand-connected mini-cluster to the main data center, or combine geographically dispersed compute clusters for higher overall performance and scalability.
Data center operators can efficiently provision, monitor and operate across all the InfiniBand-connected data center networks by using the NVIDIA Unified Fabric Manager to manage their MetroX-3 systems.
BlueField for Secure, Efficient HPC
NVIDIA BlueField data processing units offload, accelerate and isolate advanced networking, storage and security services to boost performance and efficiency for modern HPC.
During SC22, system software company Zettar is demonstrating its data migration and storage offload solution based on BlueField-3. Zettar software can consolidate data migration tasks to a data center footprint of 4U rack space, which today requires 13U with x86-based solutions.
Learn more about the new NVIDIA platform for HPC computing at the edge.
]]>Seven finalists including both winners of the 2020 Gordon Bell awards used supercomputers to see more clearly atoms, stars and more — all accelerated with NVIDIA technologies.
Their efforts required the traditional number crunching of high performance computing, the latest data science in graph analytics, AI techniques like deep learning or combinations of all of the above.
The Gordon Bell Prize is regarded as a Nobel Prize in the supercomputing community, attracting some of the most ambitious efforts of researchers worldwide.
AI Helps Scale Simulation 1,000x
Winners of the traditional Gordon Bell award collaborated across universities in Beijing, Berkeley and Princeton as well as Lawrence Berkeley National Laboratory (Berkeley Lab). They used a combination of HPC and neural networks they called DeePMDkit to create complex simulations in molecular dynamics, 1,000x faster than previous work while maintaining accuracy.
In one day on the Summit supercomputer at Oak Ridge National Laboratory, they modeled 2.5 nanoseconds in the life of 127.4 million atoms, 100x more than the prior efforts.
Their work aids understanding complex materials and fields with heavy use of molecular modeling like drug discovery. In addition, it demonstrated the power of combining machine learning with physics-based modeling and simulation on future supercomputers.
Atomic-Scale HPC May Spawn New Materials
Among the finalists, a team including members from Berkeley Lab and Stanford optimized the BerkeleyGW application to bust through the complex math needed to calculate atomic forces binding more than 1,000 atoms with 10,986 electrons, about 10x more than prior efforts.
“The idea of working on a system with tens of thousands of electrons was unheard of just 5-10 years ago,” said Jack Deslippe, a principal investigator on the project and the application performance lead at the U.S. National Energy Research Scientific Computing Center.
Their work could pave a way to new materials for better batteries, solar cells and energy harvesters as well as faster semiconductors and quantum computers.
The team used all 27,654 GPUs on the Summit supercomputer to get results in just 10 minutes, thanks to harnessing an estimated 105.9 petaflops of double-precision performance.
Developers are continuing the work, optimizing their code for Perlmutter, a next-generation system using NVIDIA A100 Tensor Core GPUs that sport hardware to accelerate 64-bit floating-point jobs.
Analytics Sifts Text to Fight COVID
Using a form of data mining called graph analytics, a team from Oak Ridge and Georgia Institute of Technology found a way to search for deep connections in medical literature using a dataset they created with 213 million relationships among 18.5 million concepts and papers.
Their DSNAPSHOT (Distributed Accelerated Semiring All-Pairs Shortest Path) algorithm, using the team’s customized CUDA code, ran on 24,576 V100 GPUs on Summit, delivering results on a graph with 4.43 million vertices in 21.3 minutes. They claimed a record for deep search in a biomedical database and showed the way for others.

“Looking forward, we believe this novel capability will enable the mining of scholarly knowledge … (and could be used in) natural language processing workflows at scale,” Ramakrishnan Kannan, team lead for computational AI and machine learning at Oak Ridge, said in an article on the lab’s site.
Tuning in to the Stars
Another team pointed the Summit supercomputer at the stars in preparation for one of the biggest big-data projects ever tackled. They created a workflow that handled six hours of simulated output from the Square Kilometer Array (SKA), a network of thousands of radio telescopes expected to come online later this decade.
Researchers from Australia, China and the U.S. analyzed 2.6 petabytes of data on Summit to provide a proof of concept for one of SKA’s key use cases. In the process they revealed critical design factors for future radio telescopes and the supercomputers that study their output.
The team’s work generated 247 GBytes/second of data and spawned 925 GBytes/s in I/O. Like many other finalists, they relied on the fast, low-latency InfiniBand links powered by NVIDIA Mellanox networking, widely used in supercomputers like Summit to speed data among thousands of computing nodes.
Simulating the Coronavirus with HPC+AI
The four teams stand beside three other finalists who used NVIDIA technologies in a competition for a special Gordon Bell Prize for COVID-19.
The winner of that award used all the GPUs on Summit to create the largest, longest and most accurate simulation of a coronavirus to date.
“It was a total game changer for seeing the subtle protein motions that are often the important ones, that’s why we started to run all our simulations on GPUs,” said Lilian Chong, an associate professor of chemistry at the University of Pittsburgh, one of 27 researchers on the team.
“It’s no exaggeration to say what took us literally five years to do with the flu virus, we are now able to do in a few months,” said Rommie Amaro, a researcher at the University of California at San Diego who led the AI-assisted simulation.
]]>Research across global academic and commercial labs to create a more efficient drug discovery process won recognition today with a special Gordon Bell Prize for work fighting COVID-19.
A team of 27 researchers led by Rommie Amaro at the University of California at San Diego (UCSD) combined high performance computing (HPC) and AI to provide the clearest view to date of the coronavirus, winning the award.
Their work began in late March when Amaro lit up Twitter with a picture of part of a simulated SARS-CoV-2 virus that looked like an upside-down Christmas tree.
Seeing it, one remote researcher noticed how a protein seemed to reach like a crooked finger from behind a protective shield to touch a healthy human cell.
“I said, ‘holy crap, that’s crazy’… only through sharing a simulation like this with the community could you see for the first time how the virus can only strike when it’s in an open position,” said Amaro, who leads a team of biochemists and computer experts at UCSD.
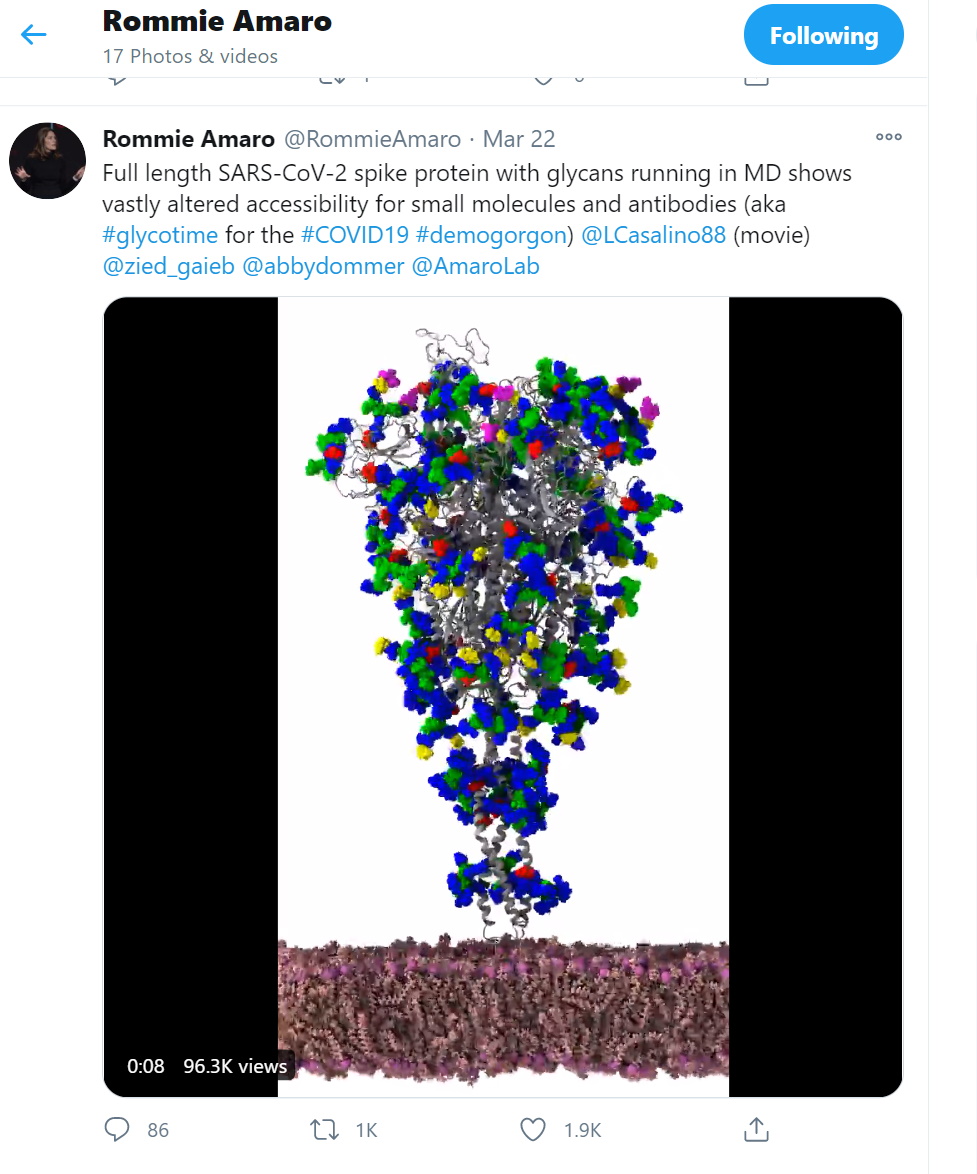
The image in the tweet was taken by Amaro’s lab using what some call a computational microscope, a digital tool that links the power of HPC simulations with AI to see details beyond the capabilities of conventional instruments.
It’s one example of work around the world using AI and data analytics, accelerated by NVIDIA Clara Discovery, to slash the $2 billion in costs and ten-year time span it typically takes to bring a new drug to market.
A Virtual Microscope Enhanced with AI
In early October, Amaro’s team completed a series of more ambitious HPC+AI simulations. They showed for the first time fine details of how the spike protein moved, opened and contacted a healthy cell.
One simulation (below) packed a whopping 305 million atoms, more than twice the size of any prior simulation in molecular dynamics. It required AI and all 27,648 NVIDIA GPUs on the Summit supercomputer at Oak Ridge National Laboratory.
More than 4,000 researchers worldwide have downloaded the results that one called “critical for vaccine design” for COVID and future pathogens.
Today, it won a special Gordon Bell Prize for COVID-19, the equivalent of a Nobel Prize in the supercomputing community.
Two other teams also used NVIDIA technologies in work selected as finalists in the COVID-19 competition created by the ACM, a professional group representing more than 100,000 computing experts worldwide.
And the traditional Gordon Bell Prize went to a team from Beijing, Berkeley and Princeton that set a new milestone in molecular dynamics, also using a combination of HPC+AI on Summit.
An AI Funnel Catches Promising Drugs
Seeing how the infection process works is one of a string of pearls that scientists around the world are gathering into a new AI-assisted drug discovery process.
Another is screening from a vast field of 1068 candidates the right compounds to arrest a virus. In a paper from part of the team behind Amaro’s work, researchers described a new AI workflow that in less than five months filtered 4.2 billion compounds down to the 40 most promising ones that are now in advanced testing.
“We were so happy to get these results because people are dying and we need to address that with a new baseline that shows what you can get with AI,” said Arvind Ramanathan, a computational biologist at Argonne National Laboratory.
Ramanathan’s team was part of an international collaboration among eight universities and supercomputer centers, each contributing unique tools to process nearly 60 terabytes of data from 21 open datasets. It fueled a set of interlocking simulations and AI predictions that ran across 160 NVIDIA A100 Tensor Core GPUs on Argonne’s Theta system with massive AI inference runs using NVIDIA TensorRT on the many more GPUs on Summit.
Docking Compounds, Proteins on a Supercomputer
Earlier this year, Ada Sedova put a pearl on the string for protein docking (described in the video below) when she described plans to test a billion drug compounds against two coronavirus spike proteins in less than 24 hours using the GPUs on Summit. Her team’s work cut to just 21 hours the work that used to take 51 days, a 58x speedup.
In a related effort, colleagues at Oak Ridge used NVIDIA RAPIDS and BlazingSQL to accelerate by an order of magnitude data analytics on results like Sedova produced.
Among the other Gordon Bell finalists, Lawrence Livermore researchers used GPUs on the Sierra supercomputer to slash the training time for an AI model used to speed drug discovery from a day to just 23 minutes.
From the Lab to the Clinic
The Gordon Bell finalists are among more than 90 research efforts in a supercomputing collaboration using 50,000 GPU cores to fight the coronavirus.
They make up one front in a global war on COVID that also includes companies such as Oxford Nanopore Technologies, a genomics specialist using NVIDIA’s CUDA software to accelerate its work.
Oxford Nanopore won approval from European regulators last month for a novel system the size of a desktop printer that can be used with minimal training to perform thousands of COVID tests in a single day. Scientists worldwide have used its handheld sequencing devices to understand the transmission of the virus.
Relay Therapeutics uses NVIDIA GPUs and software to simulate with machine learning how proteins move, opening up new directions in the drug discovery process. In September, it started its first human trial of a molecule inhibitor to treat cancer.
Startup Structura uses CUDA on NVIDIA GPUs to analyze initial images of pathogens to quickly determine their 3D atomic structure, another key step in drug discovery. It’s a member of the NVIDIA Inception program, which gives startups in AI access to the latest GPU-accelerated technologies and market partners.
From Clara Discovery to Cambridge-1
NVIDIA Clara Discovery delivers a framework with AI models, GPU-optimized code and applications to accelerate every stage in the drug discovery pipeline. It provides speedups of 6-30x across jobs in genomics, protein structure prediction, virtual screening, docking, molecular simulation, imaging and natural-language processing that are all part of the drug discovery process.
It’s NVIDIA’s latest contribution to fighting the SARS-CoV-2 and future pathogens.
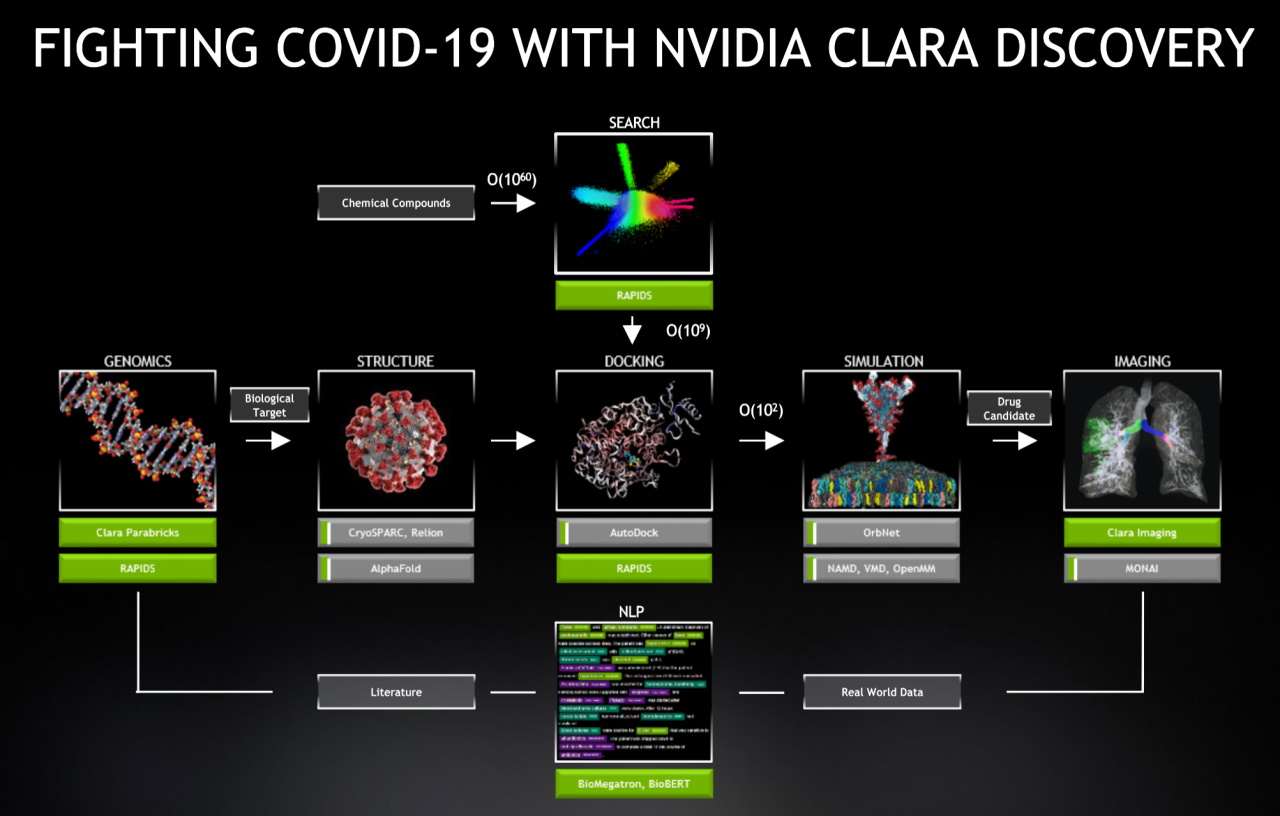
Within hours of the shelter-at-home order in the U.S., NVIDIA gave researchers free access to a test drive of Parabricks, our genomic sequencing software. Since then, we’ve provided as part of NVIDIA Clara open access to AI models co-developed with the U.S. National Institutes of Health.
We’ve also committed to build with partners including GSK and AstraZeneca Europe’s largest supercomputer dedicated to driving drug discovery forward. Cambridge-1 will be an NVIDIA DGX SuperPOD system capable of delivering more than 400 petaflops of AI performance.
Next Up: A Billion-Atom Simulation
The work is just getting started.
Ramanathan of Argonne sees a future where self-driving labs learn what experiments they should launch next, like autonomous vehicles finding their own way forward.
“And I want to scale to the absolute max of screening 1068 drug compounds, but even covering half that will be significantly harder than what we’ve done so far,” he said.
“For me, simulating a virus with a billion atoms is the next peak, and we know we will get there in 2021,” said Amaro. “Longer term, we need to learn how to use AI even more effectively to deal with coronavirus mutations and other emerging pathogens that could be even worse,” she added.
Hear NVIDIA CEO Jensen Huang describe in the video below how AI in Clara Discovery is advancing drug discovery.
At top: An image of the SARS-CoV-2 virus based on the Amaro lab’s simulation showing 305 million atoms.
]]>Using AI and a supercomputer simulation, Ken Dill’s team drew the equivalent of wanted posters for a gang of proteins that make up COVID-19. With a little luck, one of their portraits could identify a way to arrest the coronavirus with a drug.
When the pandemic hit, “it was terrible for the world, and a big research challenge for us,” said Dill, who leads the Laufer Center for Physical & Quantitative Biology at Stony Brook University, in Long Island, New York.
For a decade, he helped the center assemble the researchers and tools needed to study the inner workings of proteins — complex molecules that are fundamental to cellular life. The center has a history of applying its knowledge to viral proteins, helping others identify drugs to disable them.
“So, when the pandemic came, our folks wanted to spring into action,” he said.
AI, Simulations Meet at the Summit
The team aimed to use a combination of physics and AI tools to predict the 3D structure of more than a dozen coronavirus proteins based on lists of the amino acid strings that define them. It won a grant for time on the IBM-built Summit supercomputer at Oak Ridge National Laboratory to crunch its complex calculations.
“We ran 30 very extensive simulations in parallel, one on each of 30 GPUs, and we ran them continuously for at least four days,” explained Emiliano Brini, a junior fellow at the Laufer Center. “Summit is a great machine because it has so many GPUs, so we can run many simulations in parallel,” he said.
“Our physics-based modeling eats a lot of compute cycles. We use GPUs almost exclusively for their speed,” said Dill.
Sharing Results to Help Accelerate Research
Thanks to the acceleration, the predictions are already in. The Laufer team quickly shared them with about a hundred researchers working on a dozen separate projects that conduct painstakingly slow experiments to determine the actual structure of the proteins.
“They indicated some experiments could be done faster if they had hunches from our work of what those 3D structures might be,” said Dill.
Now it’s a waiting game. If one of the predictions gives researchers a leg up in finding a weakness that drug makers can exploit, it would be a huge win. It could take science one step closer to putting a general antiviral drug on the shelf of your local pharmacy.
Melding Machine Learning and Physics
Dill’s team uses a molecular dynamics program called MELD. It blends physical simulations with insights from machine learning based on statistical models.
AI provides MELD key information to predict a protein’s 3D structure from its sequence of amino acids. It quickly finds patterns across a database of atomic-level information on 200,000 proteins gathered over the last 50 years.
MELD uses this information in compute-intensive physics simulations to determine the protein’s detailed structure. Further simulations then can predict, for example, what drug molecules will bind tightly to a specific viral protein.
“So, both these worlds — AI inference and physics simulations — are playing big roles in helping drug discovery,” said Dill. “We get the benefits of both methods, and that combination is where I think the future is.”
MELD runs on CUDA, NVIDIA’s accelerated computing platform for GPUs. “It would take prohibitively long to run its simulations on CPUs, so the majority of biological simulations are done on GPUs,” said Brini.
Playing a Waiting Game
The COVID-19 challenge gave Laufer researchers with a passion for chemistry a driving focus. Now they await feedback on their work on Summit.
“Once we get the results, we’ll publish what we learn from the mistakes. Many times, researchers have to go back to the drawing board,” he said.
And every once in a while, they celebrate, too.
Dill hosted a small, socially distanced gathering for a half-dozen colleagues in his backyard after the Summit work was complete. If those results turn up a win, there will be a much bigger celebration extending far beyond the Stony Brook campus.
]]>Eliu Huerta is harnessing AI and high performance computing (HPC) to observe the cosmos more clearly.
For several years, the astrophysics researcher has been chipping away at a grand challenge, using data to detect signals produced by collisions of black holes and neutron stars. If his next big design for a neural network is successful, astrophysicists will use it to find more black holes and study them in more detail than ever.
Such insights could help answer fundamental questions about the universe. They may even add a few new pages to the physics textbook.
Huerta studies gravitational waves, the echoes from dense stellar remnants that collided long ago and far away. Since Albert Einstein first predicted them in his theory of relativity, academics debated whether these ripples in the space-time fabric really exist.
Researchers ended the debate in 2015 when they observed gravitational waves for the first time. They used pattern-matching techniques on data from the Laser Interferometer Gravitational-Wave Observatory (LIGO), home to some of the most sensitive instruments in science.
Detecting Black Holes Faster with AI
Confirming the presence of just one collision took a supercomputer to process data the instruments could gather in a single day. In 2017, Huerta’s team showed how a deep neural network running on an NVIDIA GPU could find gravitational waves with the same accuracy in a fraction of the time.
“We were orders of magnitude faster and we could even see signals the traditional techniques missed and we did not train our neural net for,” said Huerta, who leads AI and gravity groups at the National Center for Supercomputing Applications at the University of Illinois, Urbana-Champaign.
The AI model Huerta used was based on data from tens of thousands of waveforms. He trained it on a single NVIDIA GPU in less than three hours.
Seeing in Detail How Black Holes Spin
This year, Huerta and two of his students created a more sophisticated neural network that can detect how two colliding black holes spin. Their AI model even accurately measured the faint signals of a small black hole when it was merging with a larger one.
It required data on 1.5 million waveforms. An IBM POWER9-based system with 64 NVIDIA V100 Tensor Core GPUs took 12 hours to train the resulting neural network.
To accelerate their work, Huerta’s team got access to 1,536 V100 GPUs on 256 nodes of the IBM AC922 Summit supercomputer at Oak Ridge National Laboratory.
Taking advantage of NVIDIA NVLink, a connection between Summit’s GPUs and its IBM POWER9 CPUs, they trained the AI model in just 1.2 hours.
The results, described in a paper in Physics Letters B, “show how the combination of AI and HPC can solve grand challenges in astrophysics,” he said.
Interestingly, the team’s work is based on WaveNet, a popular AI model for converting text-to-speech. It’s one of many examples of how AI technology that’s rapidly evolving in consumer and enterprise use cases is crossing over to serve the needs of cutting-edge science.
The Next Big Leap into Black Holes
So far, Huerta has used data from supercomputer simulations to detect and describe the primary characteristics of gravitational waves. Over the next year, he aims to use actual LIGO data to capture the more nuanced secondary characteristics of gravitational waves.
“It’s time to go beyond low-hanging fruit and show the combination of HPC and AI can address production-scale problems in astrophysics that neither approach can accomplish separately,” he said.
The new details could help scientists determine more accurately where black holes collided. Such information could help them more accurately calculate the Hubble constant, a measure of how fast the universe is expanding.
The work may require tracking as many as 200 million waveforms, generating training datasets 100x larger than Huerta’s team used so far. The good news is, as part of their July paper, they’ve already determined their algorithms can scale to at least 1,024 nodes on Summit.
Tallying Up the Promise of HPC+AI
Huerta believes he’s just scratching the surface of the promise of HPC+AI. “The datasets will continue to grow, so to run production algorithms you need to go big, there’s no way around that,” he said.
Meanwhile, use of AI is expanding to adjacent areas. The team used neural nets to classify the many, many galaxies found in electromagnetic surveys of the sky, work NVIDIA CEO Jensen Huang highlighted in his GTC keynote in May.
Separately, one of Huerta’s grad students used AI to describe the turbulence when neutron stars merge more efficiently than previous techniques. “It’s another place where we can go into the traditional software stack scientists use and replace an existing model with an accelerated neural network,” Huerta said.
To accelerate the adoption of its work, the team has released as open source code its AI models for cosmology and gravitational wave astrophysics.
“When people read these papers they may think it’s too good to be true, so we let them convince themselves that we are getting the results we reported,” he said.
The Road to Space Started at Home
As is often the case with landmark achievements, there’s a parent to thank.
“My dad was an avid reader. We spent lots of time together doing math and reading books on a wide range of topics,” Huerta recalled.
“When I was 13, he brought home The Meaning of Relativity by Einstein. It was way over my head, but a really interesting read.
“A year or so later he bought A Brief History of Time by Stephen Hawking. I read it and thought it would be great to go to Cambridge and learn about gravity. Years later that actually happened,” he said.
The rest is a history that Huerta is still writing.
For more on Huerta’s work, check on an article from Oak Ridge National Laboratory.
At top: An artist’s impression of gravitational waves generated by binary neutron stars. Credit: R. Hurt, Caltech/NASA Jet Propulsion Lab
]]>Ahmed Elnaggar and Michael Heinzinger are helping computers read proteins as easily as you read this sentence.
The researchers are applying the latest AI models used to understand text to the field of bioinformatics. Their work could accelerate efforts to characterize living organisms like the coronavirus.
By the end of the year, they aim to launch a website where researchers can plug in a string of amino acids that describe a protein. Within seconds, it will provide some details of the protein’s 3D structure, a key to knowing how to treat it with a drug.
Today, researchers typically search databases to get this kind of information. But the databases are growing rapidly as more proteins are sequenced, so a search can take up to 100 times longer than the approach using AI, depending on the size of a protein’s amino acid string.
In cases where a particular protein hasn’t been seen before, a database search won’t provide any useful results — but AI can.
“Twelve of the 14 proteins associated with COVID-19 are similar to well validated proteins, but for the remaining two we have very little data — for such cases, our approach could help a lot,” said Heinzinger, a Ph.D. candidate in computational biology and bioinformatics.
While time consuming, methods based on the database searches have been 7-8 percent more accurate than previous AI methods. But using the latest models and datasets, Elnaggar and Heinzinger cut the accuracy gap in half, paving the way for a shift to using AI.
AI Models, GPUs Drive Biology Insights
“The speed at which these AI algorithms are improving makes me optimistic we can close this accuracy gap, and no field has such fast growth in datasets as computational biology, so combining these two things I think we will reach a new state of the art soon,” said Heinzinger.
“This work couldn’t have been done two years ago,” said Elnaggar, an AI specialist with a Ph.D. in transfer learning. “Without the combination of today’s bioinformatics data, new AI algorithms and the computing power from NVIDIA GPUs, it couldn’t be done,” he said.
Elnaggar and Heinzinger are team members in the Rostlab at the Technical University of Munich, which helped pioneer this field at the intersection of AI and biology. Burkhard Rost, who heads the lab, wrote a seminal paper in 1993 that set the direction.
The Semantics of Reading a Protein
The underlying concept is straightforward. Proteins, the building blocks of life, are made up of strings of amino acids that need to be interpreted sequentially, just like words in a sentence.
So, researchers like Rost started applied emerging work in natural-language processing to understand proteins. But in the 1990s they had very little data on proteins and the AI models were still fairly crude.
Fast forward to today and a lot has changed.
Sequencing has become relatively fast and cheap, generating massive datasets. And thanks to modern GPUs, advanced AI models such as BERT can interpret language in some cases better than humans.
AI Models Grow 6x in Sophistication
The breakthroughs in natural-language processing have been particularly breathtaking. Just 18 months ago, Elnaggar and Heinzinger reported on work using a version of recurrent neural network models with 90 million parameters; this month their work leveraged Transformer models with 567 million parameters.
“Transformer models are hungry for compute power, so to do this work we used 5,616 GPUs on the Summit supercomputer and even then it took up to two days to train some of the models,” said Elnaggar.
Running the models on thousands of Summit’s nodes presented challenges.
Elnaggar tells a story familiar to those who work on supercomputers. He needed lots of patience to sync and manage files, storage, comms and their overheads at such a scale. He started small, working on a few nodes, and moved a step at a time.

“The good news is we can now use our trained models to handle inference work in the lab using a single GPU,” he said.
Now Available: Pretrained AI Models
Their latest paper, published in July, characterizes the pros and cons of a handful of the latest AI models they used on various tasks. The work is funded with a grant from the COVID-19 High Performance Computing Consortium.
The duo also published the first versions of their pretrained models. “Given the pandemic, it’s better to have an early release,” rather than wait until the still ongoing project is completed, Elnaggar said.
“The proposed approach has the potential to revolutionize the way we analyze protein sequences,” said Heinzinger.
The work may not in itself bring the coronavirus down, but it is likely to establish a new and more efficient research platform to attack future viruses.
Collaborating Across Two Disciplines
The project highlights two of the soft lessons of science: Keep a keen eye on the horizon and share what’s working.
“Our progress mainly comes from advances in natural-language processing that we apply to our domain — why not take a good idea and apply it to something useful,” said Heinzinger, the computational biologist.
Elnaggar, the AI specialist, agreed. “We could only succeed because of this collaboration across different fields,” he said.
See more stories online of researchers advancing science to fight COVID-19 and stay up to date with the latest healthcare news from NVIDIA.
The image at top shows language models trained without labelled samples picking up the signal of a protein sequence that is required for DNA binding.
]]>Anshuman Kumar is sharpening a digital pencil to penetrate the secrets of the coronavirus.
He and colleagues at the University of California at Riverside want to calculate atomic interactions at a scale never before attempted for the virus. If they succeed, they’ll get a glimpse into how a molecule on the virus binds to a molecule of a drug, preventing it from infecting healthy cells.
Kumar is part of a team at UCR taking work in the tiny world of quantum mechanics to a new level. They aim to measure a so-called barrier height, a measure of the energy required to interact with a viral protein that consists of about 5,000 atoms.
That’s more than 10x the state of the art in the field, which to date has calculated forces of molecules with up to a few hundred atoms.
Accelerating Anti-COVID Drug Discovery
Data on how quantum forces determine the likelihood a virus will bind with a neutralizing molecule, called a ligand, could speed work at pharmaceutical companies seeking drugs to prevent COVID-19.
“At the atomic level, Newtonian forces become irrelevant, so you have to use quantum mechanics because that’s the way nature works,” said Bryan Wong, an associate professor of chemical engineering, materials science and physics at UCR who oversees the project. “We aim to make these calculations fast and efficient with NVIDIA GPUs in Microsoft’s Azure cloud to narrow down our path to a solution.”
Researchers started their work in late April using a protein on the coronavirus believed to play a strong role in rapidly infecting healthy cells. They’re now finishing up a series of preliminary calculations that take up to 10 days each.
The next step, discovering the barrier height, involves even more complex and time-consuming calculations. They could take as long as five weeks for a single protein/ligand pair.
Calling on GPUs in the Azure Cloud
To accelerate time to results, the team got a grant from Microsoft’s AI for Health program through the COVID-19 High Performance Computing Consortium. It included high performance computing on Microsoft’s Azure cloud and assistance from NVIDIA.
Kumar implemented a GPU-accelerated version of the scientific program that handles the quantum calculations. It already runs on the university’s NVIDIA GPU-powered cluster on premises, but the team wanted to move it to the cloud where it could run on V100 Tensor Core GPUs.
In less than a day, Kumar was able to migrate the program to Azure with help from NVIDIA solutions architect Scott McMillan using HPC Container Maker, an open source tool created and maintained by NVIDIA. The tool lets users define a container with a few clicks that identify a program and its key components such as a runtime environment and other dependencies.

It was a big move given the researchers had never used containers or cloud services before.
“The process is very smooth once you identify the correct libraries and dependencies — you just write a script and build the code image,” said Kumar. “After doing this, we got 2-10x speedups on GPUs on Azure compared to our local system,” he added.
NVIDIA helped fine-tune the performance by making sure the code used the latest versions of CUDA and the Magma math library. One specialist dug deep in the stack to update a routine that enabled multi-GPU scaling.
New Teammates and a Mascot
The team got some unexpected help recently when it discovered a separate computational biology lab at UCR also won a grant from the HPC consortium to work on COVID. The lab observes the binding process using statistical sampling techniques to make bindings that are otherwise rare occur more often.
“I reached out to them because pairing up makes for a better project,” said Wong. “They can use the GPU code Anshuman implemented for their enhanced sampling work,” he added.
“I’m really proud to be part of this work because it could help the whole world,” said Kumar.
The team also recently got a mascot. A large squirrel, dubbed Billy, now sits daily outside the window of Wong’s home office, a good symbol for the group’s aim to be fast and agile.
Stay up to date with the latest healthcare news from NVIDIA.
Pictured above: Colorful ribbons represent the Mpro protein believed to have an important role in the replication of the coronavirus. Red strands represent a biological molecule that binds to a ligand. (Image courtesy of UCR.)
]]>Working from home, sometimes in pajamas, Ada Sedova taps into the world’s most powerful supercomputer in the hunt for a tiny molecule that could stop the coronavirus from infecting someone with COVID-19.
“I’m getting more done than ever, and with all the anxiety around the pandemic, I’m devoting a lot of my personal time to this effort,” said Sedova, a biophysics researcher at the Oak Ridge National Laboratory.
Her efforts could bring a 10-figure payday — specifically 2 billion molecular tests executed in just 24 hours.
Sedova seeks a ligand, an organic molecule less than a few dozen atoms in size. The right ligand will attach itself to a protein from the coronavirus, preventing it from infecting healthy cells.
The problem is there are so many ligands and proteins to check, and they keep changing shapes as their atomic forces shift. It’s one heck of a tiny needle in a ginormous stack of billions of possible compounds.
It could take many years for experts in wet labs to try each of the possibilities. Even simulating them all on the 9,216 CPUs on Summit, ORNL’s supercomputer, could take four years. So Sedova and colleagues turned to Summit’s 27,648 NVIDIA GPUs to accelerate their efforts.
They started using the OpenCL version of AutoDock, an open source program for simulating how proteins and ligands bind that was developed at Scripps Research in collaboration with TU Darmstadt. The OpenCL version on GPUs improved the processing speed by 50x compared to CPUs.
CUDA Cuts to the Chase
With help from NVIDIA and Scripps Research, the team ported the code to CUDA so it could run on Summit, delivering an added benefit of another 2.8x speedup. Another researcher, Aaron Scheinberg of Jubilee Development, accelerated the work another 3x when he found a way to use OpenMP to speed up feeding data to the GPUs.
In another test, Sedova showed results that suggest they may be able to screen a dataset of 1.4 billion compounds against a protein with high accuracy in as little as 12 hours. That’s more than a 33x speedup compared to a program running on CPUs.
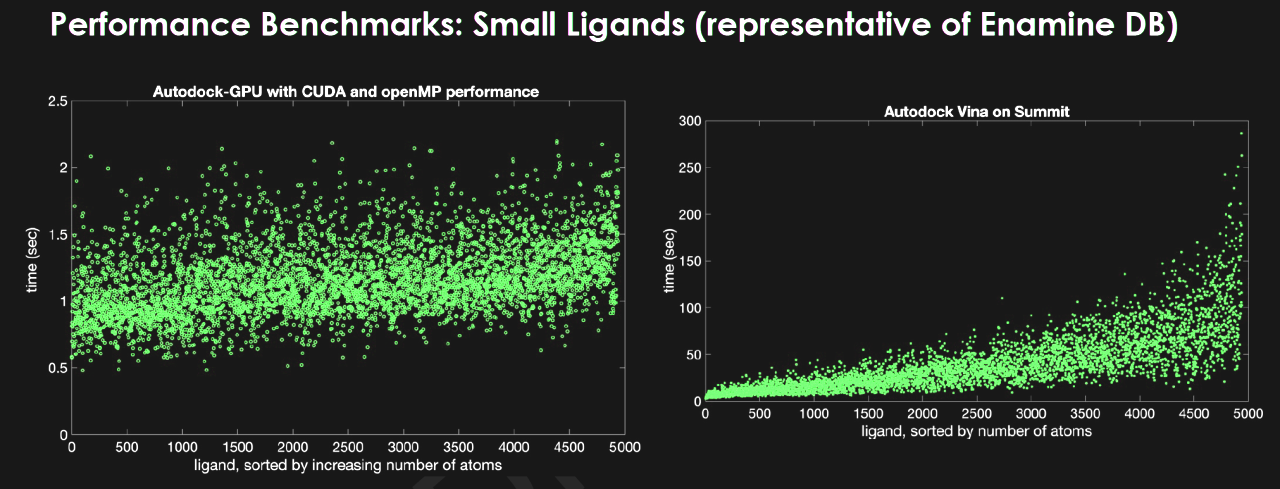
“GPUs combined with Summit’s scale and architecture provide the capability for docking billions more compounds than what was possible previously,” she said.
Another member of the team, biophysicist Josh Vermaas, gave a shout-out to NVIDIA’s Scott Le Grand, who helped port AutoDock to CUDA. “He’s been a phenomenal help in improving performance from what used to be an OpenCL-only code,” said Vermaas in a blog on the origins of the work.
Simulating 2 Billion Compounds in 24 Hours
Sedova now believes with further improvements the team could create a capability to examine as many as 2 billion compounds in 24 hours. It would mark the first simulation of that size at high resolution.
Researchers still face a few challenges getting to that milestone.
The standard workflow for protein-ligand docking uses a sluggish file-based process. It’s fine for tests of a few hundred compounds on a laptop, but at the scale of hundreds of thousands of files it could bog down even the world’s largest supercomputer.
That’s a call to action for open source developers who want to help accelerate science.
Sedova’s team is leading the charge, assembling a new workflow that promises to securely launch vast numbers of jobs on Summit. She’s consulting with the system’s I/O experts and trying to spin up a database to hold all the ligands.
The next step is launching an experiment with about 1 million compounds on 108 of Summit’s 4,608 nodes. “If it works, we’ll launch the big run with 1.4 billion compounds using all of Summit’s nodes,” she said.
Narrowing the Search for Promising Molecules
If the team succeeds, they’ll send researchers in Memphis a list of about 9,000 of the most promising compounds to test in their wet lab with the real virus. It’s not the needle in the haystack, but it’s a needle in a shovel of hay.
The work got its start in January when a top ORNL researcher, Jeremy C. Smith, showed the first work using the Summit supercomputer for drug research to fight the coronavirus. The work is still in its early days.
Looking ahead, Sedova has ideas for other ways to bridge the field of protein-ligand binding into the typical methods used in high performance computing. And she has plenty of energy for pursuing them, too.
Learn about more efforts using GPUs to fight the coronavirus on NVIDIA’s COVID-19 page.
]]>What you can see, you can understand.
Simulations help us understand the mysteries of black holes and see how a protein spike on the coronavirus causes COVID-19. They also let designers create everything from sleek cars to jet engines.
But simulations are also among the most demanding computer applications on the planet because they require lots of the most advanced math.
Simulations make numeric models visual with calculations that use a double-precision floating-point format called FP64. Each number in the format takes up 64 bits inside a computer, making it one the most computationally intensive of the many math formats today’s GPUs support.
As the next big step in our efforts to accelerate high performance computing, the NVIDIA Ampere architecture defines third-generation Tensor Cores that accelerate FP64 math by 2.5x compared to last-generation GPUs.
That means simulations that kept researchers and designers waiting overnight can be viewed in a few hours when run on the latest A100 GPUs.
Science Puts AI in the Loop
The speed gains open a door for combining AI with simulations and experiments, creating a positive-feedback loop that saves time.
First, a simulation creates a dataset that trains an AI model. Then the AI and simulation models run together, feeding off each other’s strengths until the AI model is ready to deliver real-time results through inference. The trained AI model also can take in data from an experiment or sensor, further refining its insights.
Using this technique, AI can define a few areas of interest for conducting high-resolution simulations. By narrowing the field, AI can slash by orders of magnitude the need for thousands of time-consuming simulations. And the simulations that need to be run will run 2.5x faster on an A100 GPU.
With FP64 and other new features, the A100 GPUs based on the NVIDIA Ampere architecture become a flexible platform for simulations, as well as AI inference and training — the entire workflow for modern HPC. That capability will drive developers to migrate simulation codes to the A100.
Users can call new CUDA-X libraries to access FP64 acceleration in the A100. Under the hood, these GPUs are packed with third-generation Tensor Cores that support DMMA, a new mode that accelerates double-precision matrix multiply-accumulate operations.
Accelerating Matrix Math
A single DMMA job uses one computer instruction to replace eight traditional FP64 instructions. As a result, the A100 crunches FP64 math faster than other chips with less work, saving not only time and power but precious memory and I/O bandwidth as well.
We refer to this new capability as Double-Precision Tensor Cores. It delivers the power of Tensor Cores to HPC applications, accelerating matrix math in full FP64 precision.
Beyond simulations, HPC apps called iterative solvers — algorithms with repetitive matrix-math calculations — will benefit from this new capability. These apps include a wide range of jobs in earth science, fluid dynamics, healthcare, material science and nuclear energy as well as oil and gas exploration.
To serve the world’s most demanding applications, Double-Precision Tensor Cores arrive inside the largest and most powerful GPU we’ve ever made. The A100 also packs more memory and bandwidth than any GPU on the planet.
The third-generation Tensor Cores in the NVIDIA Ampere architecture are beefier than prior versions. They support a larger matrix size — 8x8x4, compared to 4x4x4 for Volta — that lets users tackle tougher problems.
That’s one reason why an A100 with a total of 432 Tensor Cores delivers up to 19.5 FP64 TFLOPS, more than double the performance of a Volta V100.
Where to Go to Learn More
To get the big picture on the role of FP64 in our latest GPUs, watch the keynote with NVIDIA founder and CEO Jensen Huang. To learn more, register for the webinar or read a detailed article that takes a deep dive into the NVIDIA Ampere architecture.
Double-Precision Tensor Cores are among a battery of new capabilities in the NVIDIA Ampere architecture, driving HPC performance as well as AI training and inference to new heights. For more details, check out our blogs on:
]]>Days before a national lockdown in the U.S., Daniel McDonald realized his life’s work had put a unique tool in his hands to fight COVID-19.
The assay kits his team was about to have made by the tens of thousands could be repurposed to help understand the novel coronavirus that causes the disease.
McDonald is scientific director of the American Gut Project and the Microsetta Initiative, part of an emerging field that studies microbiomes, the collections of single-cell creatures that make up much if not most of life in and around us. The assay kits were the first to be able to safely take and ship samples from human feces preserved at room temperature.
The kits originally targeted broad research in microbiology. But McDonald and his colleagues knew they needed to pivot into the pandemic.
With careful screening, samples might reveal patterns of how the mutating coronavirus was spreading. That information would be gold for public health experts trying to slow the growth of new infections.
The team also hopes to gather just enough data from participants to let researchers explore another mystery: Why does the virus make some people very sick while others show no symptoms at all?
“Everybody here is absolutely excited about doing something that could help save lives,” said McDonald, part of the 50-person team in Rob Knight’s lab at the University of California, San Diego.
“We are lucky to work close and collaborate with experts in RNA and other areas applicable for studying this virus,” he added.
Hitting the Accelerator at the Right Time
As the kits were taking shape, the group had another stroke of good fortune.
Igor Sfiligoi, lead scientific software developer at the San Diego Supercomputer Center, ported to NVIDIA GPUs the latest version of the team’s performance-hungry UniFrac software, which is used to analyze microbiomes. The results were stunning.
A genetic analysis of 113,000 samples that would have required 1,300 CPU core-hours on a cluster of servers (or about 900 hours on a single CPU) finished in less than two hours on a single NVIDIA V100 Tensor Core GPU – a 500x speedup. A cluster of eight V100 GPUs would cut that to less than 15 minutes.
The port also enabled individual researchers to run the analysis in nine hours on a workstation equipped with an NVIDIA GeForce RTX 2080 Ti. And a smaller dataset that takes 13 hours on a server CPU now runs in just over one hour on a laptop with an NVIDIA GTX 1050 GPU.
“That’s game changing for people who don’t have access to high-performance computers,” said McDonald. For example, individual researchers may be able to use UniFrac as a kind of search tool for ad hoc queries, he said.
With the lab’s cluster of six V100 GPUs, it also can begin to tackle analysis of its expanding datasets.
Sfiligoi’s work on 113,000 samples “arguably represents the largest assessment of microbial life to date,” McDonald said. But the lab already has a repository of about 300,000 public samples and “it won’t be much longer before we’re well in excess of a million samples,” he added.
GPUs Speed Up UniFrac Three Ways
Three techniques were key to the speedups. OpenACC accelerated the many tight loops in the Striped UniFrac code, then Sfiligoi applied memory optimizations. Downshifting from 64-bit to 32-bit floating-point math delivered additional speedups without affecting the accuracy the experiments needed.

Sfiligoi completed the initial OpenACC port in a matter of days. Other optimizations came in incremental steps over a few weeks as the team got a better understanding of UniFrac’s compute and memory-access needs.
The work came on the heels of landmark effort Sfiligoi described in a session at GTC Digital. He was part of a team that harnessed exascale performance from GPUs on public cloud services for research in astronomy.
NVIDIA is collaborating with Sfiligoi on his next task. He aims to integrate his GPU optimizations on UniFrac into the software microbiologists use daily.
Data Flood Would Swamp CPU-only Systems
Meanwhile, McDonald and his team need to adapt UniFrac to work with viral data. They also face heady challenges turning vast amounts of data they will generate into well organized and error-free datasets they can process.
On the tech front, the group needs lots of storage and compute performance. To analyze what could one day amount a million microbiomes could require 20 petabytes of storage and more than 100 million CPU cycles/year.
“I would love to see a lot of that pushed onto GPUs,” McDonald said.
The work has broad potential given how long the extended family of coronaviruses has been affecting both humans and farm animals.
“Everybody on the planet has felt these impacts on productivity in some way. Now we can start to understand how to better manage this family of viruses that have been with us a long time,” he added.
The efforts in San Diego are part of a broad network of research projects leveraging NVIDIA GPUs and high performance computing to fight COVID-19.
More than 30 supercomputing centers worldwide spanning centers in Asia, Australia, Europe and the United States are engaged in the effort. The COVID-19 High Performance Computing Consortium alone has more than 30 active projects with access to 420 petaflops of power that includes 41,000 GPUs.
Image at top: Rob Knight (left) and Daniel McDonald in the UCSD Knight Lab. Photo courtesy Erik Jepsen/UC San Diego Publications
]]>There are a few different ways to think about pi. As apple, pumpkin and key lime … or as the different ways to represent the mathematical constant of ℼ, 3.14159, or, in binary, a long line of ones and zeroes.
An irrational number, pi has decimal digits that go on forever without repeating. So when doing calculations with pi, both humans and computers must pick how many decimal digits to include before truncating or rounding the number.
In grade school, one might do the math by hand, stopping at 3.14. A high schooler’s graphing calculator might go to 10 decimal places — using a higher level of detail to express the same number. In computer science, that’s called precision. Rather than decimals, it’s usually measured in bits, or binary digits.
For complex scientific simulations, developers have long relied on high-precision math to understand events like the Big Bang or to predict the interaction of millions of atoms.
Having more bits or decimal places to represent each number gives scientists the flexibility to represent a larger range of values, with room for a fluctuating number of digits on either side of the decimal point during the course of a computation. With this range, they can run precise calculations for the largest galaxies and the smallest particles.
But the higher precision level a machine uses, the more computational resources, data transfer and memory storage it requires. It costs more and it consumes more power.
Since not every workload requires high precision, AI and HPC researchers can benefit by mixing and matching different levels of precision. NVIDIA Tensor Core GPUs support multi- and mixed-precision techniques, allowing developers to optimize computational resources and speed up the training of AI applications and those apps’ inferencing capabilities.
Difference Between Single-Precision, Double-Precision and Half-Precision Floating-Point Format
The IEEE Standard for Floating-Point Arithmetic is the common convention for representing numbers in binary on computers. In double-precision format, each number takes up 64 bits. Single-precision format uses 32 bits, while half-precision is just 16 bits.
To see how this works, let’s return to pi. In traditional scientific notation, pi is written as 3.14 x 100. But computers store that information in binary as a floating-point, a series of ones and zeroes that represent a number and its corresponding exponent, in this case 1.1001001 x 21.
In single-precision, 32-bit format, one bit is used to tell whether the number is positive or negative. Eight bits are reserved for the exponent, which (because it’s binary) is 2 raised to some power. The remaining 23 bits are used to represent the digits that make up the number, called the significand.
Double precision instead reserves 11 bits for the exponent and 52 bits for the significand, dramatically expanding the range and size of numbers it can represent. Half precision takes an even smaller slice of the pie, with just five for bits for the exponent and 10 for the significand.
Here’s what pi looks like at each precision level:

Difference Between Multi-Precision and Mixed-Precision Computing
Multi-precision computing means using processors that are capable of calculating at different precisions — using double precision when needed, and relying on half- or single-precision arithmetic for other parts of the application.
Mixed-precision, also known as transprecision, computing instead uses different precision levels within a single operation to achieve computational efficiency without sacrificing accuracy.
In mixed precision, calculations start with half-precision values for rapid matrix math. But as the numbers are computed, the machine stores the result at a higher precision. For instance, if multiplying two 16-bit matrices together, the answer is 32 bits in size.
With this method, by the time the application gets to the end of a calculation, the accumulated answers are comparable in accuracy to running the whole thing in double-precision arithmetic.
This technique can accelerate traditional double-precision applications by up to 25x, while shrinking the memory, runtime and power consumption required to run them. It can be used for AI and simulation HPC workloads.
As mixed-precision arithmetic grew in popularity for modern supercomputing applications, HPC luminary Jack Dongarra outlined a new benchmark, HPL-AI, to estimate the performance of supercomputers on mixed-precision calculations. When NVIDIA ran HPL-AI computations in a test run on Summit, the fastest supercomputer in the world, the system achieved unprecedented performance levels of nearly 550 petaflops, over 3x faster than its official performance on the TOP500 ranking of supercomputers.
How to Get Started with Mixed-Precision Computing
NVIDIA Volta and Turing GPUs feature Tensor Cores, which are built to simplify and accelerate multi- and mixed-precision computing. And with just a few lines of code, developers can enable the automatic mixed-precision feature in the TensorFlow, PyTorch and MXNet deep learning frameworks. The tool gives researchers speedups of up to 3x for AI training.
The NGC catalog of GPU-accelerated software also includes iterative refinement solver and cuTensor libraries that make it easy to deploy mixed-precision applications for HPC.
For more information, check out our developer resources on training with mixed precision.
What Is Mixed-Precision Used for?
Researchers and companies rely on the mixed-precision capabilities of NVIDIA GPUs to power scientific simulation, AI and natural language processing workloads. A few examples:
Earth Sciences
- Researchers from the University of Tokyo, Oak Ridge National Laboratory and the Swiss National Supercomputing Center used AI and mixed-precision techniques for earthquake simulation. Using a 3D simulation of the city of Tokyo, the scientists modeled how a seismic wave would impact hard soil, soft soil, above-ground buildings, underground malls and subway systems. They achieved a 25x speedup with their new model, which ran on the Summit supercomputer and used a combination of double-, single- and half-precision calculations.
- A Gordon Bell prize-winning team from Lawrence Berkeley National Laboratory used AI to identify extreme weather patterns from high-resolution climate simulations, helping scientists analyze how extreme weather is likely to change in the future. Using the mixed-precision capabilities of NVIDIA V100 Tensor Core GPUs on Summit, they achieved performance of 1.13 exaflops.
Medical Research and Healthcare
- San Francisco-based Fathom, a member of the NVIDIA Inception virtual accelerator program, is using mixed-precision computing on NVIDIA V100 Tensor Core GPUs to speed up training of its deep learning algorithms, which automate medical coding. The startup works with many of the largest medical coding operations in the U.S., turning doctors’ typed notes into alphanumeric codes that represent every diagnosis and procedure insurance providers and patients are billed for.
- Researchers at Oak Ridge National Laboratory were awarded the Gordon Bell prize for their groundbreaking work on opioid addiction, which leveraged mixed-precision techniques to achieve a peak throughput of 2.31 exaops. The research analyzes genetic variations within a population, identifying gene patterns that contribute to complex traits.
Nuclear Energy
- Nuclear fusion reactions are highly unstable and tricky for scientists to sustain for more than a few seconds. Another team at Oak Ridge is simulating these reactions to give physicists more information about the variables at play within the reactor. Using mixed-precision capabilities of Tensor Core GPUs, the team was able to accelerate their simulations by 3.5x.
Titan supercomputer, we salute you.
After seven years of groundbreaking service at Oak Ridge National Laboratory in Tennessee, the former fastest supercomputer in the U.S. is being decommissioned on Aug. 1.
First coming online in 2012, Titan achieved peak performance of 27 petaflops, made possible by its 18,000+ NVIDIA GPUs and NVIDIA’s CUDA software platform. It was supplanted last year by the Summit supercomputer, also located at ORNL, which provides 10x Titan’s simulation performance.
Prior to the invention of Summit, Titan’s speed and energy efficiency made it a “time machine,” according to Buddy Bland, project director at ORNL.
Below is a brief recap of its legacy of accelerating pioneering work in AI, simulation and modeling.
Simulation
Cleaning up waste is no fun. When it comes to the radioactive debris left over from the Manhattan Project, it’s also dangerous and nearly impossible. The difficulty of separating radioactive elements in order to safely store them presented unknown outcomes — until the emergence of Titan.
Scientists at ORNL used the supercomputer to simulate the effects of different decontamination methods on actinides — highly dangerous and radioactive elements such as uranium and plutonium — without wasting time and money on failed ventures.
The U.S. Department of Energy’s BioEnergy Science Center also took advantage of Titan to perform one of the most complex biomolecular simulations of ethanol. The result is a deeper understanding of lignin’s selective binding processes, which could eventually lead to a boost in biofuel yields.
And in 2013, Titan’s capacity for simulation made possible the efforts of four Gordon Bell Prize finalists. From simulating the behavior of 18,000 proteins for the first time, to the evolution of the universe, Titan was up for the challenge.
Modeling
Using Titan’s NVIDIA accelerators, General Electric scientists modeled water molecules on a variety of materials in an effort to build wind turbines that resist the formation of ice. This would render heaters — which immediately consume a portion of the energy produced by the turbines — obsolete. Success could mean more global electricity derived from wind power.
AI
Rather than training a neural network, MENNDL — the Multi-node Evolutionary Neural Networks for Deep Learning — creates the network itself. Developed by the ORNL team in 2017, MENNDL reduces the time necessary to develop neural networks for complex data sets from months to weeks. This is made possible through the acceleration provided by Titan’s 18,688 NVIDIA GPUs.
With Summit already accelerating research in everything from opiod addiction to supernova modeling, it’s standing on the shoulders of giants, or, more aptly, of the Titan.
]]>NVIDIA GPUs will power a next-generation supercomputer at Lawrence Berkeley National Laboratory, announced today by U.S. Energy Secretary Rick Perry and supercomputer manufacturer Cray.
Perlmutter, a pre-exascale system coming in 2020 to the DOE’s National Energy Research Scientific Computing Center (NERSC), will feature NVIDIA Tesla GPUs. The system is expected to deliver three times the computational power currently available on the Cori supercomputer at NERSC.
Tesla GPUs provide universal acceleration for scientific computing, AI and machine learning applications, reducing the time it takes to make groundbreaking discoveries. Research organizations large and small are recognizing this potential by turning to GPUs for next-generation supercomputers.
Optimized for science, the supercomputer will support NERSC’s community of more than 7,000 researchers. These scientists rely on high performance computing to build AI models, run complex simulations and perform data analytics. GPUs can speed up all three of these tasks.
Half of NERSC Workload Can Run on GPUs
Nearly half the workload running at NERSC is poised to take advantage of GPU acceleration, a recent NERSC study found. Between now and 2020, other applications that are algorithmically similar to GPU-accelerated kernels could also make the shift to GPU-ready code — enabling scientists to hit the ground running as soon as Perlmutter comes online.
“Perlmutter will be NERSC’s first large-scale GPU system, with a heterogeneous combination of CPU and GPU-accelerated nodes designed to maximize the productivity of our diverse mix of applications,” said Nick Wright, chief architect of the Perlmutter system. “While the adoption of GPUs will benefit many codes immediately, others will require more preparation. Our NESAP effort is devoted to working hand-in-hand with our partners at NVIDIA and Cray to accelerate as many codes as possible and make Perlmutter a success for all of our users.”
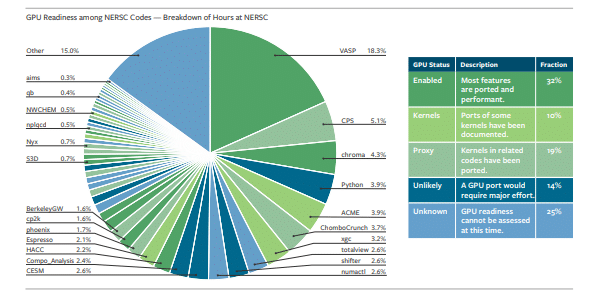
Bringing Scientists Faster Breakthroughs
The demand for GPU computing for science applications has skyrocketed over the past decade. And with RAPIDS, our new open-source libraries for GPU-accelerated data analytics, these speedups can be leveraged by more kinds of workloads than ever.
At NERSC, DOE labs and universities make up the lion’s share of HPC demand. These scientists process exabytes from sensors such as radio telescopes, particle accelerators, electron microscopes and more to answer the biggest questions in their research areas:
- Nuclear fusion: Nuclear fusion reactions, the processes that fuel stars, create huge amounts of energy. Scientists have been conducting these reactions in controlled environments for years, but haven’t yet been able to sustain a fusion reaction for long enough to leverage this clean power source. Supercomputers are used to simulate plasma behavior during fusion, helping researchers understand the complex dynamics at play.
- Climate and environment: Accurately forecasting climate at a global scale is key to understanding the long-term effect of carbon emissions on the planet. GPUs allow researchers to project decades of global climate data faster and at finer resolution.
- Materials science: Every material, natural or synthetic, has molecular properties that make it useful for some tasks over others. A high level of compute power lets researchers more quickly analyze molecular structures and discover new materials that have desired qualities such as flexibility, heat resistance or strength. These new materials can then be developed for everyday items like better car batteries or more comfortable contact lenses.
- Biological sciences: Taking a close look at molecular structure is also an essential component of drug discovery and vaccine development. Researchers with access to computational resources can anticipate how potential drug molecules might work to fight disease before testing physical samples in a lab. This helps narrow down the candidates for clinical testing, shrinking the time it takes to discover promising treatments.
With the GPU-accelerated speedups Perlmutter will offer, scientists will be able to iterate faster on these projects. They’ll gain the flexibility to ask more questions of their data, while spending less time waiting and more time inferring.
Main image for this story shows a materials science research simulation of indium nitride nanostructures for more efficient LEDs. Image credit: Burlen Loring, Berkeley Lab. Courtesy of NERSC.
]]>Movies have the Oscars. Television has the Emmys. Broadway has the Tonys.
But for those known for harnessing computing power more than star power, what counts is the Gordon Bell Prize.
Established more than three decades ago by the Association for Computing Machinery, the award recognizes outstanding achievement in the field of computing for applications in science, engineering and large-scale data science.
This year, five of the six prize finalists, who were just announced by ACM, did their work on the new NVIDIA GPU-accelerated Summit system at Oak Ridge National Laboratory and Sierra system at Lawrence Livermore National Laboratory. Summit is currently the world’s fastest supercomputer and Sierra is the third fastest, according to most recent Top500 list.
The Gordon Bell Prize winner will be announced Nov. 15 at the Supercomputing 2018 conference, in Dallas.
Summit, an open system for researchers worldwide, is designed to bring 200 petaflops of high-precision computing performance and over 3 exaflops of AI, powered by 27,648 NVIDIA Volta Tensor Core GPUs.
The revolutionary accelerators enable multi-precision computing that fuses the highly precise calculations to tackle the challenges of high performance computing with the efficient processing required for deep learning.
Additionally, half of the six projects included NVIDIA researchers who were heavily involved with the code development and performance tuning. NVIDIA employees listed as authors on nominated projects include: Kate Clark, Massimiliano Fatica, Michael Houston, Nathan Luehr, Akira Naruse, Everett Phillips, Joshua Romero and Sean Treichler.
Here’s an overview of the work by each of the five finalists who used NVIDIA Tensor Core GPUs:
- Identification of extreme weather patterns from high-resolution climate simulations: A team led by Prabhat, a data scientist at Lawrence Berkeley National Laboratory, and NVIDIA engineer Michael Houston used AI software to analyze how extreme weather is likely to change in the future. They used specialized Tensor Cores built into Summit’s NVIDIA GPUs to achieve a performance of 1.13 exaflops, the fastest deep learning algorithm reported.
- Use of AI and transprecision computing to accelerate earthquake simulation: A team led by Tsuyoshi Ichimura, of the University of Tokyo, used Summit to expand on an existing algorithm. The result was a 4x speedup enabling the coupling of shaking ground and urban structures within an earthquake simulation. The team started their GPU work with OpenACC, which helped get significant performance improvement within a short period of time. They later introduced CUDA and AI algorithms to further improve acceleration.
- Development of genomics algorithm to attain exascale speeds: A team from Oak Ridge National Laboratory led by Dan Jacobson achieved a peak throughput of 2.31 exaops, the fastest science application ever reported. Their work compares genetic variations within a population to uncover hidden networks of genes that contribute to complex traits. One condition the team is studying is opioid addiction, which was linked to nearly 50,000 U.S. deaths in 2017.
- Identification of materials’ atomic-level information from electron microscopy data: Another Oak Ridge team led by Robert Patton used Summit to develop AI-powered software to fabricate materials at the atomic level. The team achieved a speed of 152.5 petaflops across 3,000 nodes using the MENNDL algorithm.
- Development of an algorithm to help scientists quantify the lifetime of neutrons: A multi-institutional team led by Lawrence Berkeley National Laboratory computational nuclear physicist André Walker-Loud and Lawrence Livermore National Laboratory computational theoretical physicist Pavlos Vranas used the Volta GPU-based nodes of Summit and Sierra to calculate the physics of the subatomic particles making up protons and neutrons. They demonstrated improved workflow management capabilities that contributed to sustained performance of nearly 20 petaflops, a tenfold speedup from previous-generation systems. The team included Kate Clark of NVIDIA.
In the coming weeks, Oak Ridge National Laboratory will publish deep dives into all of the finalists’ work. To ensure you don’t miss these, or the winner of the Gordon Bell Prize, follow our Twitter handle at @NVIDIADC.
]]>