Accelerated computing is supercharging AI and data processing workloads, helping enterprises across industries achieve greater efficiency with reduced time and costs.
For over a decade, NVIDIA has worked with Amazon Web Services (AWS) to bring accelerated computing to businesses and developers around the world.
At AWS re:Invent 2024, taking place Dec. 2-6 in Las Vegas, NVIDIA’s full-stack offerings will be on display. Attendees can take a deep dive into the broad range of NVIDIA hardware and software platforms available on AWS and learn how partners and customers use them to accelerate their most compute-intensive workloads.
Highlights from the session catalog include:
- “NVIDIA Accelerated Computing Platform on AWS” with Dave Salvator, director of accelerated computing products at NVIDIA (AIM110-S)
- “Build, Customize and Deploy Generative AI With NVIDIA on AWS” with Abhishek Sawarkar, product manager at NVIDIA, and Charlie Huang, senior product marketing at NVIDIA (AIM241-S)
- “Advancing Physical AI: NVIDIA Isaac Lab and AWS for Next-Gen Robotics” with Rishabh Chadha, technical marketing engineer at NVIDIA; Abhishek Srivastav, senior solutions architect at AWS; and Shaun Kirby, principal enterprise architect at AWS (AIM113-S)
- “NVIDIA AI Startups: Innovations in Action” with Jen Hoskins, global head of Inception cloud partnerships and go-to-market at NVIDIA, and speakers from Inception startups, including Bria, Contextual AI, Hippocratic AI, Mendel AI, Twelve Labs and Writer (AIM121-S)
- “AI-Driven Value: Capital One’s Path to Better Customer Experience” with Joey Conway, senior director of product management for large language model software at NVIDIA, and Prem Natarajan, chief scientist and head of enterprise AI at Capital One (AIM130-S)
- “Accelerate Apache Spark Up to 5 Times on AWS With RAPIDS” with Sameer Raheja, senior director of engineering at NVIDIA (ANT208-S)
For a more hands-on experience, join an AWS Jam session and workshops:
- AWS Jam: Building a RAG Chat Agent With NVIDIA NIM (GHJ305)
- Robotic Simulation With NVIDIA Isaac Lab on AWS Batch (MFG319)
- Unleash Edge Computing With AWS IoT Greengrass on NVIDIA Jetson (IOT316)
- Building Scalable Drug Discovery Applications With NVIDIA BioNeMo (HLS205)
- Creating Immersive 3D Digital Twins From Photos, Videos and LiDAR With NVIDIA Omniverse (CMP315)
NVIDIA booth 1620 will feature a variety of demos, including a full NVIDIA GB200 NVL72 rack, coming soon to Amazon Elastic Compute Cloud (Amazon EC2) and NVIDIA DGX Cloud, as well as Spot, an agile mobile robot from Boston Dynamics.
Other demos showcasing the NVIDIA platform on AWS include:
- Powering Digital Twins and Physical AI With NVIDIA Omniverse
- Deploying Generative AI Faster With NVIDIA NIM
- Speed Deployment of AI With NVIDIA AI Blueprints, Including Generative Virtual Screening for Accelerated Drug Discovery
- The NVIDIA Accelerated Computing Platform on AWS, Hardware Show-and-Tell
- Fraud Prevention Reference Architecture on RAPIDS With AWS
NVIDIA will also feature demos from select partners and customers, including startups Balbix, Bria, Mendel AI, Standard Bots, Union and Writer.
Attendees can learn more about NVIDIA’s full-stack accelerated computing platform on AWS, including three new Amazon EC2 instance types released this year: Amazon EC2 P5e instances (NVIDIA H200 Tensor Core GPUs) for large-scale AI training and inference, G6e instances (NVIDIA L40S GPUs) for AI and graphics, and G6 instances (NVIDIA L4 Tensor Core GPUs) for small model deployments.
Plus, discover how NVIDIA’s GPU-optimized software stack delivers high performance across AWS services, making it easy for developers to accelerate their applications in the cloud. Some examples include:
- Generative AI: NVIDIA NeMo and NIM microservices, part of the NVIDIA AI Enterprise software platform and available in AWS Marketplace, for building, customizing and deploying generative AI on Amazon EC2, Amazon SageMaker and Amazon Elastic Kubernetes Service (EKS).
- Digital Twins and Physical AI: NVIDIA Earth-2 weather simulation on AWS and NVIDIA Isaac Sim and Isaac Lab for robot simulation and learning using AWS Batch.
- Healthcare: NVIDIA BioNeMo for drug discovery applications, including an NVIDIA AI Blueprint for virtual screening and NIM microservices for protein prediction and small molecule generation, supported on AWS Healthomics.
- Data Processing: RAPIDS Accelerator for Apache Spark for accelerating analytic and machine learning workloads, available on Amazon EMR, Amazon EC2 and Amazon EMR on EKS.
- Edge AI: NVIDIA Jetson with AWS IoT Greengrass for streamlined experiences to deploy generative AI models and manage fleets of connected edge devices and robots.
Members of the NVIDIA Inception program for cutting-edge startups are already testing, developing and deploying their most challenging workloads using the NVIDIA platform on AWS:
- Twelve Labs achieved up to a 7x inference improvement in requests served per second when upgrading to NVIDIA H100 Tensor Core GPUs. Its Marengo and Pegasus models, soon available as NIM microservices, power video Al solutions that enable semantic search on embedded enterprise video archives.
- Wiz doubled inference throughput speed for DSPM data classification using NIM microservices over alternatives.
- Writer achieved 3x faster model iteration cycles using SageMaker HyperPod with NVIDIA H100 GPUs. With NVIDIA accelerated computing and AWS, Writer optimized the training and inference of its Palmyra models, significantly reducing time to market for its customers.
Inception helps startups evolve faster by offering the latest NVIDIA technologies, opportunities to connect with venture capitalists, and access to technical resources and experts.
Register for AWS re:Invent to see how businesses can speed up their generative AI and data processing workloads with NVIDIA accelerated computing on AWS.
Send an email to schedule a meeting with NVIDIA experts at the show.
]]>Starting with the release of CUDA in 2006, NVIDIA has driven advancements in AI and accelerated computing — and the most recent TOP500 list of the world’s most powerful supercomputers highlights the culmination of the company’s achievements in the field.
This year, 384 systems on the TOP500 list are powered by NVIDIA technologies. Among the 53 new to the list, 87% — 46 systems — are accelerated. Of those accelerated systems, 85% use NVIDIA Hopper GPUs, driving advancements in areas like climate forecasting, drug discovery and quantum simulation.
Accelerated computing is much more than floating point operations per second (FLOPS). It requires full-stack, application-specific optimization. At SC24 this week, NVIDIA announced the release of cuPyNumeric, an NVIDIA CUDA-X library that enables over 5 million developers to seamlessly scale to powerful computing clusters without modifying their Python code.
NVIDIA also revealed significant updates to the NVIDIA CUDA-Q development platform, which empowers quantum researchers to simulate quantum devices at a scale previously thought computationally impossible.
And, NVIDIA received nearly a dozen HPCwire Readers’ and Editors’ Choice awards across a variety of categories, marking its 20th consecutive year of recognition.
A New Era of Scientific Discovery With Mixed Precision and AI
Mixed-precision floating-point operations and AI have become the tools of choice for researchers grappling with the complexities of modern science. They offer greater speed, efficiency and adaptability than traditional methods, without compromising accuracy.
This shift isn’t just theoretical — it’s already happening. At SC24, two Gordon Bell finalist projects revealed how using AI and mixed precision helped advance genomics and protein design.
In his paper titled “Using Mixed Precision for Genomics,” David Keyes, a professor at King Abdullah University of Science and Technology, used 0.8 exaflops of mixed precision to explore relationships between genomes and their generalized genotypes, and then to the prevalence of diseases to which they are subject.
Similarly, Arvind Ramanathan, a computational biologist from the Argonne National Laboratory, harnessed 3 exaflops of AI performance on the NVIDIA Grace Hopper-powered Alps system to speed up protein design.
To further advance AI-driven drug discovery and the development of lifesaving therapies, researchers can use NVIDIA BioNeMo, powerful tools designed specifically for pharmaceutical applications. Now in open source, the BioNeMo Framework can accelerate AI model creation, customization and deployment for drug discovery and molecular design.
Across the TOP500, the widespread use of AI and mixed-precision floating-point operations reflects a global shift in computing priorities. A total of 249 exaflops of AI performance are now available to TOP500 systems, supercharging innovations and discoveries across industries.
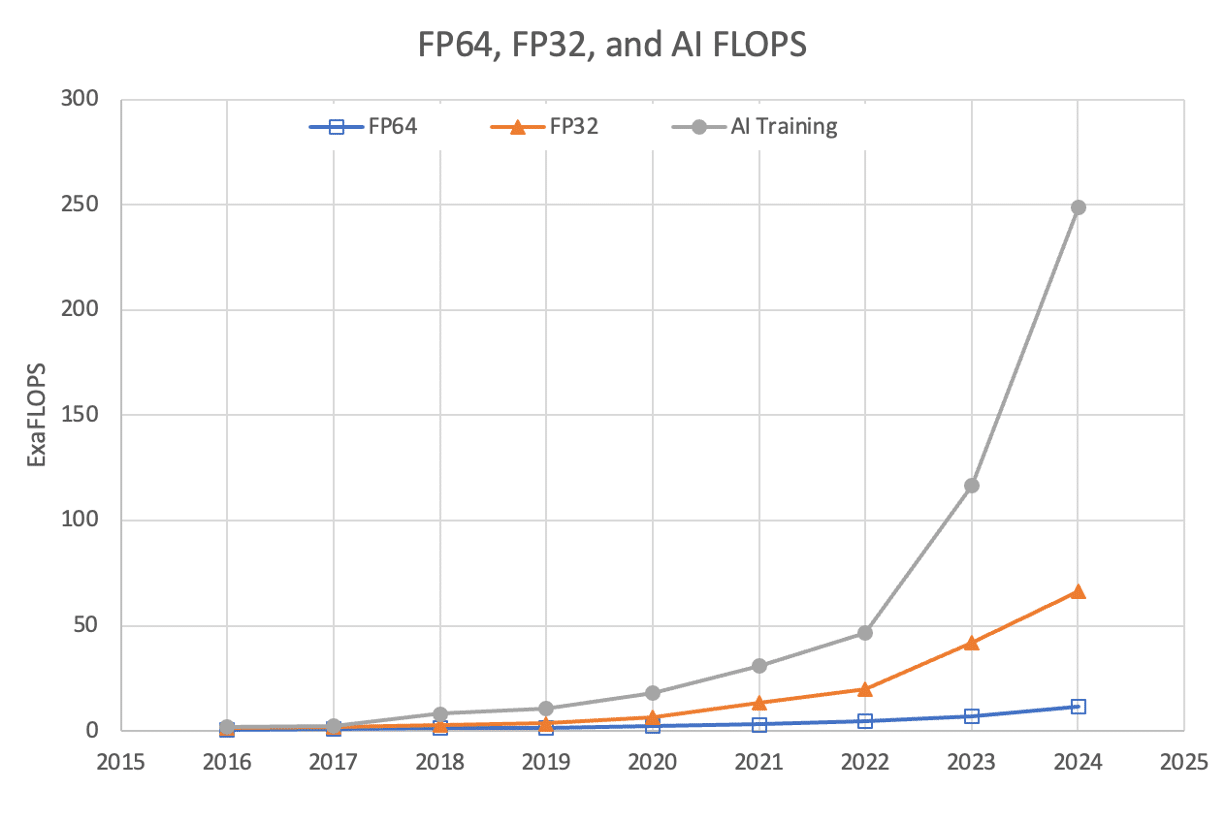
NVIDIA-accelerated TOP500 systems excel across key metrics like AI and mix-precision system performance. With over 190 exaflops of AI performance and 17 exaflops of single-precision (FP32), NVIDIA’s accelerated computing platform is the new engine of scientific computing. NVIDIA also delivers 4 exaflops of double-precision (FP64) performance for certain scientific calculations that still require it.
Accelerated Computing Is Sustainable Computing
As the demand for computational capacity grows, so does the need for sustainability.
In the Green500 list of the world’s most energy-efficient supercomputers, systems with NVIDIA accelerated computing rank among eight of the top 10. The JEDI system at EuroHPC/FZJ, for example, achieves a staggering 72.7 gigaflops per watt, setting a benchmark for what’s possible when performance and sustainability align.
For climate forecasting, NVIDIA announced at SC24 two new NVIDIA NIM microservices for NVIDIA Earth-2, a digital twin platform for simulating and visualizing weather and climate conditions. The CorrDiff NIM and FourCastNet NIM microservices can accelerate climate change modeling and simulation results by up to 500x.
In a world increasingly conscious of its environmental footprint, NVIDIA’s innovations in accelerated computing balance high performance with energy efficiency to help realize a brighter, more sustainable future.
Supercomputing Community Embraces NVIDIA
The 11 HPCwire Readers’ Choice and Editors’ Choice awards NVIDIA received represent the work of the entire scientific community of engineers, developers, researchers, partners, customers and more.
The awards include:
- Readers’ Choice: Best AI Product or Technology – NVIDIA GH200 Grace Hopper Superchip
- Readers’ Choice: Best HPC Interconnect Product or Technology – NVIDIA Quantum-X800
- Readers’ Choice: Best HPC Server Product or Technology – NVIDIA Grace CPU Superchip
- Readers’ Choice: Top 5 New Products or Technologies to Watch – NVIDIA Quantum-X800
- Readers’ Choice: Top 5 New Products or Technologies to Watch – NVIDIA Spectrum-X
- Readers’ and Editors’ Choice: Top 5 New Products or Technologies to Watch – NVIDIA Blackwell GPU
- Editors’ Choice: Top 5 New Products or Technologies to Watch – NVIDIA CUDA-Q
- Readers’ Choice: Top 5 Vendors to Watch – NVIDIA
- Readers’ Choice: Best HPC Response to Societal Plight – NVIDIA Earth-2
- Editors’ Choice: Best Use of HPC in Energy (one of two named contributors) – Real-time simulation of CO2 plume migration in carbon capture and storage
- Readers’ Choice Award: Best HPC Collaboration (one of 11 named contributors) – National Artificial Intelligence Research Resource Pilot
Watch the replay of NVIDIA’s special address at SC24 and learn more about the company’s news in the SC24 online press kit.
See notice regarding software product information.
]]>As COP29 attendees gather in Baku, Azerbaijan, to tackle climate change, the role AI plays in environmental sustainability is front and center.
A panel hosted by Deloitte brought together industry leaders to explore ways to reduce AI’s environmental footprint and align its growth with climate goals.
Experts from Crusoe Energy Systems, EON, the International Energy Agency (IEA) and NVIDIA sat down for a conversation about the energy efficiency of AI.
The Environmental Impact of AI
Deloitte’s recent report, “Powering Artificial Intelligence: A study of AI’s environmental footprint,” shows AI’s potential to drive a climate-neutral economy. The study looks at how organizations can achieve “Green AI” in the coming decades and addresses AI’s energy use.
Deloitte analysis predicts that AI adoption will fuel data center power demand, likely reaching 1,000 terawatt-hours (TWh) by 2030, and potentially climbing to 2,000 TWh by 2050. This will account for 3% of global electricity consumption, indicating faster growth than in other uses like electric cars and green hydrogen production.
While data centers currently consume around 2% of total electricity, and AI is a small fraction of that, the discussion at COP29 emphasized the need to meet rising energy demands with clean energy sources to support global climate goals.
Energy Efficiency From the Ground Up

NVIDIA is prioritizing energy-efficient data center operations with innovations like liquid-cooled GPUs. Direct-to-chip liquid cooling allows data centers to cool systems more effectively than traditional air conditioning, consuming less power and water.
“We see a very rapid trend toward direct-to-chip liquid cooling, which means water demands in data centers are dropping dramatically right now,” said Josh Parker, senior director of legal – corporate sustainability at NVIDIA.
As AI continues to scale, the future of data centers will hinge on designing for energy efficiency from the outset. By prioritizing energy efficiency from the ground up, data centers can meet the growing demands of AI while contributing to a more sustainable future.
Parker emphasized that existing data center infrastructure is becoming dated and less efficient. “The data shows that it’s 10x more efficient to run workloads on accelerated computing platforms than on traditional data center platforms,” he said. “There’s a huge opportunity for us to reduce the energy consumed in existing infrastructures.”
The Path to Green Computing
AI has the potential to play a large role in moving toward climate-neutral economies, according to Deloitte’s study. This approach, often called Green AI, involves reducing the environmental impact of AI throughout the value chain with practices like purchasing renewable energy and improving hardware design.
Until now, Green AI has mostly been led by industry leaders. Take accelerated computing, for instance, which is all about doing more with less. It uses special hardware — like GPUs — to perform tasks faster and with less energy than general-purpose servers that use CPUs, which handle a task at a time.
That’s why accelerated computing is sustainable computing.
“Accelerated computing is actually the most energy-efficient platform that we’ve seen for AI but also for a lot of other computing applications,” said Parker.
“The trend in energy efficiency for accelerated computing over the last several years shows a 100,000x reduction in energy consumption. And just in the past 2 years, we’ve become 25x more efficient for AI inference. That’s a 96% reduction in energy for the same computational workload,” he said.
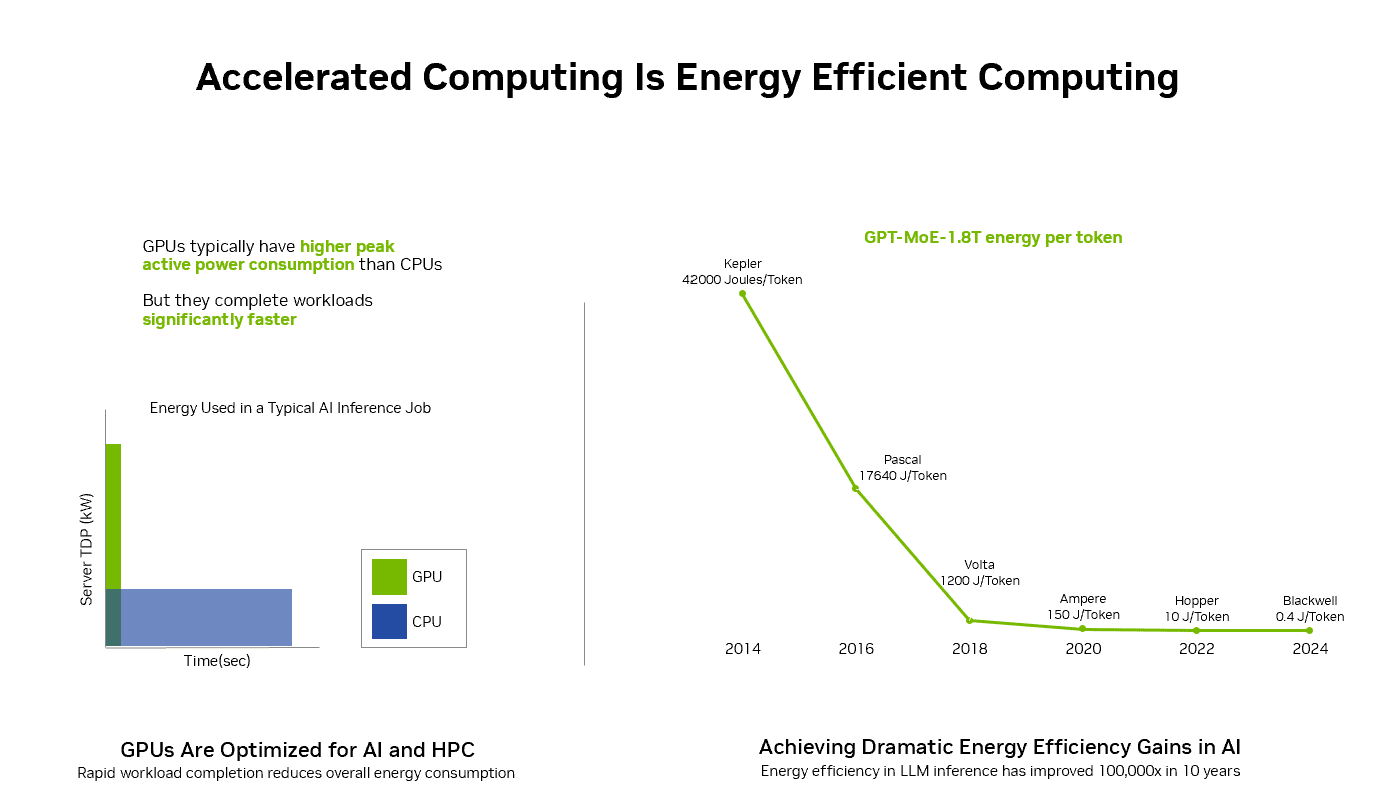
Reducing Energy Consumption Across Sectors
Innovations like the NVIDIA Blackwell and Hopper architectures significantly improve energy efficiency with each new generation. NVIDIA Blackwell is 25x more energy-efficient for large language models, and the NVIDIA H100 Tensor Core GPU is 20x more efficient than CPUs for complex workloads.
“AI has the potential to make other sectors much more energy efficient,” said Parker. Murex, a financial services firm, achieved a 4x reduction in energy use and 7x faster performance with the NVIDIA Grace Hopper Superchip.
“In manufacturing, we’re seeing around 30% reductions in energy requirements if you use AI to help optimize the manufacturing process through digital twins,” he said.
For example, manufacturing company Wistron improved energy efficiency using digital twins and NVIDIA Omniverse, a platform for developing OpenUSD applications for industrial digitalization and physical AI simulation. The company reduced its electricity consumption by 120,000 kWh and carbon emissions by 60,000 kg annually.
A Tool for Energy Management
Deloitte reports that AI can help optimize resource use and reduce emissions, playing a crucial role in energy management. This means it has the potential to lower the impact of industries beyond its own carbon footprint.
Combined with digital twins, AI is transforming energy management systems by improving the reliability of renewable sources like solar and wind farms. It’s also being used to optimize facility layouts, monitor equipment, stabilize power grids and predict climate patterns, aiding in global efforts to reduce carbon emissions.
COP29 discussions emphasized the importance of powering AI infrastructure with renewables and setting ethical guidelines. By innovating with the environment in mind, industries can use AI to build a more sustainable world.
Watch a replay of the on-demand COP29 panel discussion.
]]>NVIDIA and Microsoft today unveiled product integrations designed to advance full-stack NVIDIA AI development on Microsoft platforms and applications.
At Microsoft Ignite, Microsoft announced the launch of the first cloud private preview of the Azure ND GB200 V6 VM series, based on the NVIDIA Blackwell platform. The Azure ND GB200 v6 will be a new AI-optimized virtual machine (VM) series and combines the NVIDIA GB200 NVL72 rack design with NVIDIA Quantum InfiniBand networking.
In addition, Microsoft revealed that Azure Container Apps now supports NVIDIA GPUs, enabling simplified and scalable AI deployment. Plus, the NVIDIA AI platform on Azure includes new reference workflows for industrial AI and an NVIDIA Omniverse Blueprint for creating immersive, AI-powered visuals.
At Ignite, NVIDIA also announced multimodal small language models (SLMs) for RTX AI PCs and workstations, enhancing digital human interactions and virtual assistants with greater realism.
NVIDIA Blackwell Powers Next-Gen AI on Microsoft Azure
Microsoft’s new Azure ND GB200 V6 VM series will harness the powerful performance of NVIDIA GB200 Grace Blackwell Superchips, coupled with advanced NVIDIA Quantum InfiniBand networking. This offering is optimized for large-scale deep learning workloads to accelerate breakthroughs in natural language processing, computer vision and more.
The Blackwell-based VM series complements previously announced Azure AI clusters with ND H200 V5 VMs, which provide increased high-bandwidth memory for improved AI inferencing. The ND H200 V5 VMs are already being used by OpenAI to enhance ChatGPT.
Azure Container Apps Enables Serverless AI Inference With NVIDIA Accelerated Computing
Serverless computing provides AI application developers increased agility to rapidly deploy, scale and iterate on applications without worrying about underlying infrastructure. This enables them to focus on optimizing models and improving functionality while minimizing operational overhead.
The Azure Container Apps serverless containers platform simplifies deploying and managing microservices-based applications by abstracting away the underlying infrastructure.
Azure Container Apps now supports NVIDIA-accelerated workloads with serverless GPUs, allowing developers to use the power of accelerated computing for real-time AI inference applications in a flexible, consumption-based, serverless environment. This capability simplifies AI deployments at scale while improving resource efficiency and application performance without the burden of infrastructure management.
Serverless GPUs allow development teams to focus more on innovation and less on infrastructure management. With per-second billing and scale-to-zero capabilities, customers pay only for the compute they use, helping ensure resource utilization is both economical and efficient. NVIDIA is also working with Microsoft to bring NVIDIA NIM microservices to serverless NVIDIA GPUs in Azure to optimize AI model performance.
NVIDIA Unveils Omniverse Reference Workflows for Advanced 3D Applications
NVIDIA announced reference workflows that help developers to build 3D simulation and digital twin applications on NVIDIA Omniverse and Universal Scene Description (OpenUSD) — accelerating industrial AI and advancing AI-driven creativity.
A reference workflow for 3D remote monitoring of industrial operations is coming soon to enable developers to connect physically accurate 3D models of industrial systems to real-time data from Azure IoT Operations and Power BI.
These two Microsoft services integrate with applications built on NVIDIA Omniverse and OpenUSD to provide solutions for industrial IoT use cases. This helps remote operations teams accelerate decision-making and optimize processes in production facilities.
The Omniverse Blueprint for precise visual generative AI enables developers to create applications that let nontechnical teams generate AI-enhanced visuals while preserving brand assets. The blueprint supports models like SDXL and Shutterstock Generative 3D to streamline the creation of on-brand, AI-generated images.
Leading creative groups, including Accenture Song, Collective, GRIP, Monks and WPP, have adopted this NVIDIA Omniverse Blueprint to personalize and customize imagery across markets.
Accelerating Gen AI for Windows With RTX AI PCs
NVIDIA’s collaboration with Microsoft extends to bringing AI capabilities to personal computing devices.
At Ignite, NVIDIA announced its new multimodal SLM, NVIDIA Nemovision-4B Instruct, for understanding visual imagery in the real world and on screen. It’s coming soon to RTX AI PCs and workstations and will pave the way for more sophisticated and lifelike digital human interactions.
Plus, updates to NVIDIA TensorRT Model Optimizer (ModelOpt) offer Windows developers a path to optimize a model for ONNX Runtime deployment. TensorRT ModelOpt enables developers to create AI models for PCs that are faster and more accurate when accelerated by RTX GPUs. This enables large models to fit within the constraints of PC environments, while making it easy for developers to deploy across the PC ecosystem with ONNX runtimes.
RTX AI-enabled PCs and workstations offer enhanced productivity tools, creative applications and immersive experiences powered by local AI processing.
Full-Stack Collaboration for AI Development
NVIDIA’s extensive ecosystem of partners and developers brings a wealth of AI and high-performance computing options to the Azure platform.
SoftServe, a global IT consulting and digital services provider, today announced the availability of SoftServe Gen AI Industrial Assistant, based on the NVIDIA AI Blueprint for multimodal PDF data extraction, on the Azure marketplace. The assistant addresses critical challenges in manufacturing by using AI to enhance equipment maintenance and improve worker productivity.
At Ignite, AT&T will showcase how it’s using NVIDIA AI and Azure to enhance operational efficiency, boost employee productivity and drive business growth through retrieval-augmented generation and autonomous assistants and agents.
Learn more about NVIDIA and Microsoft’s collaboration and sessions at Ignite.
See notice regarding software product information.
]]>NVIDIA kicked off SC24 in Atlanta with a wave of AI and supercomputing tools set to revolutionize industries like biopharma and climate science.
The announcements, delivered by NVIDIA founder and CEO Jensen Huang and Vice President of Accelerated Computing Ian Buck, are rooted in the company’s deep history in transforming computing.
“Supercomputers are among humanity’s most vital instruments, driving scientific breakthroughs and expanding the frontiers of knowledge,” Huang said. “Twenty-five years after creating the first GPU, we have reinvented computing and sparked a new industrial revolution.”
NVIDIA’s journey in accelerated computing began with CUDA in 2006 and the first GPU for scientific computing, Huang said.
Milestones like Tokyo Tech’s Tsubame supercomputer in 2008, the Oak Ridge National Laboratory’s Titan supercomputer in 2012 and the AI-focused NVIDIA DGX-1 delivered to OpenAI in 2016 highlight NVIDIA’s transformative role in the field.
“Since CUDA’s inception, we’ve driven down the cost of computing by a millionfold,” Huang said. “For some, NVIDIA is a computational microscope, allowing them to see the impossibly small. For others, it’s a telescope exploring the unimaginably distant. And for many, it’s a time machine, letting them do their life’s work within their lifetime.”
At SC24, NVIDIA’s announcements spanned tools for next-generation drug discovery, real-time climate forecasting and quantum simulations.
Central to the company’s advancements are CUDA-X libraries, described by Huang as “the engines of accelerated computing,” which power everything from AI-driven healthcare breakthroughs to quantum circuit simulations.
Huang and Buck highlighted examples of real-world impact, including Nobel Prize-winning breakthroughs in neural networks and protein prediction, powered by NVIDIA technology.
“AI will accelerate scientific discovery, transforming industries and revolutionizing every one of the world’s $100 trillion markets,” Huang said.
CUDA-X Libraries Power New Frontiers
At SC24, NVIDIA announced the new cuPyNumeric library, a GPU-accelerated implementation of NumPy, designed to supercharge applications in data science, machine learning and numerical computing.
With over 400 CUDA-X libraries, including cuDNN for deep learning and cuQuantum for quantum circuit simulations, NVIDIA continues to lead in enhancing computing capabilities across various industries.
Real-Time Digital Twins With Omniverse Blueprint
NVIDIA unveiled the NVIDIA Omniverse Blueprint for real-time computer-aided engineering digital twins, a reference workflow designed to help developers create interactive digital twins for industries like aerospace, automotive, energy and manufacturing.
Built on NVIDIA acceleration libraries, physics-AI frameworks and interactive, physically based rendering, the blueprint accelerates simulations by up to 1,200x, setting a new standard for real-time interactivity.
Early adopters, including Siemens, Altair, Ansys and Cadence, are already using the blueprint to optimize workflows, cut costs and bring products to market faster.
Quantum Leap With CUDA-Q
NVIDIA’s focus on real-time, interactive technologies extends across fields, from engineering to quantum simulations.
In partnership with Google, NVIDIA’s CUDA-Q now powers detailed dynamical simulations of quantum processors, reducing weeks-long calculations to minutes.
Buck explained that with CUDA-Q, developers of all quantum processors can perform larger simulations and explore more scalable qubit designs.
AI Breakthroughs in Drug Discovery and Chemistry
With the open-source release of BioNeMo Framework, NVIDIA is advancing AI-driven drug discovery as researchers gain powerful tools tailored specifically for pharmaceutical applications.
BioNeMo accelerates training by 2x compared to other AI software, enabling faster development of lifesaving therapies.
NVIDIA also unveiled DiffDock 2.0, a breakthrough tool for predicting how drugs bind to target proteins — critical for drug discovery.
Powered by the new cuEquivariance library, DiffDock 2.0 is 6x faster than before, enabling researchers to screen millions of molecules with unprecedented speed and accuracy.
And the NVIDIA ALCHEMI NIM microservice, NVIDIA introduces generative AI to chemistry, allowing researchers to design and evaluate novel materials with incredible speed.
Scientists start by defining the properties they want — like strength, conductivity, low toxicity or even color, Buck explained.
A generative model suggests thousands of potential candidates with the desired properties. Then the ALCHEMI NIM sorts candidate compounds for stability by solving for their lowest energy states using NVIDIA Warp.
This microservice is a game-changer for materials discovery, helping developers tackle challenges in renewable energy and beyond.
These innovations demonstrate how NVIDIA is harnessing AI to drive breakthroughs in science, transforming industries and enabling faster solutions to global challenges.
Earth-2 NIM Microservices: Redefining Climate Forecasts in Real Time
Buck also announced two new microservices — CorrDiff NIM and FourCastNet NIM — to accelerate climate change modeling and simulation results by up to 500x in the NVIDIA Earth-2 platform.
Earth-2, a digital twin for simulating and visualizing weather and climate conditions, is designed to empower weather technology companies with advanced generative AI-driven capabilities.
These tools deliver higher-resolution and more accurate predictions, enabling the forecasting of extreme weather events with unprecedented speed and energy efficiency.
With natural disasters causing $62 billion in insured losses in the first half of this year — 70% higher than the 10-year average — NVIDIA’s innovations address a growing need for precise, real-time climate forecasting. These tools highlight NVIDIA’s commitment to leveraging AI for societal resilience and climate preparedness.
Expanding Production With Foxconn Collaboration
As demand for AI systems like the Blackwell supercomputer grows, NVIDIA is scaling production through new Foxconn facilities in the U.S., Mexico and Taiwan.
Foxconn is building the production and testing facilities using NVIDIA Omniverse to bring up the factories as fast as possible.
Scaling New Heights With Hopper
NVIDIA also announced the general availability of the NVIDIA H200 NVL, a PCIe GPU based on the NVIDIA Hopper architecture optimized for low-power, air-cooled data centers.
The H200 NVL offers up to 1.7x faster large language model inference and 1.3x more performance on HPC applications, making it ideal for flexible data center configurations.
It supports a variety of AI and HPC workloads, enhancing performance while optimizing existing infrastructure.
And the GB200 Grace Blackwell NVL4 Superchip integrates four NVIDIA NVLink-connected Blackwell GPUs unified with two Grace CPUs over NVLink-C2C, Buck said. It provides up to 2x performance for scientific computing, training and inference applications over the prior generation. |
The GB200 NVL4 superchip will be available in the second half of 2025.
The talk wrapped up with an invitation to attendees to visit NVIDIA’s booth at SC24 to interact with various demos, including James, NVIDIA’s digital human, the world’s first real-time interactive wind tunnel and the Earth-2 NIM microservices for climate modeling.
Learn more about how NVIDIA’s innovations are shaping the future of science at SC24.
]]>
NVIDIA today at SC24 announced two new NVIDIA NIM microservices that can accelerate climate change modeling simulation results by 500x in NVIDIA Earth-2.
Earth-2 is a digital twin platform for simulating and visualizing weather and climate conditions. The new NIM microservices offer climate technology application providers advanced generative AI-driven capabilities to assist in forecasting extreme weather events.
NVIDIA NIM microservices help accelerate the deployment of foundation models while keeping data secure.
Extreme weather incidents are increasing in frequency, raising concerns over disaster safety and preparedness, and possible financial impacts.
Natural disasters were responsible for roughly $62 billion of insured losses during the first half of this year. That’s about 70% more than the 10-year average, according to a report in Bloomberg.
NVIDIA is releasing the CorrDiff NIM and FourCastNet NIM microservices to help weather technology companies more quickly develop higher-resolution and more accurate predictions. The NIM microservices also deliver leading energy efficiency compared with traditional systems.
New CorrDiff NIM Microservices for Higher-Resolution Modeling
NVIDIA CorrDiff is a generative AI model for kilometer-scale super resolution. Its capability to super-resolve typhoons over Taiwan was recently shown at GTC 2024. CorrDiff was trained on the Weather Research and Forecasting (WRF) model’s numerical simulations to generate weather patterns at 12x higher resolution.
High-resolution forecasts capable of visualizing within the fewest kilometers are essential to meteorologists and industries. The insurance and reinsurance industries rely on detailed weather data for assessing risk profiles. But achieving this level of detail using traditional numerical weather prediction models like WRF or High-Resolution Rapid Refresh is often too costly and time-consuming to be practical.
The CorrDiff NIM microservice is 500x faster and 10,000x more energy-efficient than traditional high-resolution numerical weather prediction using CPUs. Also, CorrDiff is now operating at 300x larger scale. It is super-resolving — or increasing the resolution of lower-resolution images or videos — for the entire United States and predicting precipitation events, including snow, ice and hail, with visibility in the kilometers.
Enabling Large Sets of Forecasts With New FourCastNet NIM Microservice
Not every use case requires high-resolution forecasts. Some applications benefit more from larger sets of forecasts at coarser resolution.
State-of-the-art numerical models like IFS and GFS are limited to 50 and 20 sets of forecasts, respectively, due to computational constraints.
The FourCastNet NIM microservice, available today, offers global, medium-range coarse forecasts. By using the initial assimilated state from operational weather centers such as European Centre for Medium-Range Weather Forecasts or National Oceanic and Atmospheric Administration, providers can generate forecasts for the next two weeks, 5,000x faster than traditional numerical weather models.
This opens new opportunities for climate tech providers to estimate risks related to extreme weather at a different scale, enabling them to predict the likelihood of low-probability events that current computational pipelines overlook.
Learn more about CorrDiff and FourCastNet NIM microservices on ai.nvidia.com.
]]>Whether they’re looking at nanoscale electron behaviors or starry galaxies colliding millions of light years away, many scientists share a common challenge — they must comb through petabytes of data to extract insights that can advance their fields.
With the NVIDIA cuPyNumeric accelerated computing library, researchers can now take their data-crunching Python code and effortlessly run it on CPU-based laptops and GPU-accelerated workstations, cloud servers or massive supercomputers. The faster they can work through their data, the quicker they can make decisions about promising data points, trends worth investigating and adjustments to their experiments.
To make the leap to accelerated computing, researchers don’t need expertise in computer science. They can simply write code using the familiar NumPy interface or apply cuPyNumeric to existing code, following best practices for performance and scalability.
Once cuPyNumeric is applied, they can run their code on one or thousands of GPUs with zero code changes.
The latest version of cuPyNumeric, now available on Conda and GitHub, offers support for the NVIDIA GH200 Grace Hopper Superchip, automatic resource configuration at run time and improved memory scaling. It also supports HDF5, a popular file format in the scientific community that helps efficiently manage large, complex data.
Researchers at the SLAC National Accelerator Laboratory, Los Alamos National Laboratory, Australia National University, UMass Boston, the Center for Turbulence Research at Stanford University and the National Payments Corporation of India are among those who have integrated cuPyNumeric to achieve significant improvements in their data analysis workflows.
Less Is More: Limitless GPU Scalability Without Code Changes
Python is the most common programming language for data science, machine learning and numerical computing, used by millions of researchers in scientific fields including astronomy, drug discovery, materials science and nuclear physics. Tens of thousands of packages on GitHub depend on the NumPy math and matrix library, which had over 300 million downloads last month. All of these applications could benefit from accelerated computing with cuPyNumeric.
Many of these scientists build programs that use NumPy and run on a single CPU-only node — limiting the throughput of their algorithms to crunch through increasingly large datasets collected by instruments like electron microscopes, particle colliders and radio telescopes.
cuPyNumeric helps researchers keep pace with the growing size and complexity of their datasets by providing a drop-in replacement for NumPy that can scale to thousands of GPUs. cuPyNumeric doesn’t require code changes when scaling from a single GPU to a whole supercomputer. This makes it easy for researchers to run their analyses on accelerated computing systems of any size.
Solving the Big Data Problem, Accelerating Scientific Discovery
Researchers at SLAC National Accelerator Laboratory, a U.S. Department of Energy lab operated by Stanford University, have found that cuPyNumeric helps them speed up X-ray experiments conducted at the Linac Coherent Light Source.
A SLAC team focused on materials science discovery for semiconductors found that cuPyNumeric accelerated its data analysis application by 6x, decreasing run time from minutes to seconds. This speedup allows the team to run important analyses in parallel when conducting experiments at this highly specialized facility.
By using experiment hours more efficiently, the team anticipates it will be able to discover new material properties, share results and publish work more quickly.
Other institutions using cuPyNumeric include:
- Australia National University, where researchers used cuPyNumeric to scale the Levenberg-Marquardt optimization algorithm to run on multi-GPU systems at the country’s National Computational Infrastructure. While the algorithm can be used for many applications, the researchers’ initial target is large-scale climate and weather models.
- Los Alamos National Laboratory, where researchers are applying cuPyNumeric to accelerate data science, computational science and machine learning algorithms. cuPyNumeric will provide them with additional tools to effectively use the recently launched Venado supercomputer, which features over 2,500 NVIDIA GH200 Grace Hopper Superchips.
- Stanford University’s Center for Turbulence Research, where researchers are developing Python-based computational fluid dynamics solvers that can run at scale on large accelerated computing clusters using cuPyNumeric. These solvers can seamlessly integrate large collections of fluid simulations with popular machine learning libraries like PyTorch, enabling complex applications including online training and reinforcement learning.
- UMass Boston, where a research team is accelerating linear algebra calculations to analyze microscopy videos and determine the energy dissipated by active materials. The team used cuPyNumeric to decompose a matrix of 16 million rows and 4,000 columns.
- National Payments Corporation of India, the organization behind a real-time digital payment system used by around 250 million Indians daily and expanding globally. NPCI uses complex matrix calculations to track transaction paths between payers and payees. With current methods, it takes about 5 hours to process data for a one-week transaction window on CPU systems. A trial showed that applying cuPyNumeric to accelerate the calculations on multi-node NVIDIA DGX systems could speed up matrix multiplication by 50x, enabling NPCI to process larger transaction windows in less than an hour and detect suspected money laundering in near real time.
To learn more about cuPyNumeric, see a live demo in the NVIDIA booth at the Supercomputing 2024 conference in Atlanta, join the theater talk in the expo hall and participate in the cuPyNumeric workshop.
Watch the NVIDIA special address at SC24.
]]>Since its introduction, the NVIDIA Hopper architecture has transformed the AI and high-performance computing (HPC) landscape, helping enterprises, researchers and developers tackle the world’s most complex challenges with higher performance and greater energy efficiency.
During the Supercomputing 2024 conference, NVIDIA announced the availability of the NVIDIA H200 NVL PCIe GPU — the latest addition to the Hopper family. H200 NVL is ideal for organizations with data centers looking for lower-power, air-cooled enterprise rack designs with flexible configurations to deliver acceleration for every AI and HPC workload, regardless of size.
According to a recent survey, roughly 70% of enterprise racks are 20kW and below and use air cooling. This makes PCIe GPUs essential, as they provide granularity of node deployment, whether using one, two, four or eight GPUs — enabling data centers to pack more computing power into smaller spaces. Companies can then use their existing racks and select the number of GPUs that best suits their needs.
Enterprises can use H200 NVL to accelerate AI and HPC applications, while also improving energy efficiency through reduced power consumption. With a 1.5x memory increase and 1.2x bandwidth increase over NVIDIA H100 NVL, companies can use H200 NVL to fine-tune LLMs within a few hours and deliver up to 1.7x faster inference performance. For HPC workloads, performance is boosted up to 1.3x over H100 NVL and 2.5x over the NVIDIA Ampere architecture generation.
Complementing the raw power of the H200 NVL is NVIDIA NVLink technology. The latest generation of NVLink provides GPU-to-GPU communication 7x faster than fifth-generation PCIe — delivering higher performance to meet the needs of HPC, large language model inference and fine-tuning.
The NVIDIA H200 NVL is paired with powerful software tools that enable enterprises to accelerate applications from AI to HPC. It comes with a five-year subscription for NVIDIA AI Enterprise, a cloud-native software platform for the development and deployment of production AI. NVIDIA AI Enterprise includes NVIDIA NIM microservices for the secure, reliable deployment of high-performance AI model inference.
Companies Tapping Into Power of H200 NVL
With H200 NVL, NVIDIA provides enterprises with a full-stack platform to develop and deploy their AI and HPC workloads.
Customers are seeing significant impact for multiple AI and HPC use cases across industries, such as visual AI agents and chatbots for customer service, trading algorithms for finance, medical imaging for improved anomaly detection in healthcare, pattern recognition for manufacturing, and seismic imaging for federal science organizations.
Dropbox is harnessing NVIDIA accelerated computing for its services and infrastructure.
“Dropbox handles large amounts of content, requiring advanced AI and machine learning capabilities,” said Ali Zafar, VP of Infrastructure at Dropbox. “We’re exploring H200 NVL to continually improve our services and bring more value to our customers.”
The University of New Mexico has been using NVIDIA accelerated computing in various research and academic applications.
“As a public research university, our commitment to AI enables the university to be on the forefront of scientific and technological advancements,” said Prof. Patrick Bridges, director of the UNM Center for Advanced Research Computing. “As we shift to H200 NVL, we’ll be able to accelerate a variety of applications, including data science initiatives, bioinformatics and genomics research, physics and astronomy simulations, climate modeling and more.”
H200 NVL Available Across Ecosystem
Dell Technologies, Hewlett Packard Enterprise, Lenovo and Supermicro are expected to deliver a wide range of configurations supporting H200 NVL.
Additionally, H200 NVL will be available in platforms from Aivres, ASRock Rack, ASUS, GIGABYTE, Ingrasys, Inventec, MSI, Pegatron, QCT, Wistron and Wiwynn.
Some systems are based on the NVIDIA MGX modular architecture, which enables computer makers to quickly and cost-effectively build a vast array of data center infrastructure designs.
Platforms with H200 NVL will be available from NVIDIA’s global systems partners beginning in December. To complement availability from leading global partners, NVIDIA is also developing an Enterprise Reference Architecture for H200 NVL systems.
The reference architecture will incorporate NVIDIA’s expertise and design principles, so partners and customers can design and deploy high-performance AI infrastructure based on H200 NVL at scale. This includes full-stack hardware and software recommendations, with detailed guidance on optimal server, cluster and network configurations. Networking is optimized for the highest performance with the NVIDIA Spectrum-X Ethernet platform.
NVIDIA technologies will be showcased on the showroom floor at SC24, taking place at the Georgia World Congress Center through Nov. 22. To learn more, watch NVIDIA’s special address.
See notice regarding software product information.
]]>To meet demand for Blackwell, now in full production, Foxconn, the world’s largest electronics manufacturer, is using NVIDIA Omniverse. The platform for developing industrial AI simulation applications is helping bring facilities in the U.S., Mexico and Taiwan online faster than ever.
Foxconn uses NVIDIA Omniverse to virtually integrate their facility and equipment layouts, NVIDIA Isaac Sim for autonomous robot testing and simulation, and NVIDIA Metropolis for vision AI.
Omniverse enables industrial developers to maximize efficiency through test and optimization in a digital twin before deploying costly change-orders to the physical world. Foxconn expects its Mexico facility alone to deliver significant cost savings and a reduction in kilowatt-hour usage of more than 30% annually.
World’s Largest Electronics Maker Plans With Omniverse and AI
To meet demands at Foxconn, factory planners are building physical AI-powered robotic factories with Omniverse and NVIDIA AI.
The company has built digital twins with Omniverse that allow their teams to virtually integrate facility and equipment information from leading industry applications, such as Siemens Teamcenter X and Autodesk Revit. Floor plan layouts are optimized first in the digital twin, and planners can locate optimal camera positions that help measure and identify ways to streamline operations with Metropolis visual AI agents.
In the construction process, the Foxconn teams use the Omniverse digital twin as the source of truth to communicate and validate the accurate layout and placement of equipment.
Virtual integration on Omniverse offers significant advantages, potentially saving factory planners millions by reducing costly change orders in real-world operations.
Delivering Robotics for Manufacturing With Omniverse Digital Twin
Once the digital twin of the factory is built, it becomes a virtual gym for Foxconn’s fleets of autonomous robots including industrial manipulators and autonomous mobile robots. Foxconn’s robot developers can simulate, test and validate their AI robot models in NVIDIA Isaac Sim before deploying to their real world robots.
Using Omniverse, Foxconn can simulate robot AIs before deploying to NVIDIA Jetson-driven autonomous mobile robots.
On assembly lines, they can simulate with Isaac Manipulator libraries and AI models for automated optical inspection, object identification, defect detection and trajectory planning.
Omniverse also enables their facility planners to test and optimize intelligent camera placement before installing in the physical world – ensuring they have complete coverage of the factory floor to support worker safety, and provide the foundation for visual AI agent frameworks.
Creating Efficiencies While Building Resilient Supply Chains
Using NVIDIA Omniverse and AI, Foxconn plans to replicate its precision production lines across the world. This will enable it to quickly deploy high-quality production facilities that meet unified standards, increasing the company’s competitive edge and adaptability in the market.
Foxconn’s ability to rapidly replicate will accelerate its global deployments and enhance its resilience in the supply chain in the face of disruptions, as it can quickly adjust production strategies and reallocate resources to ensure continuity and stability to meet changing demands.
Foxconn’s Mexico facility will begin production early next year and the Taiwan location will begin production in December.
]]>More than 96% of all manufactured goods — ranging from everyday products, like laundry detergent and food packaging, to advanced industrial components, such as semiconductors, batteries and solar panels — rely on chemicals that cannot be replaced with alternative materials.
With AI and the latest technological advancements, researchers and developers are studying ways to create novel materials that could address the world’s toughest challenges, such as energy storage and environmental remediation.
Announced today at the Supercomputing 2024 conference in Atlanta, the NVIDIA ALCHEMI NIM microservice accelerates such research by optimizing AI inference for chemical simulations that could lead to more efficient and sustainable materials to support the renewable energy transition.
It’s one of the many ways NVIDIA is supporting researchers, developers and enterprises to boost energy and resource efficiency in their workflows, including to meet requirements aligned with the global Net Zero Initiative.
NVIDIA ALCHEMI for Material and Chemical Simulations
Exploring the universe of potential materials, using the nearly infinite combinations of chemicals — each with unique characteristics — can be extremely complex and time consuming. Novel materials are typically discovered through laborious, trial-and-error synthesis and testing in a traditional lab.
Many of today’s plastics, for example, are still based on material discoveries made in the mid-1900s.
More recently, AI has emerged as a promising accelerant for chemicals and materials innovation.
With the new ALCHEMI NIM microservice, researchers can test chemical compounds and material stability in simulation, in a virtual AI lab, which reduces costs, energy consumption and time to discovery.
For example, running MACE-MP-0, a pretrained foundation model for materials chemistry, on an NVIDIA H100 Tensor Core GPU, the new NIM microservice speeds evaluations of a potential composition’s simulated long-term stability 100x. The below figure shows a 25x speedup from using the NVIDIA Warp Python framework for high-performance simulation, followed by a 4x speedup with in-flight batching. All in all, evaluating 16 million structures would have taken months — with the NIM microservice, it can be done in just hours.

By letting scientists examine more structures in less time, the NIM microservice can boost research on materials for use with solar and electric batteries, for example, to bolster the renewable energy transition.
NVIDIA also plans to release NIM microservices that can be used to simulate the manufacturability of novel materials — to determine how they might be brought from test tubes into the real world in the form of batteries, solar panels, fertilizers, pesticides and other essential products that can contribute to a healthier, greener planet.
SES AI, a leading developer of lithium-metal batteries, is using the NVIDIA ALCHEMI NIM microservice with the AIMNet2 model to accelerate the identification of electrolyte materials used for electric vehicles.
“SES AI is dedicated to advancing lithium battery technology through AI-accelerated material discovery, using our Molecular Universe Project to explore and identify promising candidates for lithium metal electrolyte discovery,” said Qichao Hu, CEO of SES AI. “Using the ALCHEMI NIM microservice with AIMNet2 could drastically improve our ability to map molecular properties, reducing time and costs significantly and accelerating innovation.”
SES AI recently mapped 100,000 molecules in half a day, with the potential to achieve this in under an hour using ALCHEMI. This signals how the microservice is poised to have a transformative impact on material screening efficiency.
Looking ahead, SES AI aims to map the properties of up to 10 billion molecules within the next couple of years, pushing the boundaries of AI-driven, high-throughput discovery.
The new microservice will soon be available for researchers to test for free through the NVIDIA NGC catalog — be notified of ALCHEMI’s launch. It will also be downloadable from build.nvidia.com, and the production-grade NIM microservice will be offered through the NVIDIA AI Enterprise software platform.
Learn more about the NVIDIA ALCHEMI NIM microservice, and hear the latest on how AI and supercomputing are supercharging researchers and developers’ workflows by joining NVIDIA at SC24, running through Friday, Nov. 22.
See notice regarding software product information.
]]>Editor’s note: This article, originally published on November 15, 2023, has been updated.
To understand the latest advance in generative AI, imagine a courtroom.
Judges hear and decide cases based on their general understanding of the law. Sometimes a case — like a malpractice suit or a labor dispute — requires special expertise, so judges send court clerks to a law library, looking for precedents and specific cases they can cite.
Like a good judge, large language models (LLMs) can respond to a wide variety of human queries. But to deliver authoritative answers that cite sources, the model needs an assistant to do some research.
The court clerk of AI is a process called retrieval-augmented generation, or RAG for short.
How It Got Named ‘RAG’
Patrick Lewis, lead author of the 2020 paper that coined the term, apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.

“We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
“We always planned to have a nicer sounding name, but when it came time to write the paper, no one had a better idea,” said Lewis, who now leads a RAG team at AI startup Cohere.
So, What Is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences.
That deep understanding, sometimes called parameterized knowledge, makes LLMs useful in responding to general prompts at light speed. However, it does not serve users who want a deeper dive into a current or more specific topic.
Combining Internal, External Resources
Lewis and colleagues developed retrieval-augmented generation to link generative AI services to external resources, especially ones rich in the latest technical details.
The paper, with coauthors from the former Facebook AI Research (now Meta AI), University College London and New York University, called RAG “a general-purpose fine-tuning recipe” because it can be used by nearly any LLM to connect with practically any external resource.
Building User Trust
Retrieval-augmented generation gives models sources they can cite, like footnotes in a research paper, so users can check any claims. That builds trust.
What’s more, the technique can help models clear up ambiguity in a user query. It also reduces the possibility a model will make a wrong guess, a phenomenon sometimes called hallucination.
Another great advantage of RAG is it’s relatively easy. A blog by Lewis and three of the paper’s coauthors said developers can implement the process with as few as five lines of code.
That makes the method faster and less expensive than retraining a model with additional datasets. And it lets users hot-swap new sources on the fly.
How People Are Using RAG
With retrieval-augmented generation, users can essentially have conversations with data repositories, opening up new kinds of experiences. This means the applications for RAG could be multiple times the number of available datasets.
For example, a generative AI model supplemented with a medical index could be a great assistant for a doctor or nurse. Financial analysts would benefit from an assistant linked to market data.
In fact, almost any business can turn its technical or policy manuals, videos or logs into resources called knowledge bases that can enhance LLMs. These sources can enable use cases such as customer or field support, employee training and developer productivity.
The broad potential is why companies including AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle and Pinecone are adopting RAG.
Getting Started With Retrieval-Augmented Generation
To help users get started, NVIDIA developed an AI Blueprint for building virtual assistants. Organizations can use this reference architecture to quickly scale their customer service operations with generative AI and RAG, or get started building a new customer-centric solution.
The blueprint uses some of the latest AI-building methodologies and NVIDIA NeMo Retriever, a collection of easy-to-use NVIDIA NIM microservices for large-scale information retrieval. NIM eases the deployment of secure, high-performance AI model inferencing across clouds, data centers and workstations.
These components are all part of NVIDIA AI Enterprise, a software platform that accelerates the development and deployment of production-ready AI with the security, support and stability businesses need.
There is also a free hands-on NVIDIA LaunchPad lab for developing AI chatbots using RAG so developers and IT teams can quickly and accurately generate responses based on enterprise data.
Getting the best performance for RAG workflows requires massive amounts of memory and compute to move and process data. The NVIDIA GH200 Grace Hopper Superchip, with its 288GB of fast HBM3e memory and 8 petaflops of compute, is ideal — it can deliver a 150x speedup over using a CPU.
Once companies get familiar with RAG, they can combine a variety of off-the-shelf or custom LLMs with internal or external knowledge bases to create a wide range of assistants that help their employees and customers.
RAG doesn’t require a data center. LLMs are debuting on Windows PCs, thanks to NVIDIA software that enables all sorts of applications users can access even on their laptops.
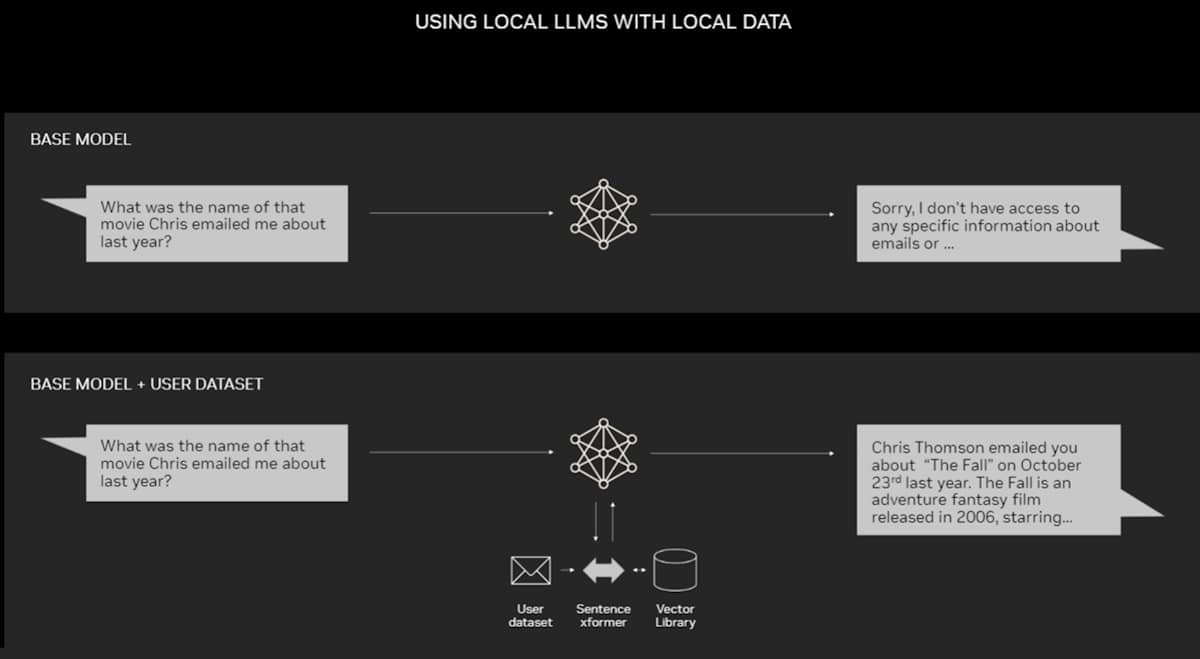
PCs equipped with NVIDIA RTX GPUs can now run some AI models locally. By using RAG on a PC, users can link to a private knowledge source – whether that be emails, notes or articles – to improve responses. The user can then feel confident that their data source, prompts and response all remain private and secure.
A recent blog provides an example of RAG accelerated by TensorRT-LLM for Windows to get better results fast.
The History of RAG
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use natural language processing (NLP) to access text, initially in narrow topics such as baseball.
The concepts behind this kind of text mining have remained fairly constant over the years. But the machine learning engines driving them have grown significantly, increasing their usefulness and popularity.
In the mid-1990s, the Ask Jeeves service, now Ask.com, popularized question answering with its mascot of a well-dressed valet. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy! game show.
Today, LLMs are taking question-answering systems to a whole new level.
Insights From a London Lab
The seminal 2020 paper arrived as Lewis was pursuing a doctorate in NLP at University College London and working for Meta at a new London AI lab. The team was searching for ways to pack more knowledge into an LLM’s parameters and using a benchmark it developed to measure its progress.
Building on earlier methods and inspired by a paper from Google researchers, the group “had this compelling vision of a trained system that had a retrieval index in the middle of it, so it could learn and generate any text output you wanted,” Lewis recalled.

When Lewis plugged into the work in progress a promising retrieval system from another Meta team, the first results were unexpectedly impressive.
“I showed my supervisor and he said, ‘Whoa, take the win. This sort of thing doesn’t happen very often,’ because these workflows can be hard to set up correctly the first time,” he said.
Lewis also credits major contributions from team members Ethan Perez and Douwe Kiela, then of New York University and Facebook AI Research, respectively.
When complete, the work, which ran on a cluster of NVIDIA GPUs, showed how to make generative AI models more authoritative and trustworthy. It’s since been cited by hundreds of papers that amplified and extended the concepts in what continues to be an active area of research.
How Retrieval-Augmented Generation Works
At a high level, here’s how an NVIDIA technical brief describes the RAG process.
When users ask an LLM a question, the AI model sends the query to another model that converts it into a numeric format so machines can read it. The numeric version of the query is sometimes called an embedding or a vector.
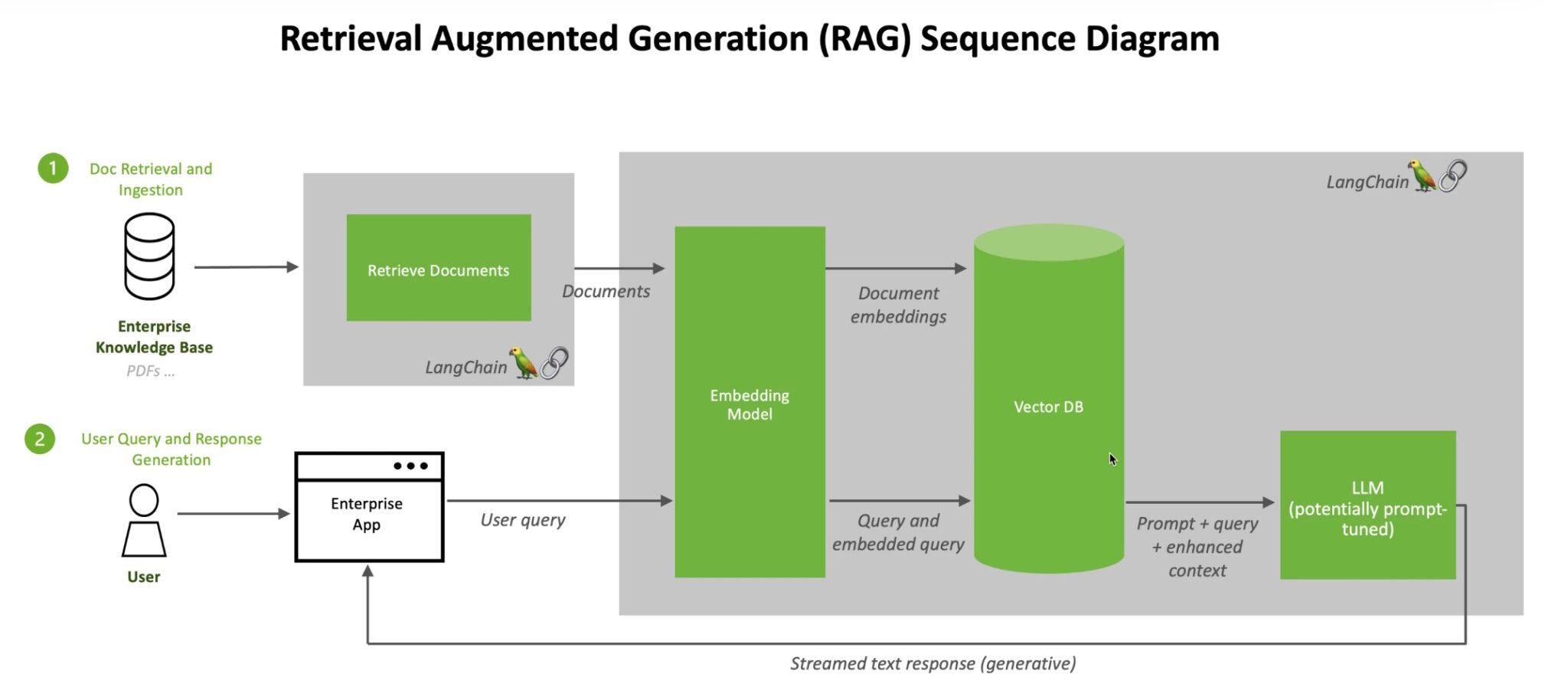
The embedding model then compares these numeric values to vectors in a machine-readable index of an available knowledge base. When it finds a match or multiple matches, it retrieves the related data, converts it to human-readable words and passes it back to the LLM.
Finally, the LLM combines the retrieved words and its own response to the query into a final answer it presents to the user, potentially citing sources the embedding model found.
Keeping Sources Current
In the background, the embedding model continuously creates and updates machine-readable indices, sometimes called vector databases, for new and updated knowledge bases as they become available.
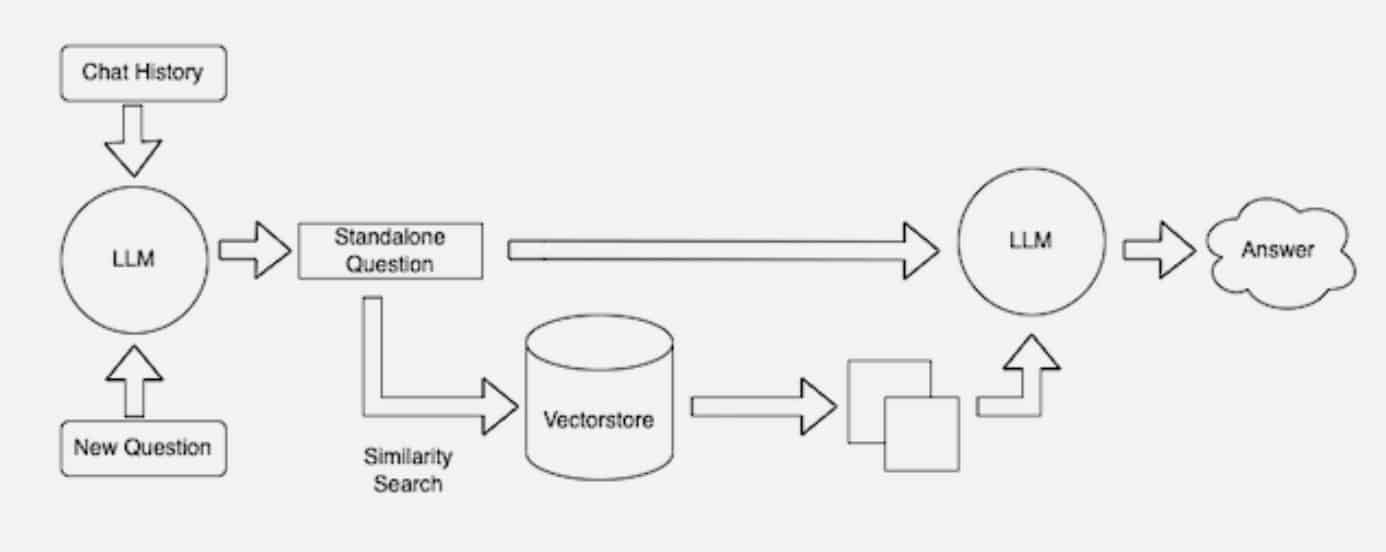
Many developers find LangChain, an open-source library, can be particularly useful in chaining together LLMs, embedding models and knowledge bases. NVIDIA uses LangChain in its reference architecture for retrieval-augmented generation.
The LangChain community provides its own description of a RAG process.
Looking forward, the future of generative AI lies in creatively chaining all sorts of LLMs and knowledge bases together to create new kinds of assistants that deliver authoritative results users can verify.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.
]]>Cloud-native technologies have become crucial for developers to create and implement scalable applications in dynamic cloud environments.
This week at KubeCon + CloudNativeCon North America 2024, one of the most-attended conferences focused on open-source technologies, Chris Lamb, vice president of computing software platforms at NVIDIA, delivered a keynote outlining the benefits of open source for developers and enterprises alike — and NVIDIA offered nearly 20 interactive sessions with engineers and experts.
The Cloud Native Computing Foundation (CNCF), part of the Linux Foundation and host of KubeCon, is at the forefront of championing a robust ecosystem to foster collaboration among industry leaders, developers and end users.
As a member of CNCF since 2018, NVIDIA is working across the developer community to contribute to and sustain cloud-native open-source projects. Our open-source software and more than 750 NVIDIA-led open-source projects help democratize access to tools that accelerate AI development and innovation.
Empowering Cloud-Native Ecosystems
NVIDIA has benefited from the many open-source projects under CNCF and has made contributions to dozens of them over the past decade. These actions help developers as they build applications and microservice architectures aligned with managing AI and machine learning workloads.
Kubernetes, the cornerstone of cloud-native computing, is undergoing a transformation to meet the challenges of AI and machine learning workloads. As organizations increasingly adopt large language models and other AI technologies, robust infrastructure becomes paramount.
NVIDIA has been working closely with the Kubernetes community to address these challenges. This includes:
- Work on dynamic resource allocation (DRA) that allows for more flexible and nuanced resource management. This is crucial for AI workloads, which often require specialized hardware. NVIDIA engineers played a key role in designing and implementing this feature.
- Leading efforts in KubeVirt, an open-source project extending Kubernetes to manage virtual machines alongside containers. This provides a unified, cloud-native approach to managing hybrid infrastructure.
- Development of NVIDIA GPU Operator, which automates the lifecycle management of NVIDIA GPUs in Kubernetes clusters. This software simplifies the deployment and configuration of GPU drivers, runtime and monitoring tools, allowing organizations to focus on building AI applications rather than managing infrastructure.
The company’s open-source efforts extend beyond Kubernetes to other CNCF projects:
- NVIDIA is a key contributor to Kubeflow, a comprehensive toolkit that makes it easier for data scientists and engineers to build and manage ML systems on Kubernetes. Kubeflow reduces the complexity of infrastructure management and allows users to focus on developing and improving ML models.
- NVIDIA has contributed to the development of CNAO, which manages the lifecycle of host networks in Kubernetes clusters.
- NVIDIA has also added to Node Health Check, which provides virtual machine high availability.
And NVIDIA has assisted with projects that address the observability, performance and other critical areas of cloud-native computing, such as:
- Prometheus: Enhancing monitoring and alerting capabilities
- Envoy: Improving distributed proxy performance
- OpenTelemetry: Advancing observability in complex, distributed systems
- Argo: Facilitating Kubernetes-native workflows and application management
Community Engagement
NVIDIA engages the cloud-native ecosystem by participating in CNCF events and activities, including:
- Collaboration with cloud service providers to help them onboard new workloads.
- Participation in CNCF’s special interest groups and working groups on AI discussions.
- Participation in industry events such as KubeCon + CloudNativeCon, where it shares insights on GPU acceleration for AI workloads.
- Work with CNCF-adjacent projects in the Linux Foundation as well as many partners.
This translates into extended benefits for developers, such as improved efficiency in managing AI and ML workloads; enhanced scalability and performance of cloud-native applications; better resource utilization, which can lead to cost savings; and simplified deployment and management of complex AI infrastructures.
As AI and machine learning continue to transform industries, NVIDIA is helping advance cloud-native technologies to support compute-intensive workloads. This includes facilitating the migration of legacy applications and supporting the development of new ones.
These contributions to the open-source community help developers harness the full potential of AI technologies and strengthen Kubernetes and other CNCF projects as the tools of choice for AI compute workloads.
Check out NVIDIA’s keynote at KubeCon + CloudNativeCon North America 2024 delivered by Chris Lamb, where he discusses the importance of CNCF projects in building and delivering AI in the cloud and NVIDIA’s contributions to the community to push the AI revolution forward.
]]>Working with NVIDIA and its partners, Indonesia’s technology leaders have launched an initiative to bring sovereign AI to the nation’s more than 277 million Indonesian speakers.
The collaboration is grounded in a broad public-private partnership that reflects the nation’s concept of “gotong royong,” a term describing a spirit of mutual assistance and community collaboration.
NVIDIA founder and CEO Jensen Huang joined Indonesia Minster for State-Owned Enterprises Erick Thohir, Indosat Ooredoo Hutchison (IOH) President Director and CEO Vikram Sinha, GoTo CEO Patrick Walujo and other leaders in Jakarta to celebrate the launch of Sahabat-AI.
Sahabat-AI is a collection of open-source Indonesian large language models (LLMs) that local industries, government agencies, universities and research centers can use to create generative AI applications. Built with NVIDIA NeMo and NVIDIA NIM microservices, the models were launched today at Indonesia AI Day, a conference focused on enabling AI sovereignty and driving AI-driven digital independence in the country.
Built by Indonesians, for Indonesians, Sahabat-AI models understand local contexts and enable people to build generative AI services and applications in Bahasa Indonesian and various local languages. The models form the foundation of a collaborative effort to empower Indonesia through a locally developed, open-source LLM ecosystem.
“Artificial intelligence will democratize technology. It is the great equalizer,” said Huang. “The technology is complicated but the benefit is not.”
“Sahabat-AI is not just a technological achievement, it embodies Indonesia’s vision for a future where digital sovereignty and inclusivity go hand in hand,” Sinha said. “By creating an AI model that speaks our language and reflects our culture, we’re empowering every Indonesian to harness advanced technology’s potential. This initiative is a crucial step toward democratizing AI as a tool for growth, innovation and empowerment across our diverse society.”
To accelerate this initiative, IOH — one of Indonesia’s largest telecom and internet companies — earlier this year launched “GPU Merdeka by Lintasarta,” an NVIDIA-accelerated sovereign AI cloud. The GPU Merdeka cloud service operates at a BDx Indonesia AI data center powered by renewable energy.
Bolstered by the NVIDIA Cloud Partner program, IOH subsidiary Lintasarta built the high-performance AI cloud in less than three months, a feat that would’ve taken much longer without NVIDIA’s technology infrastructure. The AI cloud is now driving transformation across energy, financial services, healthcare and other industries.
The NVIDIA Cloud Partner (NCP) program provides Lintasarta with access to NVIDIA reference architectures — blueprints for building high-performance, scalable and secure data centers.
The program also offers technological and go-to-market support, access to the latest NVIDIA AI software and accelerated computing platforms, and opportunities to collaborate with NVIDIA’s extensive ecosystem of industry partners. These partners include global systems integrators like Accenture and Tech Mahindra and software companies like GoTo and Hippocratic AI, each of which is working alongside IOH to boost the telco’s sovereign AI initiatives.
Developing Industry-Specific Applications With Accenture
Partnering with leading professional services company Accenture, IOH is developing applications for industry-specific use cases based on its new AI cloud, Sahabat-AI and the NVIDIA AI Enterprise software platform.
NVIDIA CEO Huang joined Accenture CEO Julie Sweet in a fireside chat during Indonesia AI Day to discuss how the companies are supporting enterprise and industrial AI in Indonesia.
The collaboration taps into the Accenture AI Refinery platform to help Indonesian enterprises build AI solutions tailored for financial services, energy and other industries, while delivering sovereign data governance.
Initially focused on financial services, IOH’s work with Accenture and NVIDIA technologies is delivering pre-built enterprise solutions that can help Indonesian banks more quickly harness AI.
With a modular architecture, these solutions can meet clients’ needs wherever they are in their AI journeys, helping increase profitability, operational efficiency and sustainable growth.
Building the Indonesian LLM and Chatbot Services With Tech Mahindra
Built with India-based global systems integrator Tech Mahindra, the Sahabat-AI LLMs power various AI services in Indonesia.
For example, Sahabat-AI enables IOH’s AI chatbot to answer queries in the Indonesian language for various citizen and resident services. A person could ask about processes for updating their national identification card, as well as about tax rates, payment procedures, deductions and more.
The chatbot integrates with a broader citizen services platform Tech Mahindra and IOH are developing as part of the Indonesian government’s sovereign AI initiative.
Indosat developed Sahabat-AI using the NVIDIA NeMo platform for developing customized LLMs. The team fine-tuned a version of the Llama 3 8B model, customizing it for Bahasa Indonesian using a diverse dataset tailored for effective communication with users.
To further optimize performance, Sahabat-AI uses NVIDIA NIM microservices, which have demonstrated up to 2.5x greater throughput compared with standard implementations. This improvement in processing efficiency allows for faster responses and more satisfying user experiences.
In addition, NVIDIA NeMo Guardrails open-source software orchestrates dialog management and helps ensure accuracy, appropriateness and security of the LLM-based chatbot.
Many other service capabilities tapping Sahabat-AI are also planned for development, including AI-powered healthcare services and other local applications.
Improving Indonesian Healthcare With Hippocratic AI
Among the first to tap into Sahabat-AI is healthcare AI company Hippocratic AI, which is using the models, the NVIDIA AI platform and IOH’s sovereign AI cloud to develop digital agents that can have humanlike conversations, exhibit empathic qualities, and build rapport and trust with patients across Indonesia.
Hippocratic AI empowers a novel trillion-parameter constellation architecture that brings together specialized healthcare LLM agents to deliver safe, accurate digital agent implementation.
Digital AI agents can significantly increase staff productivity by offloading time-consuming tasks, allowing human nurses and medical professionals to focus on critical duties to increase healthcare accessibility and quality of service.
IOH’s sovereign AI cloud lets Hippocratic AI keep patient data local and secure, and enables extremely low-latency AI inference for its LLMs.
Enhancing Simplicity, Accessibility for On-Demand and Financial Services With GoTo
GoTo offers technology infrastructure and solutions that help users thrive in the digital economy, including through applications spanning on-demand services for transport, food, grocery and logistics delivery, financial services and e-commerce.
The company — which operates one of Indonesia’s leading on-demand transport services, as well as a leading payment application in the country — is adopting and enhancing the new Sahabat-AI models to integrate with its AI voice assistant, called Dira.
Dira is a speech and generative AI-powered digital assistant that helps customers book rides, order food deliveries, transfer money, pay bills and more.
Tapping into Sahabat-AI, Dira is poised to deliver more localized and culturally relevant interactions with application users.
Advancing Sustainability Within Lintasarta as IOH’s AI Factory
Fundamentally, Lintasarta’s AI cloud is an AI factory — a next-generation data center that hosts advanced, full-stack accelerated computing platforms for the most computationally intensive tasks. It’ll enable regional governments, businesses and startups to build, customize and deploy generative AI applications aligned with local language and customs.
Looking forward, Lintasarta plans to expand its AI factory with the most advanced NVIDIA technologies. The infrastructure already boasts a “green” design, powered by renewable energy and sustainable technologies. Lintasarta is committed to adding value to Indonesia’s digital ecosystem with integrated, secure and sustainable technology, in line with the Golden Indonesia 2045 vision.
Beyond Indonesia, NVIDIA NIM microservices are bolstering sovereign AI models that support local languages in India, Japan, Taiwan and many other countries and regions.
NVIDIA NIM microservices, NeMo and NeMo Guardrails are available as part of the NVIDIA AI Enterprise software platform.
Learn more about NVIDIA-powered sovereign AI factories for telecommunications.
See notice regarding software product information.
]]>Since the advent of the computer age, industries have been so awash in stored data that most of it never gets put to use.
This data is estimated to be in the neighborhood of 120 zettabytes — the equivalent of trillions of terabytes, or more than 120x the amount of every grain of sand on every beach around the globe. Now, the world’s industries are putting that untamed data to work by building and customizing large language models (LLMs).
As 2025 approaches, industries such as healthcare, telecommunications, entertainment, energy, robotics, automotive and retail are using those models, combining it with their proprietary data and gearing up to create AI that can reason.
The NVIDIA experts below focus on some of the industries that deliver $88 trillion worth of goods and services globally each year. They predict that AI that can harness data at the edge and deliver near-instantaneous insights is coming to hospitals, factories, customer service centers, cars and mobile devices near you.
But first, let’s hear AI’s predictions for AI. When asked, “What will be the top trends in AI in 2025 for industries?” both Perplexity and ChatGPT 4.0 responded that agentic AI sits atop the list alongside edge AI, AI cybersecurity and AI-driven robots.
Agentic AI is a new category of generative AI that operates virtually autonomously. It can make complex decisions and take actions based on continuous learning and analysis of vast datasets. Agentic AI is adaptable, has defined goals and can correct itself, and can chat with other AI agents or reach out to a human for help.
Now, hear from NVIDIA experts on what to expect in the year ahead:

Kimberly Powell
Vice President of Healthcare
Human-robotic interaction: Robots will assist human clinicians in a variety of ways, from understanding and responding to human commands, to performing and assisting in complex surgeries.
It’s being made possible by digital twins, simulation and AI that train and test robotic systems in virtual environments to reduce risks associated with real-world trials. It also can train robots to react in virtually any scenario, enhancing their adaptability and performance across different clinical situations.
New virtual worlds for training robots to perform complex tasks will make autonomous surgical robots a reality. These surgical robots will perform complex surgical tasks with precision, reducing patient recovery times and decreasing the cognitive workload for surgeons.
Digital health agents: The dawn of agentic AI and multi-agent systems will address the existential challenges of workforce shortages and the rising cost of care.
Administrative health services will become digital humans taking notes for you or making your next appointment — introducing an era of services delivered by software and birthing a service-as-a-software industry.
Patient experience will be transformed with always-on, personalized care services while healthcare staff will collaborate with agents that help them reduce clerical work, retrieve and summarize patient histories, and recommend clinical trials and state-of-the-art treatments for their patients.
Drug discovery and design AI factories: Just as ChatGPT can generate an email or a poem without putting a pen to paper for trial and error, generative AI models in drug discovery can liberate scientific thinking and exploration.
Techbio and biopharma companies have begun combining models that generate, predict and optimize molecules to explore the near-infinite possible target drug combinations before going into time-consuming and expensive wet lab experiments.
The drug discovery and design AI factories will consume all wet lab data, refine AI models and redeploy those models — improving each experiment by learning from the previous one. These AI factories will shift the industry from a discovery process to a design and engineering one.
 Rev Lebaredian
Rev Lebaredian
Vice President of Omniverse and Simulation Technology
Let’s get physical (AI, that is): Getting ready for AI models that can perceive, understand and interact with the physical world is one challenge enterprises will race to tackle.
While LLMs require reinforcement learning largely in the form of human feedback, physical AI needs to learn in a “world model” that mimics the laws of physics. Large-scale physically based simulations are allowing the world to realize the value of physical AI through robots by accelerating the training of physical AI models and enabling continuous training in robotic systems across every industry.
Cheaper by the dozen: In addition to their smarts (or lack thereof), one big factor that has slowed adoption of humanoid robots has been affordability. As agentic AI brings new intelligence to robots, though, volume will pick up and costs will come down sharply. The average cost of industrial robots is expected to drop to $10,800 in 2025, down sharply from $46K in 2010 to $27K in 2017. As these devices become significantly cheaper, they’ll become as commonplace across industries as mobile devices are.
 Deepu Talla
Deepu Talla
Vice President of Robotics and Edge Computing
Redefining robots: When people think of robots today, they’re usually images or content showing autonomous mobile robots (AMRs), manipulator arms or humanoids. But tomorrow’s robots are set to be an autonomous system that perceives, reasons, plans and acts — then learns.
Soon we’ll be thinking of robots embodied everywhere from surgical rooms and data centers to warehouses and factories. Even traffic control systems or entire cities will be transformed from static, manually operated systems to autonomous, interactive systems embodied by physical AI.
The rise of small language models: To improve the functionality of robots operating at the edge, expect to see the rise of small language models that are energy-efficient and avoid latency issues associated with sending data to data centers. The shift to small language models in edge computing will improve inference in a range of industries, including automotive, retail and advanced robotics.
 Kevin Levitt
Kevin Levitt
Global Director of Financial Services
AI agents boost firm operations: AI-powered agents will be deeply integrated into the financial services ecosystem, improving customer experiences, driving productivity and reducing operational costs.
AI agents will take every form based on each financial services firm’s needs. Human-like 3D avatars will take requests and interact directly with clients, while text-based chatbots will summarize thousands of pages of data and documents in seconds to deliver accurate, tailored insights to employees across all business functions.
AI factories become table stakes: AI use cases in the industry are exploding. This includes improving identity verification for anti-money laundering and know-your-customer regulations, reducing false positives for transaction fraud and generating new trading strategies to improve market returns. AI also is automating document management, reducing funding cycles to help consumers and businesses on their financial journeys.
To capitalize on opportunities like these, financial institutions will build AI factories that use full-stack accelerated computing to maximize performance and utilization to build AI-enabled applications that serve hundreds, if not thousands, of use cases — helping set themselves apart from the competition.
AI-assisted data governance: Due to the sensitive nature of financial data and stringent regulatory requirements, governance will be a priority for firms as they use data to create reliable and legal AI applications, including for fraud detection, predictions and forecasting, real-time calculations and customer service.
Firms will use AI models to assist in the structure, control, orchestration, processing and utilization of financial data, making the process of complying with regulations and safeguarding customer privacy smoother and less labor intensive. AI will be the key to making sense of and deriving actionable insights from the industry’s stockpile of underutilized, unstructured data.
 Richard Kerris
Richard Kerris
Vice President of Media and Entertainment
Let AI entertain you: AI will continue to revolutionize entertainment with hyperpersonalized content on every screen, from TV shows to live sports. Using generative AI and advanced vision-language models, platforms will offer immersive experiences tailored to individual tastes, interests and moods. Imagine teaser images and sizzle reels crafted to capture the essence of a new show or live event and create an instant personal connection.
In live sports, AI will enhance accessibility and cultural relevance, providing language dubbing, tailored commentary and local adaptations. AI will also elevate binge-watching by adjusting pacing, quality and engagement options in real time to keep fans captivated. This new level of interaction will transform streaming from a passive experience into an engaging journey that brings people closer to the action and each other.
AI-driven platforms will also foster meaningful connections with audiences by tailoring recommendations, trailers and content to individual preferences. AI’s hyperpersonalization will allow viewers to discover hidden gems, reconnect with old favorites and feel seen. For the industry, AI will drive growth and innovation, introducing new business models and enabling global content strategies that celebrate unique viewer preferences, making entertainment feel boundless, engaging and personally crafted.
 Ronnie Vasishta
Ronnie Vasishta
Senior Vice President of Telecoms
The AI connection: Telecommunications providers will begin to deliver generative AI applications and 5G connectivity over the same network. AI radio access network (AI-RAN) will enable telecom operators to transform traditional single-purpose base stations from cost centers into revenue-producing assets capable of providing AI inference services to devices, while more efficiently delivering the best network performance.
AI agents to the rescue: The telecommunications industry will be among the first to dial into agentic AI to perform key business functions. Telco operators will use AI agents for a wide variety of tasks, from suggesting money-saving plans to customers and troubleshooting network connectivity, to answering billing questions and processing payments.
More efficient, higher-performing networks: AI also will be used at the wireless network layer to enhance efficiency, deliver site-specific learning and reduce power consumption. Using AI as an intelligent performance improvement tool, operators will be able to continuously observe network traffic, predict congestion patterns and make adjustments before failures happen, allowing for optimal network performance.
Answering the call on sovereign AI: Nations will increasingly turn to telcos — which have proven experience managing complex, distributed technology networks — to achieve their sovereign AI objectives. The trend will spread quickly across Europe and Asia, where telcos in Switzerland, Japan, Indonesia and Norway are already partnering with national leaders to build AI factories that can use proprietary, local data to help researchers, startups, businesses and government agencies create AI applications and services.
 Xinzhou Wu
Xinzhou Wu
Vice President of Automotive
Pedal to generative AI metal: Autonomous vehicles will become more performant as developers tap into advancements in generative AI. For example, harnessing foundation models, such as vision language models, provides an opportunity to use internet-scale knowledge to solve one of the hardest problems in the autonomous vehicle (AV) field, namely that of efficiently and safely reasoning through rare corner cases.
Simulation unlocks success: More broadly, new AI-based tools will enable breakthroughs in how AV development is carried out. For example, advances in generative simulation will enable the scalable creation of complex scenarios aimed at stress-testing vehicles for safety purposes. Aside from allowing for testing unusual or dangerous conditions, simulation is also essential for generating synthetic data to enable end-to-end model training.
Three-computer approach: Effectively, new advances in AI will catalyze AV software development across the three key computers underpinning AV development — one for training the AI-based stack in the data center, another for simulation and validation, and a third in-vehicle computer to process real-time sensor data for safe driving. Together, these systems will enable continuous improvement of AV software for enhanced safety and performance of cars, trucks, robotaxis and beyond.
 Marc Spieler
Marc Spieler
Senior Managing Director of Global Energy Industry
Welcoming the smart grid: Do you know when your daily peak home electricity is? You will soon as utilities around the world embrace smart meters that use AI to broadly manage their grid networks, from big power plants and substations and, now, into the home.
As the smart grid takes shape, smart meters — once deemed too expensive to be installed in millions of homes — that combine software, sensors and accelerated computing will alert utilities when trees in a backyard brush up against power lines or when to offer big rebates to buy back the excess power stored through rooftop solar installations.
Powering up: Delivering the optimal power stack has always been mission-critical for the energy industry. In the era of generative AI, utilities will address this issue in ways that reduce environmental impact.
Expect in 2025 to see a broader embrace of nuclear power as one clean-energy path the industry will take. Demand for natural gas also will grow as it replaces coal and other forms of energy. These resurgent forms of energy are being helped by the increased use of accelerated computing, simulation technology and AI and 3D visualization, which helps optimize design, pipeline flows and storage. We’ll see the same happening at oil and gas companies, which are looking to reduce the impact of energy exploration and production.
 Azita Martin
Azita Martin
Vice President of Retail, Consumer-Packaged Goods and Quick-Service Restaurants
Software-defined retail: Supercenters and grocery stores will become software-defined, each running computer vision and sophisticated AI algorithms at the edge. The transition will accelerate checkout, optimize merchandising and reduce shrink — the industry term for a product being lost or stolen.
Each store will be connected to a headquarters AI network, using collective data to become a perpetual learning machine. Software-defined stores that continually learn from their own data will transform the shopping experience.
Intelligent supply chain: Intelligent supply chains created using digital twins, generative AI, machine learning and AI-based solvers will drive billions of dollars in labor productivity and operational efficiencies. Digital twin simulations of stores and distribution centers will optimize layouts to increase in-store sales and accelerate throughput in distribution centers.
Agentic robots working alongside associates will load and unload trucks, stock shelves and pack customer orders. Also, last-mile delivery will be enhanced with AI-based routing optimization solvers, allowing products to reach customers faster while reducing vehicle fuel costs.
]]>Generative AI applications that use text, computer code, protein chains, summaries, video and even 3D graphics require data-center-scale accelerated computing to efficiently train the large language models (LLMs) that power them.
In MLPerf Training 4.1 industry benchmarks, the NVIDIA Blackwell platform delivered impressive results on workloads across all tests — and up to 2.2x more performance per GPU on LLM benchmarks, including Llama 2 70B fine-tuning and GPT-3 175B pretraining.
In addition, NVIDIA’s submissions on the NVIDIA Hopper platform continued to hold at-scale records on all benchmarks, including a submission with 11,616 Hopper GPUs on the GPT-3 175B benchmark.
Leaps and Bounds With Blackwell
The first Blackwell training submission to the MLCommons Consortium — which creates standardized, unbiased and rigorously peer-reviewed testing for industry participants — highlights how the architecture is advancing generative AI training performance.
For instance, the architecture includes new kernels that make more efficient use of Tensor Cores. Kernels are optimized, purpose-built math operations like matrix-multiplies that are at the heart of many deep learning algorithms.
Blackwell’s higher per-GPU compute throughput and significantly larger and faster high-bandwidth memory allows it to run the GPT-3 175B benchmark on fewer GPUs while achieving excellent per-GPU performance.
Taking advantage of larger, higher-bandwidth HBM3e memory, just 64 Blackwell GPUs were able to run in the GPT-3 LLM benchmark without compromising per-GPU performance. The same benchmark run using Hopper needed 256 GPUs.
The Blackwell training results follow an earlier submission to MLPerf Inference 4.1, where Blackwell delivered up to 4x more LLM inference performance versus the Hopper generation. Taking advantage of the Blackwell architecture’s FP4 precision, along with the NVIDIA QUASAR Quantization System, the submission revealed powerful performance while meeting the benchmark’s accuracy requirements.
Relentless Optimization
NVIDIA platforms undergo continuous software development, racking up performance and feature improvements in training and inference for a wide variety of frameworks, models and applications.
In this round of MLPerf training submissions, Hopper delivered a 1.3x improvement on GPT-3 175B per-GPU training performance since the introduction of the benchmark.
NVIDIA also submitted large-scale results on the GPT-3 175B benchmark using 11,616 Hopper GPUs connected with NVIDIA NVLink and NVSwitch high-bandwidth GPU-to-GPU communication and NVIDIA Quantum-2 InfiniBand networking.
NVIDIA Hopper GPUs have more than tripled scale and performance on the GPT-3 175B benchmark since last year. In addition, on the Llama 2 70B LoRA fine-tuning benchmark, NVIDIA increased performance by 26% using the same number of Hopper GPUs, reflecting continued software enhancements.
NVIDIA’s ongoing work on optimizing its accelerated computing platforms enables continued improvements in MLPerf test results — driving performance up in containerized software, bringing more powerful computing to partners and customers on existing platforms and delivering more return on their platform investment.
Partnering Up
NVIDIA partners, including system makers and cloud service providers like ASUSTek, Azure, Cisco, Dell, Fujitsu, Giga Computing, Lambda Labs, Lenovo, Oracle Cloud, Quanta Cloud Technology and Supermicro also submitted impressive results to MLPerf in this latest round.
A founding member of MLCommons, NVIDIA sees the role of industry-standard benchmarks and benchmarking best practices in AI computing as vital. With access to peer-reviewed, streamlined comparisons of AI and HPC platforms, companies can keep pace with the latest AI computing innovations and access crucial data that can help guide important platform investment decisions.
Learn more about the latest MLPerf results on the NVIDIA Technical Blog.
]]>To provide high-quality medical care to its population — around 30% of whom are 65 or older — Japan is pursuing sovereign AI initiatives supporting nearly every aspect of healthcare.
AI tools trained on country-specific data and local compute infrastructure are supercharging the abilities of Japan’s clinicians and researchers so they can care for patients, amid an expected shortage of nearly 500,000 healthcare workers by next year.
Breakthrough technology deployments by the country’s healthcare leaders — including in AI-accelerated drug discovery, genomic medicine, healthcare imaging and robotics — are highlighted at the NVIDIA AI Summit Japan, taking place in Tokyo through Nov. 13.
Powered by NVIDIA AI computing platforms like the Tokyo-1 NVIDIA DGX supercomputer, these applications were developed using domain-specific platforms such as NVIDIA BioNeMo for drug discovery, NVIDIA MONAI for medical imaging, NVIDIA Parabricks for genomics and NVIDIA Holoscan for healthcare robotics.
Drug Discovery AI Factories Deepen Understanding, Accuracy and Speed
NVIDIA is supporting Japan’s pharmaceutical market — one of the three largest in the world — with NVIDIA BioNeMo, an end-to-end platform that enables drug discovery researchers to develop and deploy AI models for generating biological intelligence from biomolecular data.
BioNeMo includes a customizable, modular programming framework and NVIDIA NIM microservices for optimized AI inference. New models include AlphaFold2, which predicts the 3D structure of a protein from its amino acid sequence; DiffDock, which predicts the 3D structure of a molecule interacting with a protein; and RFdiffusion, which designs novel protein structures likely to bind with a target molecule.
The platform also features BioNeMo Blueprints, a catalog of customizable reference AI workflows to help developers scale biomolecular AI models to enterprise-grade applications.
The NIM microservice for AlphaFold2 now integrates MMSeqs2-GPU, an evolutionary information retrieval tool that accelerates the traditional AlphaFold2 pipeline by 5x. Led by researchers at Seoul National University, Johannes Gutenberg University Mainz and NVIDIA, this integration enables protein structure prediction in 8 minutes instead of 40 minutes.
At AI Summit Japan, TetraScience, a company that engineers AI-native scientific datasets, announced a collaboration with NVIDIA to industrialize the production of scientific AI use cases to accelerate and improve workflows across the life sciences value chain.
For example, choosing an optimal cell line to produce biologic therapies such as vaccines and monoclonal antibodies is a critical but time-consuming step. TetraScience’s new Lead Clone Assistant uses BioNeMo tools, including the NVIDIA VISTA-2D foundation model for cell segmentation and the Geneformer model for gene expression analysis, to reduce lead clone selection to hours instead of weeks.
Tokyo-based Astellas Pharma uses BioNeMo biomolecular AI models such as ESM-1nv, ESM-2nv and DNABERT to accelerate biologics research. Its AI models are used to generate novel molecular structures, predict how those molecules will bind to target proteins and optimize them to more effectively bind to those target proteins.
Using the BioNeMo framework, Astellas has accelerated chemical molecule generation by more than 30x. The company plans to use BioNeMo NIM microservices to further advance its work.
Japan’s Pharma Companies and Research Institutions Advance Drug Research and Development
Astellas, Daiichi-Sankyo and Ono Pharmaceutical are leading Japanese pharma companies harnessing the Tokyo-1 system, an NVIDIA DGX AI supercomputer built in collaboration with Xeureka, a subsidiary of the Japanese business conglomerate Mitsui & Co, to build AI models for drug discovery. Xeureka is using Tokyo-1 to accelerate AI model development and molecular simulations.
Xeureka is also using NVIDIA H100 Tensor Core GPUs to explore the application of confidential computing to enhance the ability of pharmaceutical companies to collaborate on large AI model training while protecting proprietary datasets.
To further support disease and precision medicine research, genomics researchers across Japan have adopted the NVIDIA Parabricks software suite to accelerate secondary analysis of DNA and RNA data.
Among them is the University of Tokyo Human Genome Center, the main academic institution working on a government-led whole genome project focused on cancer research. The initiative will help researchers identify gene variants unique to Japan’s population and support the development of precision therapeutics.
The genome center is also exploring the use of Giraffe, a tool now available via Parabricks v4.4 that enables researchers to map genome sequences to a pangenome, a reference genome that represents diverse populations.
AI Scanners and Scopes Give Radiologists and Surgeons Real-Time Superpowers
Japan’s healthcare innovators are building AI-augmented systems to support radiologists and surgeons.
Fujifilm has developed an AI application in collaboration with NVIDIA to help surgeons perform surgery more efficiently.
This application uses an AI model developed using NVIDIA DGX systems to convert CT images into 3D simulations to support surgery.
Olympus recently collaborated with NVIDIA and telecommunications company NTT to demonstrate how cloud-connected endoscopes can efficiently run image processing and AI applications in real time. The endoscopes featured NVIDIA Jetson Orin modules for edge computing and connected to a cloud server using the NTT communication platform’s IOWN All-Photonics Network, which introduces photonics-based technology across the network to enable lower power consumption, greater capacity and lower latency.
NVIDIA is also supporting real-time AI-powered robotic systems for radiology and surgery in Japan with Holoscan, a sensor processing platform that streamlines AI model and application development for real-time insights. Holoscan includes a catalog of AI reference workflows for applications including endoscopy and ultrasound analysis.
A neurosurgeon at Showa University, a medical school with multiple campuses across Japan, has adopted Holoscan and the NVIDIA IGX platform for industrial-grade edge AI to develop a surgical microscopy application that takes video footage from surgical scopes and converts it into 3D imagery in real time using AI. With access to 3D reconstructions, surgeons can more easily locate tumors and key structures in the brain to improve the efficiency of procedures.
Japanese surgical AI companies including AI Medical Service (AIM), Anaut, iMed Technologies and Jmees are investigating the use of Holoscan to power applications that provide diagnostic support for endoscopists and surgeons. These applications could detect anatomical structures like organs in real time, with the potential to reduce injury risks, identify conditions such as gastrointestinal cancers and brain hemorrhages, and provide immediate insights to help doctors prepare for and conduct surgeries.
Scaling Healthcare With Digital Health Agents
Older adults have higher rates of chronic conditions and use healthcare services the most — so to keep up with its aging population, Japan-based companies are at the forefront of developing digital health systems to augment patient care.
Fujifilm has launched NURA, a group of health screening centers with AI-augmented medical examinations designed to help doctors test for cancer and chronic diseases with faster examinations and lower radiation doses for CT scans.
Developed using NVIDIA DGX systems, the tool incorporates large language models that create text summaries of medical images. The AI models run on NVIDIA RTX GPUs for inference. Fujifilm is also evaluating the use of MONAI, NeMo and NIM microservices.
To learn more about NVIDIA’s collaborations with Japan’s healthcare ecosystem, watch the NVIDIA AI Summit on-demand session by Kimberly Powell, the company’s vice president of healthcare.
]]>Established 77 years ago, Mitsui & Co stays vibrant by building businesses and ecosystems with new technologies like generative AI and confidential computing.
Digital transformation takes many forms at the Tokyo-based conglomerate with 16 divisions. In one case, it’s an autonomous trucking service, in another it’s a geospatial analysis platform. Mitsui even collaborates with a partner at the leading edge of quantum computing.
One new subsidiary, Xeureka, aims to accelerate R&D in healthcare, where it can take more than a billion dollars spent over a decade to bring to market a new drug.
“We create businesses using new digital technology like AI and confidential computing,” said Katsuya Ito, a project manager in Mitsui’s digital transformation group. “Most of our work is done in collaboration with tech companies — in this case NVIDIA and Fortanix,” a San Francisco based security software company.
In Pursuit of Big Data
Though only three years old, Xeureka already completed a proof of concept addressing one of drug discovery’s biggest problems — getting enough data.
Speeding drug discovery requires powerful AI models built with datasets larger than most pharmaceutical companies have on hand. Until recently, sharing across companies has been unthinkable because data often contains private patient information as well as chemical formulas proprietary to the drug company.
Enter confidential computing, a way of processing data in a protected part of a GPU or CPU that acts like a black box for an organization’s most important secrets.
To ensure their data is kept confidential at all times, banks, government agencies and even advertisers are using the technology that’s backed by a consortium of some of the world’s largest companies.
A Proof of Concept for Privacy
To validate that confidential computing would allow its customers to safely share data, Xeureka created two imaginary companies, each with a thousand drug candidates. Each company’s dataset was used separately to train an AI model to predict the chemicals’ toxicity levels. Then the data was combined to train a similar, but larger AI model.
Xeureka ran its test on NVIDIA H100 Tensor Core GPUs using security management software from Fortanix, one of the first startups to support confidential computing.
The H100 GPUs support a trusted execution environment with hardware-based engines that ensure and validate confidential workloads are protected while in use on the GPU, without compromising performance. The Fortanix software manages data sharing, encryption keys and the overall workflow.
Up to 74% Higher Accuracy
The results were impressive. The larger model’s predictions were 65-74% more accurate, thanks to use of the combined datasets.
The models created by a single company’s data showed instability and bias issues that were not present with the larger model, Ito said.
“Confidential computing from NVIDIA and Fortanix essentially alleviates the privacy and security concerns while also improving model accuracy, which will prove to be a win-win situation for the entire industry,” said Xeureka’s CTO, Hiroki Makiguchi, in a Fortanix press release.
An AI Supercomputing Ecosystem
Now, Xeureka is exploring broad applications of this technology in drug discovery research, in collaboration with the community behind Tokyo-1, its GPU-accelerated AI supercomputer. Announced in February, Tokyo-1 aims to enhance the efficiency of pharmaceutical companies in Japan and beyond.
Initial projects may include collaborations to predict protein structures, screen ligand-base pairs and accelerate molecular dynamics simulations with trusted services. Tokyo-1 users can harness large language models for chemistry, protein, DNA and RNA data formats through the NVIDIA BioNeMo drug discovery microservices and framework.
It’s part of Mitsui’s broader strategic growth plan to develop software and services for healthcare, such as powering Japan’s $100 billion pharma industry, the world’s third largest following the U.S. and China.
Xeueka’s services will include using AI to quickly screen billions of drug candidates, to predict how useful molecules will bind with proteins and to simulate detailed chemical behaviors.
To learn more, read about NVIDIA Confidential Computing and NVIDIA BioNeMo, an AI platform for drug discovery.
]]>Consulting giants including Accenture, Deloitte, EY Strategy and Consulting Co., Ltd. (or EY Japan), FPT, Kyndryl and Tata Consultancy Services Japan (TCS Japan) are working with NVIDIA to establish innovation centers in Japan to accelerate the nation’s goal of embracing enterprise AI and physical AI across its industrial landscape.
The centers will use NVIDIA AI Enterprise software, local language models and NVIDIA NIM microservices to help clients in Japan advance the development and deployment of AI agents tailored to their industries’ respective needs, boosting productivity with a digital workforce.
Using the NVIDIA Omniverse platform, Japanese firms can develop digital twins and simulate complex physical AI systems, driving innovation in manufacturing, robotics and other sectors.
Like many nations, Japan is navigating complex social and demographic challenges, which is leading to a smaller workforce as older generations retire. Leaning into its manufacturing and robotics leadership, the country is seeking opportunities to solve these challenges using AI.
The Japanese government in April published a paper on its aims to become “the world’s most AI-friendly country.” AI adoption is strong and growing, as IDC reports that the Japanese AI systems market reached approximately $5.9 billion this year, with a year-on-year growth rate of 31.2%.1
The consulting giants’ initiatives and activities include:
- Accenture has established the Accenture NVIDIA Business Group and will provide solutions and services incorporating a Japanese large language model (LLM), which uses NVIDIA NIM and NVIDIA NeMo, as a Japan-specific offering. In addition, Accenture will deploy agentic AI solutions based on Accenture AI Refinery to all industries in Japan, accelerating total enterprise reinvention for its clients. In the future, Accenture plans to build new services using NVIDIA AI Enterprise and Omniverse at Accenture Innovation Hub Tokyo.
- Deloitte is establishing its AI Experience Center in Tokyo, which will serve as an executive briefing center to showcase generative AI solutions built on NVIDIA technology. This facility builds on the Deloitte Japan NVIDIA Practice announced in June and will allow clients to experience firsthand how AI can revolutionize their operations. The center will also offer NVIDIA AI and Omniverse Blueprints to help enterprises in Japan adopt agentic AI effectively.
- EY Strategy and Consulting Co., Ltd (EY Japan) is developing a multitude of digital transformation (DX) solutions in Japan across diverse industries including finance, retail, media and manufacturing. The new EY Japan DX offerings will be built with NVIDIA AI Enterprise to serve the country’s growing demand for digital twins, 3D applications, multimodal AI and generative AI.
- FPT is launching FPT AI Factory in Japan with NVIDIA Hopper GPUs and NVIDIA AI Enterprise software to support the country’s AI transformation by using business data in a secure, sovereign environment. FPT is integrating the NVIDIA NeMo framework with FPT AI Studio for building, pretraining and fine-tuning generative AI models, including FPT’s multi-language LLM, named Saola. In addition, to provide end-to-end AI integration services, FPT plans to train over 1,000 software engineers and consultants domestically in Japan, and over 7,000 globally by 2026.
- IT infrastructure services provider Kyndryl has launched a dedicated AI private cloud in Japan. Built in collaboration with Dell Technologies using the Dell AI Factory with NVIDIA, this new AI private cloud will provide a controlled, secure and sovereign location for customers to develop, test and plan implementation of AI on the end-to-end NVIDIA AI platform, including NVIDIA accelerated computing and networking, as well as the NVIDIA AI Enterprise software.
- TCS Japan will begin offering its TCS global AI offerings built on the full NVIDIA AI stack in the automotive and manufacturing industries. These solutions will be hosted in its showcase centers at TCS Japan’s Azabudai office in Tokyo.
Located in the Tokyo and Kansai metropolitan areas, these new consulting centers offer hands-on experience with NVIDIA’s latest technologies and expert guidance — helping accelerate AI transformation, solve complex social challenges and support the nation’s economic growth.
To learn more, watch the NVIDIA AI Summit Japan fireside chat with NVIDIA founder and CEO Jensen Huang.
Editor’s note: IDC figures are sourced to IDC, 2024 Domestic AI System Market Forecast Announced, April 2024. The IDC forecast amount was converted to USD by NVIDIA, while the CAGR (31.2%) was calculated based on JPY.
]]>From call centers to factories to hospitals, AI is sweeping Japan.
Undergirding it all: the exceptional resources of the island nation’s world-class universities and global technology leaders such as Fujitsu, The Institute of Science Tokyo, NEC and NTT.
NVIDIA software — NVIDIA AI Enterprise for building and deploying AI agents and NVIDIA Omniverse for bringing AI into the physical world — is playing a crucial role in supporting Japan’s transformation into a global hub for AI development.
The bigger picture: Japan’s journey to AI sovereignty is well underway to support the nation in building, developing and sharing AI innovations at home and across the world.
Japanese AI Pioneers to Power Homegrown Innovation
Putting Japan in a position to become a global AI leader begins with AI-driven language models. Japanese tech leaders are developing advanced AI models that can better interpret Japanese cultural and linguistic nuances.
These models enable developers to build AI applications for industries requiring high-precision outcomes, such as healthcare, finance and manufacturing.
As Japan’s tech giants support AI adoption across the country, they’re using NVIDIA AI Enterprise software.
Fujitsu’s Takane model is specifically built for high-stakes sectors like finance and security.
The model is designed to prioritize security and accuracy with Japanese data, which is crucial for sensitive fields. It excels in both domestic and international Japanese LLM benchmarks for natural Japanese expression and accuracy.
The companies plan to use NVIDIA NeMo for additional fine-tuning, and Fujitsu has tapped NVIDIA to support making Takane available as an NVIDIA NIM to broaden accessibility for the developer community.
NEC’s cotomi model uses NeMo’s parallel processing techniques for efficient model training. It’s already integrated with NEC’s solutions in finance, manufacturing, healthcare and local governments.
NTT Group is moving forward with NTT Communications’ launch of NTT’s large language model “tsuzumi,” which is accelerated with NVIDIA TensorRT-LLM for AI agent customer experiences and use cases such as document summarization.
Meanwhile, startups such as Kotoba Technologies, a Tokyo-based software developer, will unveil its Kotoba-Whisper model, built using NVIDIA NeMo for AI model building.
The transcription application built on the Kotoba-Whisper model performed live transcription during this week’s conversation between SoftBank Chairman and CEO Masayoshi Son and NVIDIA founder and CEO Jensen Huang at NVIDIA AI Summit Japan.
Kotoba Technologies reports that using NeMo’s automatic speech recognition for data preprocessing delivers superior transcription performance.
Kotoba-Whisper is already used in healthcare to create medical records from patient conversations, in customer call centers and for automatic meeting minutes creation across various industries.
These models are used by developers and researchers, especially those focusing on Japanese language AI applications.
Academic Contributions to Japan’s Sovereign AI Vision
Japanese universities, meanwhile, are powering the ongoing transformation with a wave of AI innovations.
Nagoya University’s Ruri-Large, built using NVIDIA’s Nemotron-4 340B — which is also available as a NIM microservice — is a Japanese embedding model. It achieves high document retrieval performance with high-quality synthetic data generated by Nemotron-4 340B, and it enables the enhancement of language model capabilities through retrieval-augmented generation using external, authoritative knowledge bases.
The National Institute of Informatics will introduce LLM.jp-3-13B-Instruct, a sovereign AI model developed from scratch. Supported by several Japanese government-backed programs, this model underscores the nation’s commitment to self-sufficiency in AI. It’s expected to be available as a NIM microservice soon.
The Institute of Science Tokyo and Japan’s National Institute of Advanced Industrial Science and Technology, better known as AIST, will present the Llama 3.1 Swallow model. Optimized for Japanese tasks, it’s now a NIM microservice that can integrate into generative AI workflows for uses ranging from cultural research to business applications.
The University of Tokyo’s Human Genome Center uses NVIDIA AI Enterprise and NVIDIA Parabricks software for rapid genomic analysis, advancing life sciences and precision medicine.
Japan’s Tech Providers Helping Organizations Adopt AI
In addition, technology providers are working to bring NVIDIA AI technologies of all kinds to organizations across Japan.
Accenture will deploy AI agent solutions based on the Accenture AI Refinery across all industries in Japan, customizing with NVIDIA NeMo and deploying with NVIDIA NIM for a Japanese-specific solution.
Dell Technologies is deploying the Dell AI Factory with NVIDIA globally — with a key focus on the Japanese market — and will support NVIDIA NIM microservices for Japanese enterprises across various industries.
Deloitte will integrate NIM microservices that support the leading Japanese language models including LLM.jp, Kotoba, Ruri-large, Swallow and more, into its multi-agent solution.
HPE has launched HPE Private Cloud AI platform, supporting NVIDIA AI Enterprise in a private environment. This solution can be tailored for organizations looking to tap into Japan’s sovereign AI NIM microservices, meeting the needs of companies that prioritize data sovereignty while using advanced AI capabilities.
Bringing Physical AI to Industries With NVIDIA Omniverse
The proliferation of language models across academia, startups and enterprises, however, is just the start of Japan’s AI revolution.
A leading maker of industrial robots, a top automaker and a retail giant are all embracing NVIDIA Omniverse and AI, as physics-based simulation drives the next wave of automation.
Industrial automation provider Yaskawa, which has shipped 600,000 robots, is developing adaptive robots for increased autonomy. Yaskawa is now adopting NVIDIA Isaac libraries and AI models to create adaptive robot applications for factory automation and other industries such as food, logistics, medical, agriculture and more.
It’s using NVIDIA Isaac Manipulator, a reference workflow of NVIDIA-accelerated libraries and AI models, to help its developers build AI-enabled manipulators, or robot arms.
It’s also using NVIDIA FoundationPose for precise 6D pose estimation and tracking.
More broadly, NVIDIA and Yaskawa teams use AI-powered simulations and digital twin technology — powered by Omniverse — to accelerate the development and deployment of Yaskawa’s robotic solutions, saving time and resources.
Meanwhile, Toyota is looking into how to build robotic factory lines in Omniverse to improve tasks in robot motion in metal-forging processes.
And another iconic Japanese company, Seven & i Holdings, is using Omniverse to gather insights from video cameras in research to optimize retail and enhance safety.
To learn more, check out our blog on these use cases.
See notice regarding software product information.
]]>