Robots are moving goods in warehouses, packaging foods and helping assemble vehicles — bringing enhanced automation to use cases across industries.
There are two keys to their success: Physical AI and robotics simulation.
Physical AI describes AI models that can understand and interact with the physical world. Physical AI embodies the next wave of autonomous machines and robots, such as self-driving cars, industrial manipulators, mobile robots, humanoids and even robot-run infrastructure like factories and warehouses.
With virtual commissioning of robots in digital worlds, robots are first trained using robotic simulation software before they are deployed for real-world use cases.
Robotics Simulation Summarized
An advanced robotics simulator facilitates robot learning and testing of virtual robots without requiring the physical robot. By applying physics principles and replicating real-world conditions, these simulators generate synthetic datasets to train machine learning models for deployment on physical robots.
Simulations are used for initial AI model training and then to validate the entire software stack, minimizing the need for physical robots during testing. NVIDIA Isaac Sim, a reference application built on the NVIDIA Omniverse platform, provides accurate visualizations and supports Universal Scene Description (OpenUSD)-based workflows for advanced robot simulation and validation.
NVIDIA’s 3 Computer Framework Facilitates Robot Simulation
Three computers are needed to train and deploy robot technology.
- A supercomputer to train and fine-tune powerful foundation and generative AI models.
- A development platform for robotics simulation and testing.
- An onboard runtime computer to deploy trained models to physical robots.
Only after adequate training in simulated environments can physical robots be commissioned.
The NVIDIA DGX platform can serve as the first computing system to train models.
NVIDIA Omniverse running on NVIDIA OVX servers functions as the second computer system, providing the development platform and simulation environment for testing, optimizing and debugging physical AI.
NVIDIA Jetson Thor robotics computers designed for onboard computing serve as the third runtime computer.
Who Uses Robotics Simulation?
Today, robot technology and robot simulations boost operations massively across use cases.
Global leader in power and thermal technologies Delta Electronics uses simulation to test out its optical inspection algorithms to detect product defects on production lines.
Deep tech startup Wandelbots is building a custom simulator by integrating Isaac Sim into its application, making it easy for end users to program robotic work cells in simulation and seamlessly transfer models to a real robot.
Boston Dynamics is activating researchers and developers through its reinforcement learning researcher kit.
Robotics company Fourier is simulating real-world conditions to train humanoid robots with the precision and agility needed for close robot-human collaboration.
Using NVIDIA Isaac Sim, robotics company Galbot built DexGraspNet, a comprehensive simulated dataset for dexterous robotic grasps containing over 1 million ShadowHand grasps on 5,300+ objects. The dataset can be applied to any dexterous robotic hand to accomplish complex tasks that require fine-motor skills.
Using Robotics Simulation for Planning and Control Outcomes
In complex and dynamic industrial settings, robotics simulation is evolving to integrate digital twins, enhancing planning, control and learning outcomes.
Developers import computer-aided design models into a robotics simulator to build virtual scenes and employ algorithms to create the robot operating system and enable task and motion planning. While traditional methods involve prescribing control signals, the shift toward machine learning allows robots to learn behaviors through methods like imitation and reinforcement learning, using simulated sensor signals.
This evolution continues with digital twins in complex facilities like manufacturing assembly lines, where developers can test and refine real-time AIs entirely in simulation. This approach saves software development time and costs, and reduces downtime by anticipating issues. For instance, using NVIDIA Omniverse, Metropolis and cuOpt, developers can use digital twins to develop, test and refine physical AI in simulation before deploying in industrial infrastructure.
High-Fidelity, Physics-Based Simulation Breakthroughs
High-fidelity, physics-based simulations have supercharged industrial robotics through real-world experimentation in virtual environments.
NVIDIA PhysX, integrated into Omniverse and Isaac Sim, empowers roboticists to develop fine- and gross-motor skills for robot manipulators, rigid and soft body dynamics, vehicle dynamics and other critical features that ensure the robot obeys the laws of physics. This includes precise control over actuators and modeling of kinematics, which are essential for accurate robot movements.
To close the sim-to-real gap, Isaac Lab offers a high-fidelity, open-source framework for reinforcement learning and imitation learning that facilitates seamless policy transfer from simulated environments to physical robots. With GPU parallelization, Isaac Lab accelerates training and improves performance, making complex tasks more achievable and safe for industrial robots.
To learn more about creating a locomotion reinforcement learning policy with Isaac Sim and Isaac Lab, read this developer blog.
Teaching Collision-Free Motion for Autonomy
Industrial robot training often occurs in specific settings like factories or fulfillment centers, where simulations help address challenges related to various robot types and chaotic environments. A critical aspect of these simulations is generating collision-free motion in unknown, cluttered environments.
Traditional motion planning approaches that attempt to address these challenges can come up short in unknown or dynamic environments. SLAM, or simultaneous localization and mapping, can be used to generate 3D maps of environments with camera images from multiple viewpoints. However, these maps require revisions when objects move and environments are changed.
The NVIDIA Robotics research team and the University of Washington introduced Motion Policy Networks (MπNets), an end-to-end neural policy that generates real-time, collision-free motion using a single fixed camera’s data stream. Trained on over 3 million motion planning problems and 700 million simulated point clouds, MπNets navigates unknown real-world environments effectively.
While the MπNets model applies direct learning for trajectories, the team also developed a point cloud-based collision model called CabiNet, trained on over 650,000 procedurally generated simulated scenes.
With the CabiNet model, developers can deploy general-purpose, pick-and-place policies of unknown objects beyond a flat tabletop setup. Training with a large synthetic dataset allowed the model to generalize to out-of-distribution scenes in a real kitchen environment, without needing any real data.
How Developers Can Get Started Building Robotic Simulators
Get started with technical resources, reference applications and other solutions for developing physically accurate simulation pipelines by visiting the NVIDIA Robotics simulation use case page.
Robot developers can tap into NVIDIA Isaac Sim, which supports multiple robot training techniques:
- Synthetic data generation for training perception AI models
- Software-in-the-loop testing for the entire robot stack
- Robot policy training with Isaac Lab
Developers can also pair ROS 2 with Isaac Sim to train, simulate and validate their robot systems. The Isaac Sim to ROS 2 workflow is similar to workflows executed with other robot simulators such as Gazebo. It starts with bringing a robot model into a prebuilt Isaac Sim environment, adding sensors to the robot, and then connecting the relevant components to the ROS 2 action graph and simulating the robot by controlling it through ROS 2 packages.
Stay up to date by subscribing to our newsletter and follow NVIDIA Robotics on LinkedIn, Instagram, X and Facebook.
]]>Editor’s note: This article, originally published on November 15, 2023, has been updated.
To understand the latest advance in generative AI, imagine a courtroom.
Judges hear and decide cases based on their general understanding of the law. Sometimes a case — like a malpractice suit or a labor dispute — requires special expertise, so judges send court clerks to a law library, looking for precedents and specific cases they can cite.
Like a good judge, large language models (LLMs) can respond to a wide variety of human queries. But to deliver authoritative answers that cite sources, the model needs an assistant to do some research.
The court clerk of AI is a process called retrieval-augmented generation, or RAG for short.
How It Got Named ‘RAG’
Patrick Lewis, lead author of the 2020 paper that coined the term, apologized for the unflattering acronym that now describes a growing family of methods across hundreds of papers and dozens of commercial services he believes represent the future of generative AI.

“We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
“We always planned to have a nicer sounding name, but when it came time to write the paper, no one had a better idea,” said Lewis, who now leads a RAG team at AI startup Cohere.
So, What Is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences.
That deep understanding, sometimes called parameterized knowledge, makes LLMs useful in responding to general prompts at light speed. However, it does not serve users who want a deeper dive into a current or more specific topic.
Combining Internal, External Resources
Lewis and colleagues developed retrieval-augmented generation to link generative AI services to external resources, especially ones rich in the latest technical details.
The paper, with coauthors from the former Facebook AI Research (now Meta AI), University College London and New York University, called RAG “a general-purpose fine-tuning recipe” because it can be used by nearly any LLM to connect with practically any external resource.
Building User Trust
Retrieval-augmented generation gives models sources they can cite, like footnotes in a research paper, so users can check any claims. That builds trust.
What’s more, the technique can help models clear up ambiguity in a user query. It also reduces the possibility a model will make a wrong guess, a phenomenon sometimes called hallucination.
Another great advantage of RAG is it’s relatively easy. A blog by Lewis and three of the paper’s coauthors said developers can implement the process with as few as five lines of code.
That makes the method faster and less expensive than retraining a model with additional datasets. And it lets users hot-swap new sources on the fly.
How People Are Using RAG
With retrieval-augmented generation, users can essentially have conversations with data repositories, opening up new kinds of experiences. This means the applications for RAG could be multiple times the number of available datasets.
For example, a generative AI model supplemented with a medical index could be a great assistant for a doctor or nurse. Financial analysts would benefit from an assistant linked to market data.
In fact, almost any business can turn its technical or policy manuals, videos or logs into resources called knowledge bases that can enhance LLMs. These sources can enable use cases such as customer or field support, employee training and developer productivity.
The broad potential is why companies including AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle and Pinecone are adopting RAG.
Getting Started With Retrieval-Augmented Generation
To help users get started, NVIDIA developed an AI Blueprint for building virtual assistants. Organizations can use this reference architecture to quickly scale their customer service operations with generative AI and RAG, or get started building a new customer-centric solution.
The blueprint uses some of the latest AI-building methodologies and NVIDIA NeMo Retriever, a collection of easy-to-use NVIDIA NIM microservices for large-scale information retrieval. NIM eases the deployment of secure, high-performance AI model inferencing across clouds, data centers and workstations.
These components are all part of NVIDIA AI Enterprise, a software platform that accelerates the development and deployment of production-ready AI with the security, support and stability businesses need.
There is also a free hands-on NVIDIA LaunchPad lab for developing AI chatbots using RAG so developers and IT teams can quickly and accurately generate responses based on enterprise data.
Getting the best performance for RAG workflows requires massive amounts of memory and compute to move and process data. The NVIDIA GH200 Grace Hopper Superchip, with its 288GB of fast HBM3e memory and 8 petaflops of compute, is ideal — it can deliver a 150x speedup over using a CPU.
Once companies get familiar with RAG, they can combine a variety of off-the-shelf or custom LLMs with internal or external knowledge bases to create a wide range of assistants that help their employees and customers.
RAG doesn’t require a data center. LLMs are debuting on Windows PCs, thanks to NVIDIA software that enables all sorts of applications users can access even on their laptops.
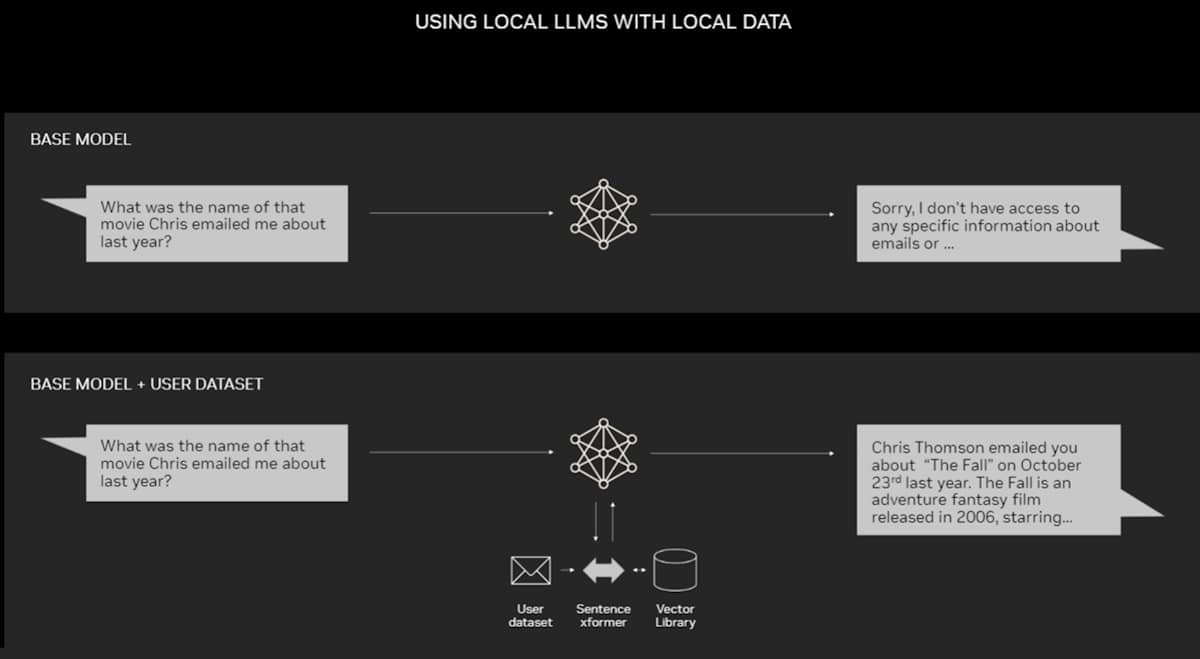
PCs equipped with NVIDIA RTX GPUs can now run some AI models locally. By using RAG on a PC, users can link to a private knowledge source – whether that be emails, notes or articles – to improve responses. The user can then feel confident that their data source, prompts and response all remain private and secure.
A recent blog provides an example of RAG accelerated by TensorRT-LLM for Windows to get better results fast.
The History of RAG
The roots of the technique go back at least to the early 1970s. That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use natural language processing (NLP) to access text, initially in narrow topics such as baseball.
The concepts behind this kind of text mining have remained fairly constant over the years. But the machine learning engines driving them have grown significantly, increasing their usefulness and popularity.
In the mid-1990s, the Ask Jeeves service, now Ask.com, popularized question answering with its mascot of a well-dressed valet. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy! game show.
Today, LLMs are taking question-answering systems to a whole new level.
Insights From a London Lab
The seminal 2020 paper arrived as Lewis was pursuing a doctorate in NLP at University College London and working for Meta at a new London AI lab. The team was searching for ways to pack more knowledge into an LLM’s parameters and using a benchmark it developed to measure its progress.
Building on earlier methods and inspired by a paper from Google researchers, the group “had this compelling vision of a trained system that had a retrieval index in the middle of it, so it could learn and generate any text output you wanted,” Lewis recalled.

When Lewis plugged into the work in progress a promising retrieval system from another Meta team, the first results were unexpectedly impressive.
“I showed my supervisor and he said, ‘Whoa, take the win. This sort of thing doesn’t happen very often,’ because these workflows can be hard to set up correctly the first time,” he said.
Lewis also credits major contributions from team members Ethan Perez and Douwe Kiela, then of New York University and Facebook AI Research, respectively.
When complete, the work, which ran on a cluster of NVIDIA GPUs, showed how to make generative AI models more authoritative and trustworthy. It’s since been cited by hundreds of papers that amplified and extended the concepts in what continues to be an active area of research.
How Retrieval-Augmented Generation Works
At a high level, here’s how an NVIDIA technical brief describes the RAG process.
When users ask an LLM a question, the AI model sends the query to another model that converts it into a numeric format so machines can read it. The numeric version of the query is sometimes called an embedding or a vector.
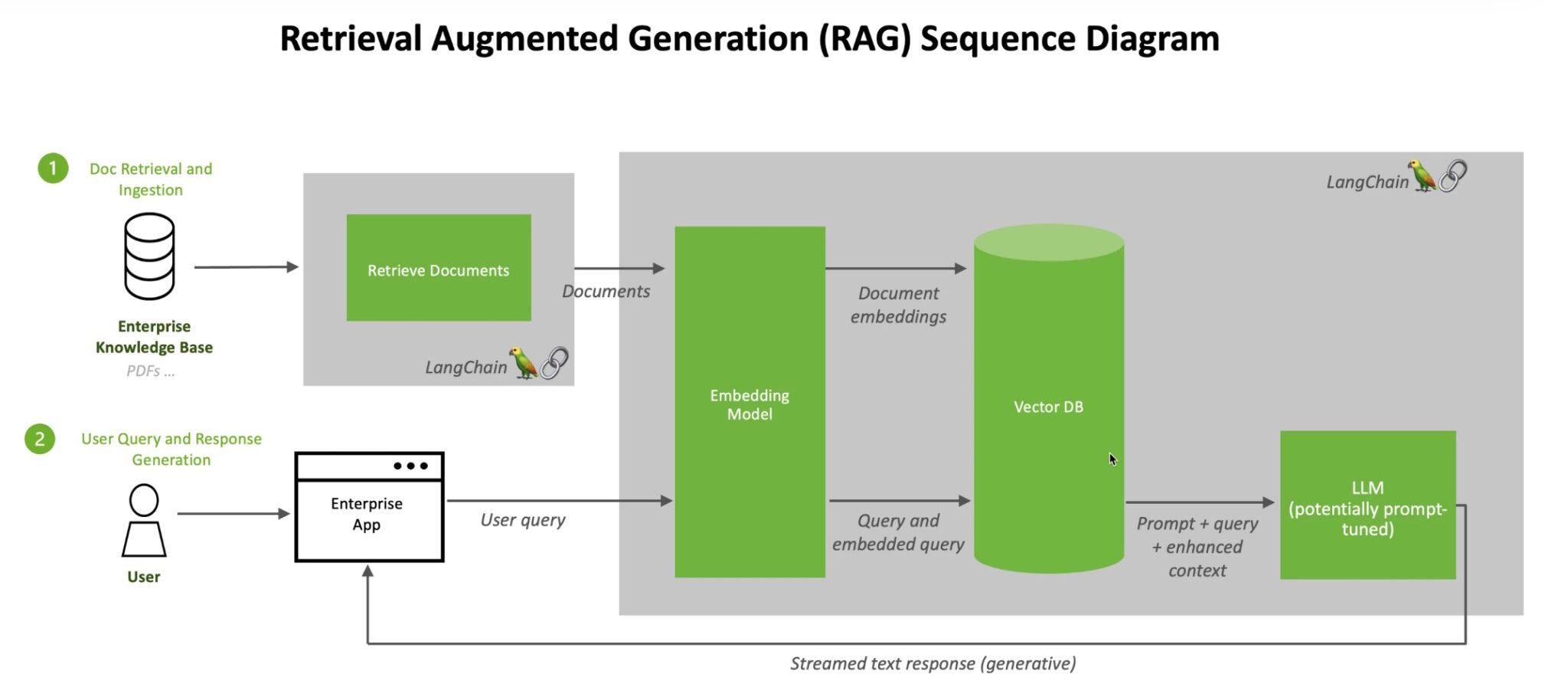
The embedding model then compares these numeric values to vectors in a machine-readable index of an available knowledge base. When it finds a match or multiple matches, it retrieves the related data, converts it to human-readable words and passes it back to the LLM.
Finally, the LLM combines the retrieved words and its own response to the query into a final answer it presents to the user, potentially citing sources the embedding model found.
Keeping Sources Current
In the background, the embedding model continuously creates and updates machine-readable indices, sometimes called vector databases, for new and updated knowledge bases as they become available.
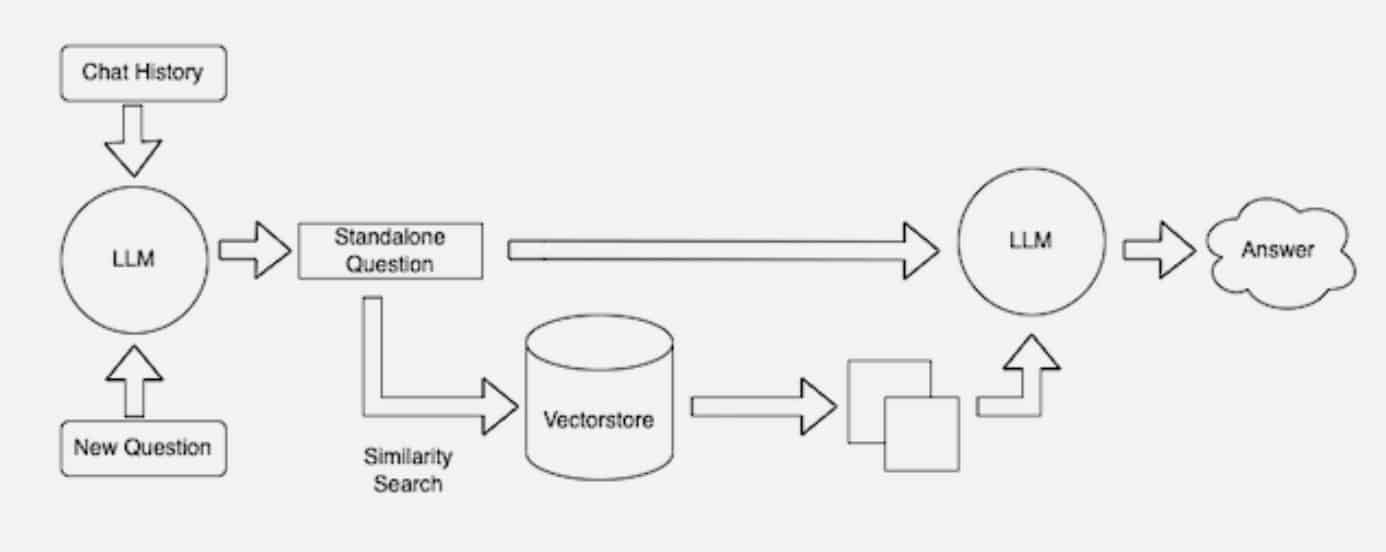
Many developers find LangChain, an open-source library, can be particularly useful in chaining together LLMs, embedding models and knowledge bases. NVIDIA uses LangChain in its reference architecture for retrieval-augmented generation.
The LangChain community provides its own description of a RAG process.
Looking forward, the future of generative AI lies in creatively chaining all sorts of LLMs and knowledge bases together to create new kinds of assistants that deliver authoritative results users can verify.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.
]]>Editor’s note: The name of NIM Agent Blueprints was changed to NVIDIA Blueprints in October 2024. All references to the name have been updated in this blog.
AI chatbots use generative AI to provide responses based on a single interaction. A person makes a query and the chatbot uses natural language processing to reply.
The next frontier of artificial intelligence is agentic AI, which uses sophisticated reasoning and iterative planning to autonomously solve complex, multi-step problems. And it’s set to enhance productivity and operations across industries.
Agentic AI systems ingest vast amounts of data from multiple sources to independently analyze challenges, develop strategies and execute tasks like supply chain optimization, cybersecurity vulnerability analysis and helping doctors with time-consuming tasks.
Agentic AI uses sophisticated reasoning and iterative planning to solve complex, multi-step problems.
How Does Agentic AI Work?
Agentic AI uses a four-step process for problem-solving:
- Perceive: AI agents gather and process data from various sources, such as sensors, databases and digital interfaces. This involves extracting meaningful features, recognizing objects or identifying relevant entities in the environment.
- Reason: A large language model acts as the orchestrator, or reasoning engine, that understands tasks, generates solutions and coordinates specialized models for specific functions like content creation, vision processing or recommendation systems. This step uses techniques like retrieval-augmented generation (RAG) to access proprietary data sources and deliver accurate, relevant outputs.
- Act: By integrating with external tools and software via application programming interfaces, agentic AI can quickly execute tasks based on the plans it has formulated. Guardrails can be built into AI agents to help ensure they execute tasks correctly. For example, a customer service AI agent may be able to process claims up to a certain amount, while claims above the amount would have to be approved by a human.
- Learn: Agentic AI continuously improves through a feedback loop, or
“data flywheel,” where the data generated from its interactions is fed into the system to enhance models. This ability to adapt and become more effective over time offers businesses a powerful tool for driving better decision-making and operational efficiency.
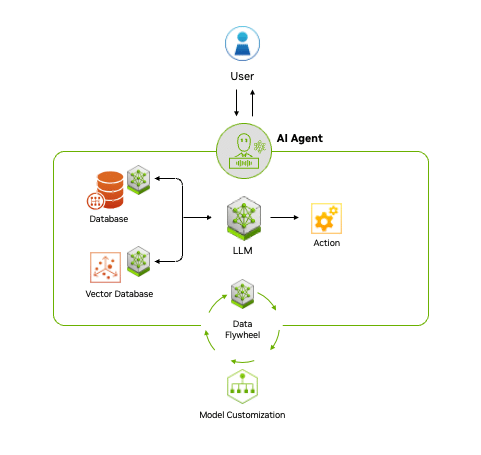 Fueling Agentic AI With Enterprise Data
Fueling Agentic AI With Enterprise Data
Across industries and job functions, generative AI is transforming organizations by turning vast amounts of data into actionable knowledge, helping employees work more efficiently.
AI agents build on this potential by accessing diverse data through accelerated AI query engines, which process, store and retrieve information to enhance generative AI models. A key technique for achieving this is RAG, which allows AI to tap into a broader range of data sources.
Over time, AI agents learn and improve by creating a data flywheel, where data generated through interactions is fed back into the system, refining models and increasing their effectiveness.
The end-to-end NVIDIA AI platform, including NVIDIA NeMo microservices, provides the ability to manage and access data efficiently, which is crucial for building responsive agentic AI applications.
Agentic AI in Action
The potential applications of agentic AI are vast, limited only by creativity and expertise. From simple tasks like generating and distributing content to more complex use cases such as orchestrating enterprise software, AI agents are transforming industries.

Customer Service: AI agents are improving customer support by enhancing self-service capabilities and automating routine communications. Over half of service professionals report significant improvements in customer interactions, reducing response times and boosting satisfaction.
There’s also growing interest in digital humans — AI-powered agents that embody a company’s brand and offer lifelike, real-time interactions to help sales representatives answer customer queries or solve issues directly when call volumes are high.
Content Creation: Agentic AI can help quickly create high-quality, personalized marketing content. Generative AI agents can save marketers an average of three hours per content piece, allowing them to focus on strategy and innovation. By streamlining content creation, businesses can stay competitive while improving customer engagement.
Software Engineering: AI agents are boosting developer productivity by automating repetitive coding tasks. It’s projected that by 2030 AI could automate up to 30% of work hours, freeing developers to focus on more complex challenges and drive innovation.
Healthcare: For doctors analyzing vast amounts of medical and patient data, AI agents can distill critical information to help them make better-informed care decisions. Automating administrative tasks and capturing clinical notes in patient appointments reduces the burden of time-consuming tasks, allowing doctors to focus on developing a doctor-patient connection.
AI agents can also provide 24/7 support, offering information on prescribed medication usage, appointment scheduling and reminders, and more to help patients adhere to treatment plans.
How to Get Started
With its ability to plan and interact with a wide variety of tools and software, agentic AI marks the next chapter of artificial intelligence, offering the potential to enhance productivity and revolutionize the way organizations operate.
To accelerate the adoption of generative AI-powered applications and agents, NVIDIA Blueprints provide sample applications, reference code, sample data, tools and comprehensive documentation.
NVIDIA partners including Accenture are helping enterprises use agentic AI with solutions built with NVIDIA Blueprints.
Visit ai.nvidia.com to learn more about the tools and software NVIDIA offers to help enterprises build their own AI agents.
]]>AI isn’t just about building smarter machines. It’s about building a greener world.
From optimizing energy use to reducing emissions, AI and accelerated computing are helping industries tackle some of the world’s toughest environmental challenges.
As Joshua Parker, senior director of corporate sustainability at NVIDIA, explains in the latest episode of NVIDIA’s AI Podcast, these technologies are powering a new era of energy efficiency.
Parker, a seasoned sustainability professional with a background in law and engineering, has led sustainability initiatives at major companies like Western Digital, where he developed corporate sustainability strategies. His expertise spans corporate sustainability, intellectual property and environmental impact.
AI can, in fact, help reduce energy consumption. And it’s doing it in some surprising ways.
AI systems themselves use energy, of course, but the big story is how AI and accelerated computing are helping other systems save energy. Take data centers, for instance.
They’re the backbone of AI, housing the powerful systems that crunch the data needed for AI to work in services like chatbots, AI-powered search and content generation. Globally, data centers account for about 2% of total energy consumption, and AI-specific centers represent only a tiny fraction of that.
“AI still accounts for a tiny, tiny fraction of overall energy consumption globally,” Parker said. Yet, the potential for AI to optimize energy use is vast.
Despite this, AI’s real superpower lies in its ability to optimize.
How? By using accelerated computing platforms that combine GPUs and CPUs. GPUs are designed to handle complex computations quickly and efficiently.
In fact, these systems can be up to 20x more energy-efficient than traditional CPU-only systems for AI inference and training, Parker notes.
This progress has contributed to massive gains in energy efficiency over the past eight years, which is part of the reason AI is now able to tackle increasingly complex problems.
What Is Accelerated Computing?
At its core, accelerated computing is about doing more with less.
It involves using specialized hardware — like GPUs — to perform tasks faster and with less energy.
This isn’t just theoretical. “The change in efficiency is really, really dramatic,” Parker emphasized.
“If you compare the energy efficiency for AI inference from eight years ago until today, [it’s] 45,000 times more energy efficient,” Parker said.
This matters because as AI becomes more widespread, the demand for computing power grows.
Accelerated computing helps companies scale their AI operations without consuming massive amounts of energy.
This energy efficiency is key to AI’s ability to tackle some of today’s biggest sustainability challenges.
AI in Action: Tackling Climate Change
AI isn’t just saving energy — it’s helping to fight climate change.
“AI and accelerated computing in general are game-changers when it comes to weather and climate modeling and simulation,” Parker said.
For instance, AI-enhanced weather forecasting is becoming more accurate, allowing industries and governments to prepare for climate-related events like hurricanes or floods, Parker explained.
The better we can predict these events, the better we can prepare for them, which means fewer resources wasted and less damage done.
Another key area is the rise of digital twins — virtual models of physical environments.
These AI-powered simulations allow companies to optimize energy consumption in real time, without having to make costly changes in the physical world. In one case, using a digital twin helped a company achieve a 10% reduction in energy use, Parker said.
That may sound small, but scale it across industries, and the impact is huge.
AI is also playing a crucial role in developing new materials for renewable energy technologies like solar panels and electric vehicles, helping accelerate the transition to clean energy.
Can AI Make Data Centers More Sustainable?
AI needs data centers to operate, and, as AI grows, so does the demand for computing power. But data centers don’t have to be energy hogs. In fact, they can be part of the sustainability solution.
One major innovation is direct-to-chip liquid cooling. This technology allows data centers to cool their systems much more efficiently than traditional air conditioning methods, which are often energy-intensive.
“Our recommended design for the data centers for our new B200 chip is focused all on direct-to-chip liquid cooling,” Parker explained. By cooling directly at the chip level, this method saves energy, helping data centers stay cool without guzzling power.
As AI scales up, the future of data centers will depend on designing for energy efficiency from the ground up.
That means integrating renewable energy, using energy storage solutions and continuing to innovate with cooling technologies.
The goal is to create green data centers that can meet the world’s growing demand for compute power without increasing their carbon footprint.
“The compute density is so high that it makes more sense to invest in the cooling because you’re getting so much more compute for that same single direct-to-chip cooling element,” Parker said.
The Role of AI in Building a Sustainable Future
AI is not just a tool for optimizing systems — it’s a driver of sustainable innovation.
From improving the efficiency of energy grids to enhancing supply chain logistics, AI is leading the charge in reducing waste and emissions.
“AI, I firmly believe, is going to be the best tool that we’ve ever seen to help us achieve more sustainability and more sustainable outcomes,” Parker said.
Register for the NVIDIA AI Summit DC to explore how AI and accelerated computing are shaping the future of energy efficiency and climate solutions.
]]>Artificial intelligence, like any transformative technology, is a work in progress — continually growing in its capabilities and its societal impact. Trustworthy AI initiatives recognize the real-world effects that AI can have on people and society, and aim to channel that power responsibly for positive change.
What Is Trustworthy AI?
Trustworthy AI is an approach to AI development that prioritizes safety and transparency for those who interact with it. Developers of trustworthy AI understand that no model is perfect, and take steps to help customers and the general public understand how the technology was built, its intended use cases and its limitations.
In addition to complying with privacy and consumer protection laws, trustworthy AI models are tested for safety, security and mitigation of unwanted bias. They’re also transparent — providing information such as accuracy benchmarks or a description of the training dataset — to various audiences including regulatory authorities, developers and consumers.
Principles of Trustworthy AI
Trustworthy AI principles are foundational to NVIDIA’s end-to-end AI development. They have a simple goal: to enable trust and transparency in AI and support the work of partners, customers and developers.
Privacy: Complying With Regulations, Safeguarding Data
AI is often described as data hungry. Often, the more data an algorithm is trained on, the more accurate its predictions.
But data has to come from somewhere. To develop trustworthy AI, it’s key to consider not just what data is legally available to use, but what data is socially responsible to use.
Developers of AI models that rely on data such as a person’s image, voice, artistic work or health records should evaluate whether individuals have provided appropriate consent for their personal information to be used in this way.
For institutions like hospitals and banks, building AI models means balancing the responsibility of keeping patient or customer data private while training a robust algorithm. NVIDIA has created technology that enables federated learning, where researchers develop AI models trained on data from multiple institutions without confidential information leaving a company’s private servers.
NVIDIA DGX systems and NVIDIA FLARE software have enabled several federated learning projects in healthcare and financial services, facilitating secure collaboration by multiple data providers on more accurate, generalizable AI models for medical image analysis and fraud detection.
Safety and Security: Avoiding Unintended Harm, Malicious Threats
Once deployed, AI systems have real-world impact, so it’s essential they perform as intended to preserve user safety.
The freedom to use publicly available AI algorithms creates immense possibilities for positive applications, but also means the technology can be used for unintended purposes.
To help mitigate risks, NVIDIA NeMo Guardrails keeps AI language models on track by allowing enterprise developers to set boundaries for their applications. Topical guardrails ensure that chatbots stick to specific subjects. Safety guardrails set limits on the language and data sources the apps use in their responses. Security guardrails seek to prevent malicious use of a large language model that’s connected to third-party applications or application programming interfaces.
NVIDIA Research is working with the DARPA-run SemaFor program to help digital forensics experts identify AI-generated images. Last year, researchers published a novel method for addressing social bias using ChatGPT. They’re also creating methods for avatar fingerprinting — a way to detect if someone is using an AI-animated likeness of another individual without their consent.
To protect data and AI applications from security threats, NVIDIA H100 and H200 Tensor Core GPUs are built with confidential computing, which ensures sensitive data is protected while in use, whether deployed on premises, in the cloud or at the edge. NVIDIA Confidential Computing uses hardware-based security methods to ensure unauthorized entities can’t view or modify data or applications while they’re running — traditionally a time when data is left vulnerable.
Transparency: Making AI Explainable
To create a trustworthy AI model, the algorithm can’t be a black box — its creators, users and stakeholders must be able to understand how the AI works to trust its results.
Transparency in AI is a set of best practices, tools and design principles that helps users and other stakeholders understand how an AI model was trained and how it works. Explainable AI, or XAI, is a subset of transparency covering tools that inform stakeholders how an AI model makes certain predictions and decisions.
Transparency and XAI are crucial to establishing trust in AI systems, but there’s no universal solution to fit every kind of AI model and stakeholder. Finding the right solution involves a systematic approach to identify who the AI affects, analyze the associated risks and implement effective mechanisms to provide information about the AI system.
Retrieval-augmented generation, or RAG, is a technique that advances AI transparency by connecting generative AI services to authoritative external databases, enabling models to cite their sources and provide more accurate answers. NVIDIA is helping developers get started with a RAG workflow that uses the NVIDIA NeMo framework for developing and customizing generative AI models.
NVIDIA is also part of the National Institute of Standards and Technology’s U.S. Artificial Intelligence Safety Institute Consortium, or AISIC, to help create tools and standards for responsible AI development and deployment. As a consortium member, NVIDIA will promote trustworthy AI by leveraging best practices for implementing AI model transparency.
And on NVIDIA’s hub for accelerated software, NGC, model cards offer detailed information about how each AI model works and was built. NVIDIA’s Model Card ++ format describes the datasets, training methods and performance measures used, licensing information, as well as specific ethical considerations.
Nondiscrimination: Minimizing Bias
AI models are trained by humans, often using data that is limited by size, scope and diversity. To ensure that all people and communities have the opportunity to benefit from this technology, it’s important to reduce unwanted bias in AI systems.
Beyond following government guidelines and antidiscrimination laws, trustworthy AI developers mitigate potential unwanted bias by looking for clues and patterns that suggest an algorithm is discriminatory, or involves the inappropriate use of certain characteristics. Racial and gender bias in data are well-known, but other considerations include cultural bias and bias introduced during data labeling. To reduce unwanted bias, developers might incorporate different variables into their models.
Synthetic datasets offer one solution to reduce unwanted bias in training data used to develop AI for autonomous vehicles and robotics. If data used to train self-driving cars underrepresents uncommon scenes such as extreme weather conditions or traffic accidents, synthetic data can help augment the diversity of these datasets to better represent the real world, helping improve AI accuracy.
NVIDIA Omniverse Replicator, a framework built on the NVIDIA Omniverse platform for creating and operating 3D pipelines and virtual worlds, helps developers set up custom pipelines for synthetic data generation. And by integrating the NVIDIA TAO Toolkit for transfer learning with Innotescus, a web platform for curating unbiased datasets for computer vision, developers can better understand dataset patterns and biases to help address statistical imbalances.
Learn more about trustworthy AI on NVIDIA.com and the NVIDIA Blog. For more on tackling unwanted bias in AI, watch this talk from NVIDIA GTC and attend the trustworthy AI track at the upcoming conference, taking place March 18-21 in San Jose, Calif, and online.
]]>Nations have long invested in domestic infrastructure to advance their economies, control their own data and take advantage of technology opportunities in areas such as transportation, communications, commerce, entertainment and healthcare.
AI, the most important technology of our time, is turbocharging innovation across every facet of society. It’s expected to generate trillions of dollars in economic dividends and productivity gains.
Countries are investing in sovereign AI to develop and harness such benefits on their own. Sovereign AI refers to a nation’s capabilities to produce artificial intelligence using its own infrastructure, data, workforce and business networks.
Why Sovereign AI Is Important
The global imperative for nations to invest in sovereign AI capabilities has grown since the rise of generative AI, which is reshaping markets, challenging governance models, inspiring new industries and transforming others — from gaming to biopharma. It’s also rewriting the nature of work, as people in many fields start using AI-powered “copilots.”
Sovereign AI encompasses both physical and data infrastructures. The latter includes sovereign foundation models, such as large language models, developed by local teams and trained on local datasets to promote inclusiveness with specific dialects, cultures and practices.
For example, speech AI models can help preserve, promote and revitalize indigenous languages. And LLMs aren’t just for teaching AIs human languages, but for writing software code, protecting consumers from financial fraud, teaching robots physical skills and much more.
In addition, as artificial intelligence and accelerated computing become increasingly critical tools for combating climate change, boosting energy efficiency and protecting against cybersecurity threats, sovereign AI has a pivotal role to play in equipping every nation to bolster its sustainability efforts.
Factoring In AI Factories
Comprising new, essential infrastructure for AI production are “AI factories,” where data comes in and intelligence comes out. These are next-generation data centers that host advanced, full-stack accelerated computing platforms for the most computationally intensive tasks.
Nations are building up domestic computing capacity through various models. Some are procuring and operating sovereign AI clouds in collaboration with state-owned telecommunications providers or utilities. Others are sponsoring local cloud partners to provide a shared AI computing platform for public- and private-sector use.
“The AI factory will become the bedrock of modern economies across the world,” NVIDIA founder and CEO Jensen Huang said in a recent media Q&A.
Sovereign AI Efforts Underway
Nations around the world are already investing in sovereign AI.
Since 2019, NVIDIA’s AI Nations initiative has helped countries spanning every region of the globe to build sovereign AI capabilities, including ecosystem enablement and workforce development, creating the conditions for engineers, developers, scientists, entrepreneurs, creators and public sector officials to pursue their AI ambitions at home.
France-based Scaleway, a subsidiary of the iliad Group, is building Europe’s most powerful cloud-native AI supercomputer. The NVIDIA DGX SuperPOD comprises 127 DGX H100 systems, representing 1,016 NVIDIA H100 Tensor Core GPUs interconnected by NVIDIA NVLink technology and the NVIDIA Quantum-2 InfiniBand platform. NVIDIA DGX systems also include NVIDIA AI Enterprise software for secure, supported and stable AI development and deployment.
Swisscom Group, majority-owned by the Swiss government, recently announced its Italian subsidiary, Fastweb, will build Italy’s first and most powerful NVIDIA DGX-powered supercomputer — also using NVIDIA AI Enterprise software — to develop the first LLM natively trained in the Italian language.
With these NVIDIA technologies and its own cloud and cybersecurity infrastructures, Fastweb plans to launch an end-to-end system with which Italian companies, public-administration organizations and startups can develop generative AI applications for any industry.
The government of India has also announced sovereign AI initiatives promoting workforce development, sustainable computing and private-sector investment in domestic compute capacity. India-based Tata Group, for example, is building a large-scale AI infrastructure powered by the NVIDIA GH200 Grace Hopper Superchip, while Reliance Industries will develop a foundation LLM tailored for generative AI and trained on the diverse languages of the world’s most populous nation. NVIDIA is also working with India’s top universities to support and expand local researcher and developer communities.
Japan is going all in with sovereign AI, collaborating with NVIDIA to upskill its workforce, support Japanese language model development, and expand AI adoption for natural disaster response and climate resilience. These efforts include public-private partnerships that are incentivizing leaders like SoftBank Corp. to collaborate with NVIDIA on building a generative AI platform for 5G and 6G applications as well as a network of distributed AI factories.
Finally, Singapore is fostering a range of sovereign AI programs, including by partnering with NVIDIA to upgrade its National Super Computer Center, or NSCC, with NVIDIA H100 GPUs. In addition, Singtel, a leading communications services provider building energy-efficient AI factories across Southeast Asia, is accelerated by NVIDIA Hopper architecture GPUs and NVIDIA AI reference architectures.
Read more about sovereign AI and its transformative potential.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.
]]>The Wild West had gunslingers, bank robberies and bounties — today’s digital frontier has identity theft, credit card fraud and chargebacks.
Cashing in on financial fraud has become a multibillion-dollar criminal enterprise. And generative AI in the hands of fraudsters only promises to make this more profitable.
Credit card losses worldwide are expected to reach $43 billion by 2026, according to the Nilson Report.
Financial fraud is perpetrated in a growing number of ways, like harvesting hacked data from the dark web for credit card theft, using generative AI for phishing personal information, and laundering money between cryptocurrency, digital wallets and fiat currencies. Many other financial schemes are lurking in the digital underworld.
To keep up, financial services firms are wielding AI for fraud detection. That’s because many of these digital crimes need to be halted in their tracks in real time so that consumers and financial firms can stop losses right away.
So how is AI used for fraud detection?
AI for fraud detection uses multiple machine learning models to detect anomalies in customer behaviors and connections as well as patterns of accounts and behaviors that fit fraudulent characteristics.
Generative AI Can Be Tapped as Fraud Copilot
Much of financial services involves text and numbers. Generative AI and large language models (LLMs), capable of learning meaning and context, promise disruptive capabilities across industries with new levels of output and productivity. Financial services firms can harness generative AI to develop more intelligent and capable chatbots and improve fraud detection.
On the opposite side, bad actors can circumvent AI guardrails with crafty generative AI prompts to use it for fraud. And LLMs are delivering human-like writing, enabling fraudsters to draft more contextually relevant emails without typos and grammar mistakes. Many different tailored versions of phishing emails can be quickly created, making generative AI an excellent copilot for perpetrating scams. There are also a number of dark web tools like FraudGPT, which can exploit generative AI for cybercrimes.
Generative AI can be exploited for financial harm in voice authentication security measures as well. Some banks are using voice authentication to help authorize users. A banking customer’s voice can be cloned using deep fake technology if an attacker can obtain voice samples in an effort to breach such systems. The voice data can be gathered with spam phone calls that attempt to lure the call recipient into responding by voice.
Chatbot scams are such a problem that the U.S. Federal Trade Commission called out concerns for the use of LLMs and other technology to simulate human behavior for deep fake videos and voice clones applied in imposter scams and financial fraud.
How Is Generative AI Tackling Misuse and Fraud Detection?
Fraud review has a powerful new tool. Workers handling manual fraud reviews can now be assisted with LLM-based assistants running RAG on the backend to tap into information from policy documents that can help expedite decision-making on whether cases are fraudulent, vastly accelerating the process.
LLMs are being adopted to predict the next transaction of a customer, which can help payments firms preemptively assess risks and block fraudulent transactions.
Generative AI also helps combat transaction fraud by improving accuracy, generating reports, reducing investigations and mitigating compliance risk.
Generating synthetic data is another important application of generative AI for fraud prevention. Synthetic data can improve the number of data records used to train fraud detection models and increase the variety and sophistication of examples to teach the AI to recognize the latest techniques employed by fraudsters.
NVIDIA offers tools to help enterprises embrace generative AI to build chatbots and virtual agents with a workflow that uses retrieval-augmented generation. RAG enables companies to use natural language prompts to access vast datasets for information retrieval.
Harnessing NVIDIA AI workflows can help accelerate building and deploying enterprise-grade capabilities to accurately produce responses for various use cases, using foundation models, the NVIDIA NeMo framework, NVIDIA Triton Inference Server and GPU-accelerated vector database to deploy RAG-powered chatbots.
There’s an industry focus on safety to ensure generative AI isn’t easily exploited for harm. NVIDIA released NeMo Guardrails to help ensure that intelligent applications powered by LLMs, such as OpenAI’s ChatGPT, are accurate, appropriate, on topic and secure.
The open-source software is designed to help keep AI-powered applications from being exploited for fraud and other misuses.
What Are the Benefits of AI for Fraud Detection?
Fraud detection has been a challenge across banking, finance, retail and e-commerce. Fraud doesn’t only hurt organizations financially, it can also do reputational harm.
It’s a headache for consumers, as well, when fraud models from financial services firms overreact and register false positives that shut down legitimate transactions.
So financial services sectors are developing more advanced models using more data to fortify themselves against losses financially and reputationally. They’re also aiming to reduce false positives in fraud detection for transactions to improve customer satisfaction and win greater share among merchants.
Financial Services Firms Embrace AI for Identity Verification
The financial services industry is developing AI for identity verification. AI-driven applications using deep learning with graph neural networks (GNNs), natural language processing (NLP) and computer vision can improve identity verification for know-your customer (KYC) and anti-money laundering (AML) requirements, leading to improved regulatory compliance and reduced costs.
Computer vision analyzes photo documentation such as drivers licenses and passports to identify fakes. At the same time, NLP reads the documents to measure the veracity of the data on the documents as the AI analyzes them to look for fraudulent records.
Gains in KYC and AML requirements have massive regulatory and economic implications. Financial institutions, including banks, were fined nearly $5 billion for AML, breaching sanctions as well as failures in KYC systems in 2022, according to the Financial Times.
Harnessing Graph Neural Networks and NVIDIA GPUs
GNNs have been embraced for their ability to reveal suspicious activity. They’re capable of looking at billions of records and identifying previously unknown patterns of activity to make correlations about whether an account has in the past sent a transaction to a suspicious account.
NVIDIA has an alliance with the Deep Graph Library team, as well as the PyTorch Geometric team, which provides a GNN framework containerized offering that includes the latest updates, NVIDIA RAPIDS libraries and more to help users stay up to date on cutting-edge techniques.
These GNN framework containers are NVIDIA-optimized and performance-tuned and tested to get the most out of NVIDIA GPUs.
With access to the NVIDIA AI Enterprise software platform, developers can tap into NVIDIA RAPIDS, NVIDIA Triton Inference Server and the NVIDIA TensorRT software development kit to support enterprise deployments at scale.
Improving Anomaly Detection With GNNs
Fraudsters have sophisticated techniques and can learn ways to outmaneuver fraud detection systems. One way is by unleashing complex chains of transactions to avoid notice. This is where traditional rules-based systems can miss patterns and fail.
GNNs build on a concept of representation within the model of local structure and feature context. The information from the edge and node features is propagated with aggregation and message passing among neighboring nodes.
When GNNs run multiple layers of graph convolution, the final node states contain information from nodes multiple hops away. The larger receptive field of GNNs can track the more complex and longer transaction chains used by financial fraud perpetrators in attempts to obscure their tracks.
GNNs Enable Training Unsupervised or Self-Supervised
Detecting financial fraud patterns at massive scale is challenged by the tens of terabytes of transaction data that needs to be analyzed in the blink of an eye and a relative lack of labeled data for real fraud activity needed to train models.
While GNNs can cast a wider detection net on fraud patterns, they can also train on an unsupervised or self-supervised task.
By using techniques such as Bootstrapped Graph Latents — a graph representation learning method — or link prediction with negative sampling, GNN developers can pretrain models without labels and fine-tune models with far fewer labels, producing strong graph representations. The output of this can be used for models like XGBoost, GNNs or techniques for clustering, offering better results when deployed for inference.
Tackling Model Explainability and Bias
GNNs also enable model explainability with a suite of tools. Explainable AI is an industry practice that enables organizations to use such tools and techniques to explain how AI models make decisions, allowing them to safeguard against bias.
Heterogeneous graph transformer and graph attention network, which are GNN models, enable attention mechanisms across each layer of the GNN, allowing developers to identify message paths that GNNs use to reach a final output.
Even without an attention mechanism, techniques such as GNNExplainer, PGExplainer and GraphMask have been suggested to explain GNN outputs.
Leading Financial Services Firms Embrace AI for Gains
- American Express: Improved fraud detection accuracy by 6% with deep learning models and used NVIDIA TensorRT on NVIDIA Triton Inference Server.
- BNY Mellon: Bank of New York Mellon improved fraud detection accuracy by 20% with federated learning. BNY built a collaborative fraud detection framework that runs Inpher’s secure multi-party computation, which safeguards third-party data on NVIDIA DGX systems.
- PayPal: PayPal sought a new fraud detection system that could operate worldwide continuously to protect customer transactions from potential fraud in real time. The company delivered a new level of service, using NVIDIA GPU-powered inference to improve real-time fraud detection by 10% while lowering server capacity nearly 8x.
- Swedbank: Among Sweden’s largest banks, Swedbank trained NVIDIA GPU-driven generative adversarial networks to detect suspicious activities in efforts to stop fraud and money laundering.
Learn how NVIDIA AI Enterprise addresses fraud detection at this webinar.
]]>Great companies thrive on stories. Sid Siddeek, who runs NVIDIA’s venture capital arm, knows this well.
Siddeek still remembers one of his first jobs, schlepping presentation materials from one investor meeting to another, helping the startup’s CEO and management team get the story out while working from a trailer that “shook when the door opened,” he said.
That CEO was Jensen Huang. The startup was NVIDIA.
Siddeek, who has worked as an investor and an entrepreneur, knows how important it is to find the right people to share your company’s story with early on, whether they’re customers or partners, employees or investors.
It’s this very principle that underpins NVIDIA’s multifaceted approach to investing in the next wave of innovation, a strategy also championed by Vishal Bhagwati, who leads NVIDIA’s corporate development efforts.
It’s an effort that’s resulted in more than two dozen investments so far this year, accelerating as the pace of innovation in AI and accelerated computing quickens.
NVIDIA’s Three-Pronged Strategy to Support the AI Ecosystem
There are three ways that NVIDIA invests in the ecosystem, driving the transformation unleashed by accelerated computing. First, through NVIDIA’s corporate investments, overseen by Bhagwati. Second, through NVentures, our venture capital arm, led by Siddeek. And finally, through NVIDIA Inception, our vehicle for supporting startups and connecting them to venture capital.
There couldn’t be a better time to support companies harnessing NVIDIA technologies. AI alone could contribute more than $15 trillion to the global economy by 2030, according to PwC.
And if you’re working in AI and accelerated computing right now, NVIDIA stands ready to help. Developers across every industry in every country are building accelerated computing applications. And they’re just getting going.
The result is a collection of companies that are advancing the story of AI every day. They include Cohere, CoreWeave, Hugging Face, Inflection, Inceptive and many more. And we’re right alongside them.
“Partnering with NVIDIA is a game-changer,” said Ed Mehr, CEO of Machina Labs. “Their unmatched expertise will supercharge our AI and simulation capabilities.”
Corporate Investments: Growing Our Ecosystem
NVIDIA’s corporate investments arm focuses on strategic collaborations. These partnerships stimulate joint innovation, enhance the NVIDIA platform and expand the ecosystem. Since the beginning of 2023, announcements have been made about 14 investments.
These target companies include Ayar Labs, specializing in chip-to-chip optical connectivity, and Hugging Face, a hub for advanced AI models.
The portfolio also includes next-generation enterprise solutions. Databricks offers an industry-leading data platform for machine learning, while Cohere provides enterprise automation through AI. Other notable companies are Recursion, Kore.ai and Utilidata, each contributing unique solutions in drug discovery, conversational AI and smart electricity grids, respectively.
Consumer services are another investment focus. Inflection is crafting a personal AI for creative expression, while Runway serves as a platform for art and creativity through generative AI.
The investment strategy extends to autonomous machines. Ready Robotics is developing an operating system for industrial robotics, and Skydio builds autonomous drones.
NVIDIA’s most recent investments are in cloud service providers like CoreWeave. These platforms cater to a diverse clientele, from startups to Fortune 500 companies seeking to build next-generation AI services.
NVentures: Investing Alongside Entrepreneurs
Through NVentures, we support innovators who are deeply relevant to NVIDIA. We aim to generate strong financial returns and expand the ecosystem by funding companies that use our platforms across a wide range of industries.
To date, NVentures has made 19 investments in companies in healthcare, manufacturing and other key verticals. Some examples of our portfolio companies include:
- Genesis Therapeutics, Inceptive, Terray, Charm, Evozyne, Generate, Superluminal: revolutionizing drug discovery
- Machina Labs, Seurat Technologies: disrupting industrial processes to improve manufacturing
- PassiveLogic: automating building systems with AI
- MindsDB: for developers that need to connect enterprise data to AI
- Moon Surgical: improving laparoscopic surgery with AI
- Twelve Labs: developing multimodal foundation models for video understanding
- Flywheel: accelerating medical imaging data development
- Luma AI: developers of visual and multimodal models
- Outrider: automating logistics hub operation
- Synthesia: AI Video for the enterprise
- Replicate: developer platform for open-source and custom models
All these companies are building on work being done inside and outside NVIDIA.
“NVentures has a network, not just within NVIDIA, but throughout the industry, to make sure we have access to the best technology and the best people to build all the different modules that have to come together to define the distribution and supply chain of the future,” said Andrew Smith, CEO of Outrider.
NVIDIA Inception: Supporting Startups and Connecting Them to Investors
In addition, we’re continuing to support startups with NVIDIA Inception. Launched in 2016, this free global program offers technology and marketing support to over 17,000 startups across multiple industries and over 125 countries.
And, as part of Inception, we’re partnering with venture capitalists through our VC Alliance, a program that offers benefits to our valued network of venture capital firms, including connecting startups with potential investors.
Partnering With Innovators in Every Industry
Whatever our relationship, whether as a partner or investor, we can offer companies unique forms of support.
NVIDIA has the technology. NVIDIA has the richest set of libraries and the deepest understanding of the frameworks needed to optimize training and inference pipelines.
We have the go-to-market skills. NVIDIA has tremendous field sales, solution architect and developer relations organizations with a long track record of working with the most innovative startups and the largest companies in the world.
We know how to grow. We have people throughout our organization who are recognized leaders in their respective fields and can offer expert advice to companies of all sizes and industries.
“Partnering with NVIDIA was an easy choice,” said Victor Riparbelli, cofounder and CEO of Synthesia. “We use their hardware, benefit from their AI expertise and get valuable insights, allowing us to build better products faster.”
Accelerating the Greatest Breakthroughs of Our Time
In turn, these investments augment our R&D in the software, systems and semiconductors undergirding this ecosystem.
With NVIDIA’s technologies poised to accelerate the work of researchers and scientists, entrepreneurs, startups and Fortune 500 companies, finding ways to support companies that rely on our technologies— with engineering resources, marketing support and capital — is more vital than ever.
]]>GPUs have been called the rare Earth metals — even the gold — of artificial intelligence, because they’re foundational for today’s generative AI era.
Three technical reasons, and many stories, explain why that’s so. Each reason has multiple facets well worth exploring, but at a high level:
- GPUs employ parallel processing.
- GPU systems scale up to supercomputing heights.
- The GPU software stack for AI is broad and deep.
The net result is GPUs perform technical calculations faster and with greater energy efficiency than CPUs. That means they deliver leading performance for AI training and inference as well as gains across a wide array of applications that use accelerated computing.
In its recent report on AI, Stanford’s Human-Centered AI group provided some context. GPU performance “has increased roughly 7,000 times” since 2003 and price per performance is “5,600 times greater,” it reported.
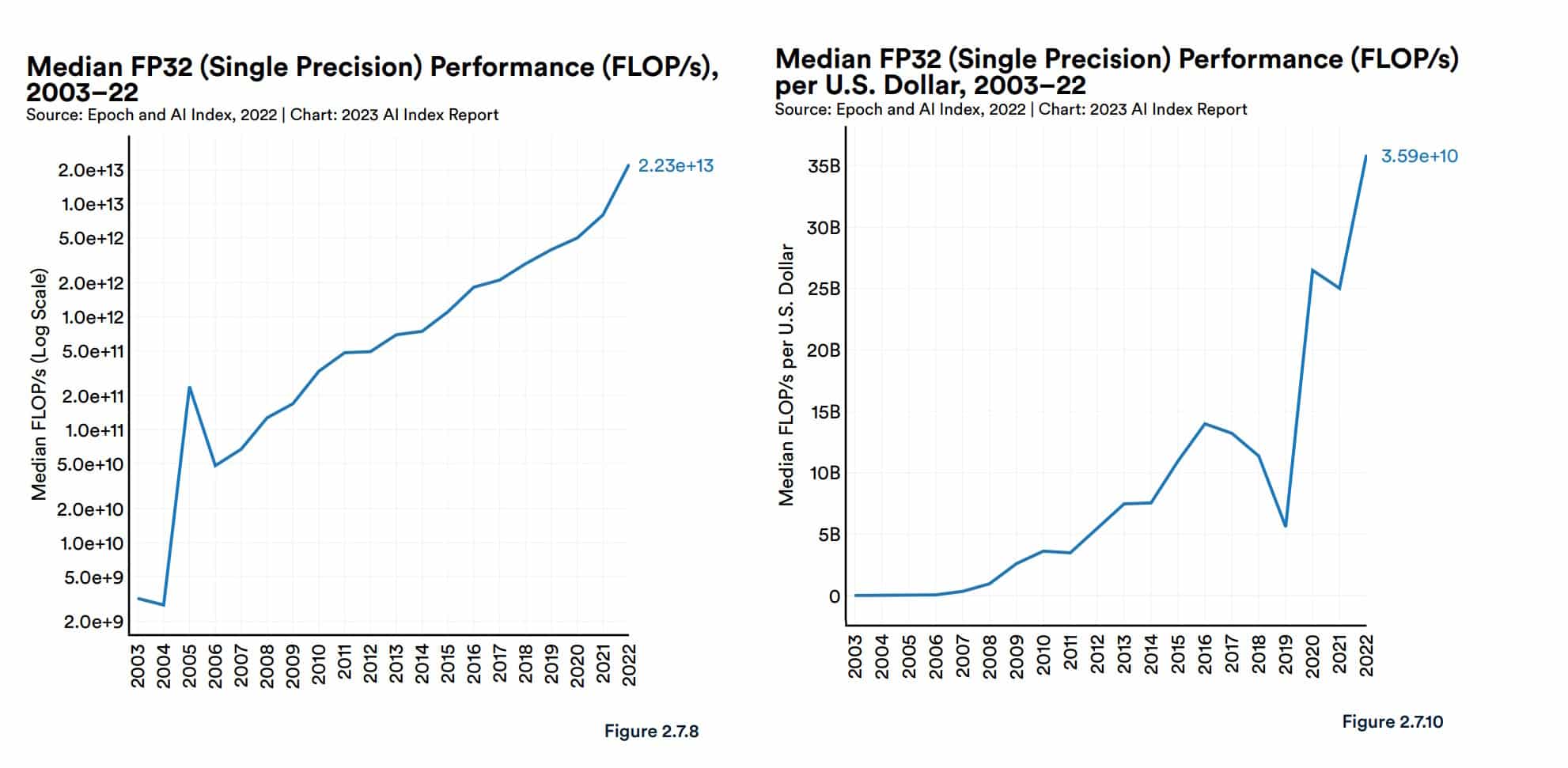
The report also cited analysis from Epoch, an independent research group that measures and forecasts AI advances.
“GPUs are the dominant computing platform for accelerating machine learning workloads, and most (if not all) of the biggest models over the last five years have been trained on GPUs … [they have] thereby centrally contributed to the recent progress in AI,” Epoch said on its site.
A 2020 study assessing AI technology for the U.S. government drew similar conclusions.
“We expect [leading-edge] AI chips are one to three orders of magnitude more cost-effective than leading-node CPUs when counting production and operating costs,” it said.
NVIDIA GPUs have increased performance on AI inference 1,000x in the last ten years, said Bill Dally, the company’s chief scientist in a keynote at Hot Chips, an annual gathering of semiconductor and systems engineers.
ChatGPT Spread the News
ChatGPT provided a powerful example of how GPUs are great for AI. The large language model (LLM), trained and run on thousands of NVIDIA GPUs, runs generative AI services used by more than 100 million people.
Since its 2018 launch, MLPerf, the industry-standard benchmark for AI, has provided numbers that detail the leading performance of NVIDIA GPUs on both AI training and inference.
For example, NVIDIA Grace Hopper Superchips swept the latest round of inference tests. NVIDIA TensorRT-LLM, inference software released since that test, delivers up to an 8x boost in performance and more than a 5x reduction in energy use and total cost of ownership. Indeed, NVIDIA GPUs have won every round of MLPerf training and inference tests since the benchmark was released in 2019.
In February, NVIDIA GPUs delivered leading results for inference, serving up thousands of inferences per second on the most demanding models in the STAC-ML Markets benchmark, a key technology performance gauge for the financial services industry.
A RedHat software engineering team put it succinctly in a blog: “GPUs have become the foundation of artificial intelligence.”
AI Under the Hood
A brief look under the hood shows why GPUs and AI make a powerful pairing.
An AI model, also called a neural network, is essentially a mathematical lasagna, made from layer upon layer of linear algebra equations. Each equation represents the likelihood that one piece of data is related to another.
For their part, GPUs pack thousands of cores, tiny calculators working in parallel to slice through the math that makes up an AI model. This, at a high level, is how AI computing works.
Highly Tuned Tensor Cores
Over time, NVIDIA’s engineers have tuned GPU cores to the evolving needs of AI models. The latest GPUs include Tensor Cores that are 60x more powerful than the first-generation designs for processing the matrix math neural networks use.
In addition, NVIDIA Hopper Tensor Core GPUs include a Transformer Engine that can automatically adjust to the optimal precision needed to process transformer models, the class of neural networks that spawned generative AI.
Along the way, each GPU generation has packed more memory and optimized techniques to store an entire AI model in a single GPU or set of GPUs.
Models Grow, Systems Expand
The complexity of AI models is expanding a whopping 10x a year.
The current state-of-the-art LLM, GPT4, packs more than a trillion parameters, a metric of its mathematical density. That’s up from less than 100 million parameters for a popular LLM in 2018.
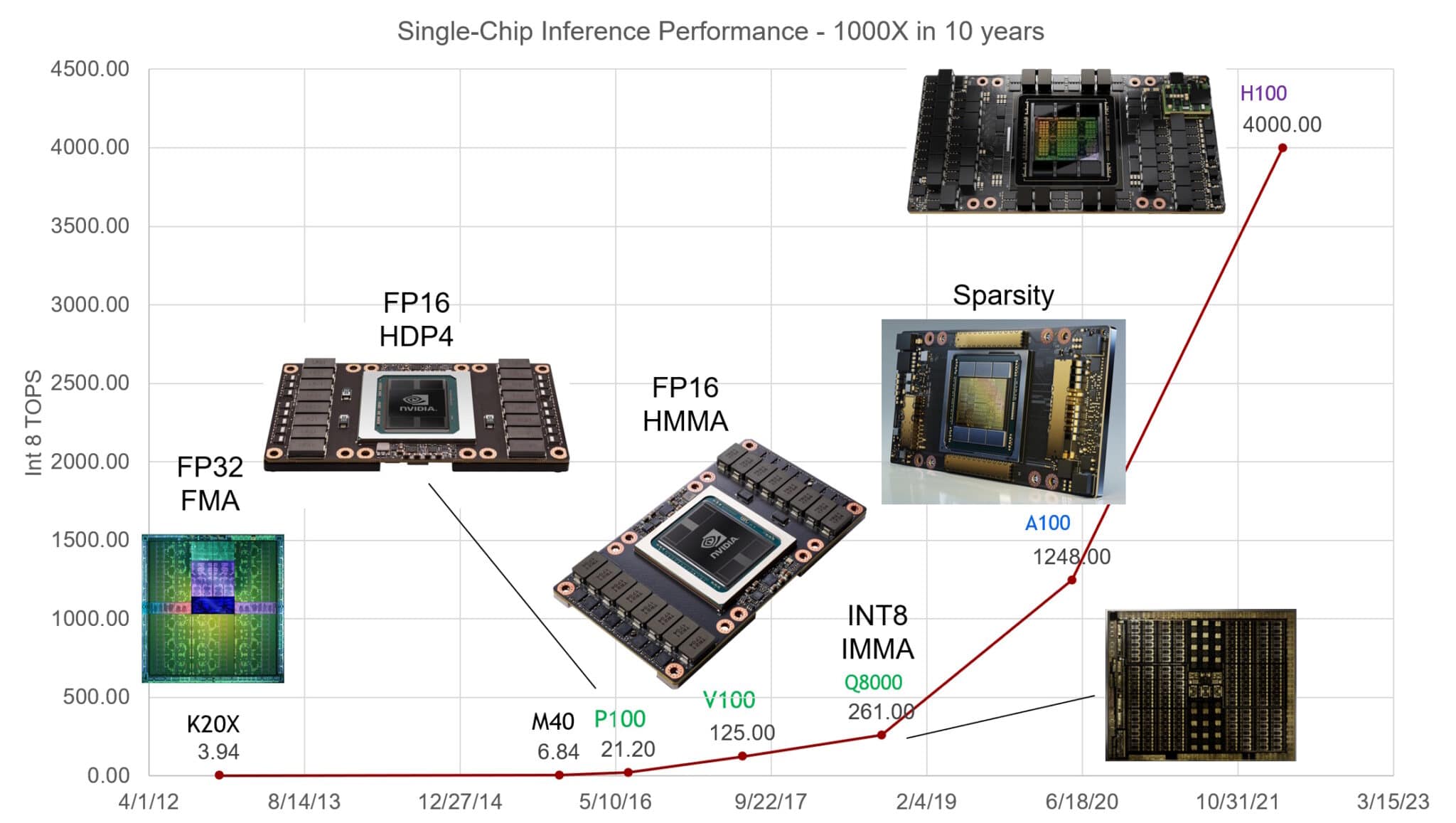
GPU systems have kept pace by ganging up on the challenge. They scale up to supercomputers, thanks to their fast NVLink interconnects and NVIDIA Quantum InfiniBand networks.
For example, the DGX GH200, a large-memory AI supercomputer, combines up to 256 NVIDIA GH200 Grace Hopper Superchips into a single data-center-sized GPU with 144 terabytes of shared memory.
Each GH200 superchip is a single server with 72 Arm Neoverse CPU cores and four petaflops of AI performance. A new four-way Grace Hopper systems configuration puts in a single compute node a whopping 288 Arm cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
And NVIDIA H200 Tensor Core GPUs announced in November pack up to 288 gigabytes of the latest HBM3e memory technology.
Software Covers the Waterfront
An expanding ocean of GPU software has evolved since 2007 to enable every facet of AI, from deep-tech features to high-level applications.
The NVIDIA AI platform includes hundreds of software libraries and apps. The CUDA programming language and the cuDNN-X library for deep learning provide a base on top of which developers have created software like NVIDIA NeMo, a framework to let users build, customize and run inference on their own generative AI models.
Many of these elements are available as open-source software, the grab-and-go staple of software developers. More than a hundred of them are packaged into the NVIDIA AI Enterprise platform for companies that require full security and support. Increasingly, they’re also available from major cloud service providers as APIs and services on NVIDIA DGX Cloud.
SteerLM, one of the latest AI software updates for NVIDIA GPUs, lets users fine tune models during inference.
A 70x Speedup in 2008
Success stories date back to a 2008 paper from AI pioneer Andrew Ng, then a Stanford researcher. Using two NVIDIA GeForce GTX 280 GPUs, his three-person team achieved a 70x speedup over CPUs processing an AI model with 100 million parameters, finishing work that used to require several weeks in a single day.
“Modern graphics processors far surpass the computational capabilities of multicore CPUs, and have the potential to revolutionize the applicability of deep unsupervised learning methods,” they reported.

In a 2015 talk at NVIDIA GTC, Ng described how he continued using more GPUs to scale up his work, running larger models at Google Brain and Baidu. Later, he helped found Coursera, an online education platform where he taught hundreds of thousands of AI students.
Ng counts Geoff Hinton, one of the godfathers of modern AI, among the people he influenced. “I remember going to Geoff Hinton saying check out CUDA, I think it can help build bigger neural networks,” he said in the GTC talk.
The University of Toronto professor spread the word. “In 2009, I remember giving a talk at NIPS [now NeurIPS], where I told about 1,000 researchers they should all buy GPUs because GPUs are going to be the future of machine learning,” Hinton said in a press report.
Fast Forward With GPUs
AI’s gains are expected to ripple across the global economy.
A McKinsey report in June estimated that generative AI could add the equivalent of $2.6 trillion to $4.4 trillion annually across the 63 use cases it analyzed in industries like banking, healthcare and retail. So, it’s no surprise Stanford’s 2023 AI report said that a majority of business leaders expect to increase their investments in AI.
Today, more than 40,000 companies use NVIDIA GPUs for AI and accelerated computing, attracting a global community of 4 million developers. Together they’re advancing science, healthcare, finance and virtually every industry.
Among the latest achievements, NVIDIA described a whopping 700,000x speedup using AI to ease climate change by keeping carbon dioxide out of the atmosphere (see video below). It’s one of many ways NVIDIA is applying the performance of GPUs to AI and beyond.
Learn how GPUs put AI into production.
Explore generative AI sessions and experiences at NVIDIA GTC, the global conference on AI and accelerated computing, running March 18-21 in San Jose, Calif., and online.
]]>Generative AI is the latest turn in the fast-changing digital landscape. One of the groundbreaking innovations making it possible is a relatively new term: SuperNIC.
What Is a SuperNIC?
SuperNIC is a new class of network accelerators designed to supercharge hyperscale AI workloads in Ethernet-based clouds. It provides lightning-fast network connectivity for GPU-to-GPU communication, achieving speeds reaching 400Gb/s using remote direct memory access (RDMA) over converged Ethernet (RoCE) technology.
SuperNICs combine the following unique attributes:
- High-speed packet reordering, featured when combined with an NVIDIA network switch, ensure that data packets are received and processed in the same order they were originally transmitted. This maintains the sequential integrity of the data flow.
- Advanced congestion control using real-time telemetry data and network-aware algorithms to manage and prevent congestion in AI networks.
- Programmable compute on the input/output (I/O) path to enable customization and extensibility of network infrastructure in AI cloud data centers.
- Power-efficient, low-profile design to efficiently accommodate AI workloads within constrained power budgets.
- Full-stack AI optimization, including compute, networking, storage, system software, communication libraries and application frameworks.
NVIDIA recently unveiled the world’s first SuperNIC tailored for AI computing, based on the BlueField-3 networking platform. It’s a part of the NVIDIA Spectrum-X platform, where it integrates seamlessly with the Spectrum-4 Ethernet switch system.
Together, the NVIDIA BlueField-3 SuperNIC and Spectrum-4 switch system form the foundation of an accelerated computing fabric specifically designed to optimize AI workloads. Spectrum-X consistently delivers high network efficiency levels, outperforming traditional Ethernet environments.
“In a world where AI is driving the next wave of technological innovation, the BlueField-3 SuperNIC is a vital cog in the machinery,” said Yael Shenhav, vice president of DPU and NIC products at NVIDIA. “SuperNICs ensure that your AI workloads are executed with efficiency and speed, making them foundational components for enabling the future of AI computing.”
The Evolving Landscape of AI and Networking
The AI field is undergoing a seismic shift, thanks to the advent of generative AI and large language models. These powerful technologies have unlocked new possibilities, enabling computers to handle new tasks.
AI success relies heavily on GPU-accelerated computing to process mountains of data, train large AI models, and enable real-time inference. This new compute power has opened new possibilities, but it has also challenged Ethernet cloud networks.
Traditional Ethernet, the technology that underpins internet infrastructure, was conceived to offer broad compatibility and connect loosely coupled applications. It wasn’t designed to handle the demanding computational needs of modern AI workloads, which involve tightly coupled parallel processing, rapid data transfers and unique communication patterns — all of which demand optimized network connectivity.
Foundational network interface cards (NICs) were designed for general-purpose computing, universal data transmission and interoperability. They were never designed to cope with the unique challenges posed by the computational intensity of AI workloads.
Standard NICs lack the requisite features and capabilities for efficient data transfer, low latency and the deterministic performance crucial for AI tasks. SuperNICs, on the other hand, are purpose-built for modern AI workloads.
SuperNIC Advantages in AI Computing Environments
Data processing units (DPUs) deliver a wealth of advanced features, offering high throughput, low-latency network connectivity and more. Since their introduction in 2020, DPUs have gained popularity in the realm of cloud computing, primarily due to their capacity to offload, accelerate and isolate data center infrastructure processing.
Although DPUs and SuperNICs share a range of features and capabilities, SuperNICs are uniquely optimized for accelerating networks for AI. The chart below shows how they compare:
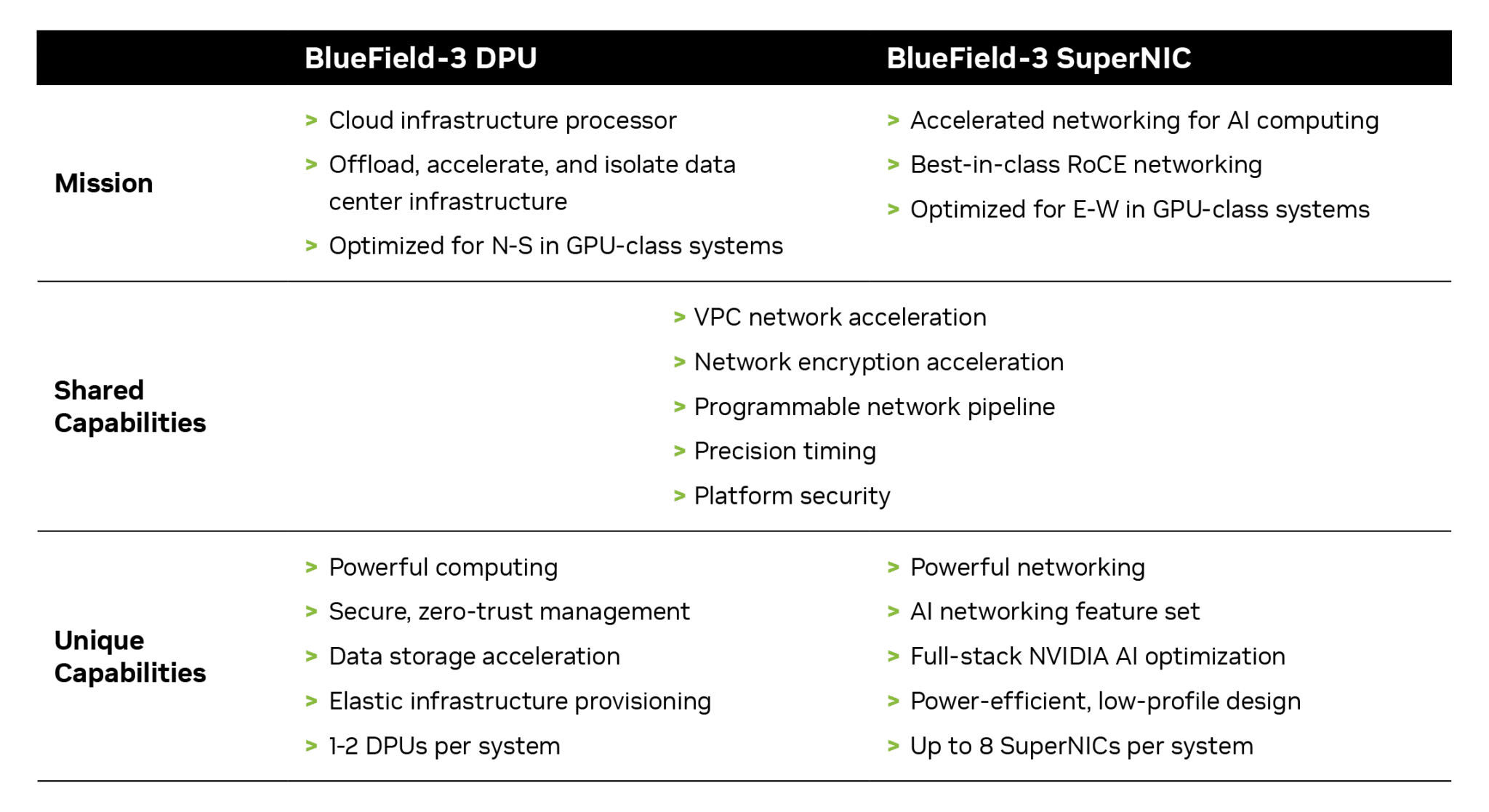
Distributed AI training and inference communication flows depend heavily on network bandwidth availability for success. SuperNICs, distinguished by their sleek design, scale more effectively than DPUs, delivering an impressive 400Gb/s of network bandwidth per GPU.
The 1:1 ratio between GPUs and SuperNICs within a system can significantly enhance AI workload efficiency, leading to greater productivity and superior outcomes for enterprises.
The sole purpose of SuperNICs is to accelerate networking for AI cloud computing. Consequently, it achieves this goal using less computing power than a DPU, which requires substantial computational resources to offload applications from a host CPU.
The reduced computing requirements also translate to lower power consumption, which is especially crucial in systems containing up to eight SuperNICs.
Additional distinguishing features of the SuperNIC include its dedicated AI networking capabilities. When tightly integrated with an AI-optimized NVIDIA Spectrum-4 switch, it offers adaptive routing, out-of-order packet handling and optimized congestion control. These advanced features are instrumental in accelerating Ethernet AI cloud environments.
Revolutionizing AI Cloud Computing
The NVIDIA BlueField-3 SuperNIC offers several benefits that make it key for AI-ready infrastructure:
- Peak AI workload efficiency: The BlueField-3 SuperNIC is purpose-built for network-intensive, massively parallel computing, making it ideal for AI workloads. It ensures that AI tasks run efficiently — without bottlenecks.
- Consistent and predictable performance: In multi-tenant data centers where numerous tasks are processed simultaneously, the BlueField-3 SuperNIC ensures that each job and tenant’s performance is isolated, predictable and unaffected by other network activities.
- Secure multi-tenant cloud infrastructure: Security is a top priority, especially in data centers handling sensitive information. The BlueField-3 SuperNIC maintains high security levels, enabling multiple tenants to coexist while keeping data and processing isolated.
- Extensible network infrastructure: The BlueField-3 SuperNIC isn’t limited in scope — it’s highly flexible and adaptable to a myriad of other network infrastructure needs.
- Broad server manufacturer support: The BlueField-3 SuperNIC fits seamlessly into most enterprise-class servers without excessive power consumption in data centers.
Learn more about NVIDIA BlueField-3 SuperNICs, including how they integrate across NVIDIA’s data center platforms, in the whitepaper: Next-Generation Networking for the Next Wave of AI.
]]>In the wake of ChatGPT, every company is trying to figure out its AI strategy, work that quickly raises the question: What about security?
Some may feel overwhelmed at the prospect of securing new technology. The good news is policies and practices in place today provide excellent starting points.
Indeed, the way forward lies in extending the existing foundations of enterprise and cloud security. It’s a journey that can be summarized in six steps:
- Expand analysis of the threats
- Broaden response mechanisms
- Secure the data supply chain
- Use AI to scale efforts
- Be transparent
- Create continuous improvements
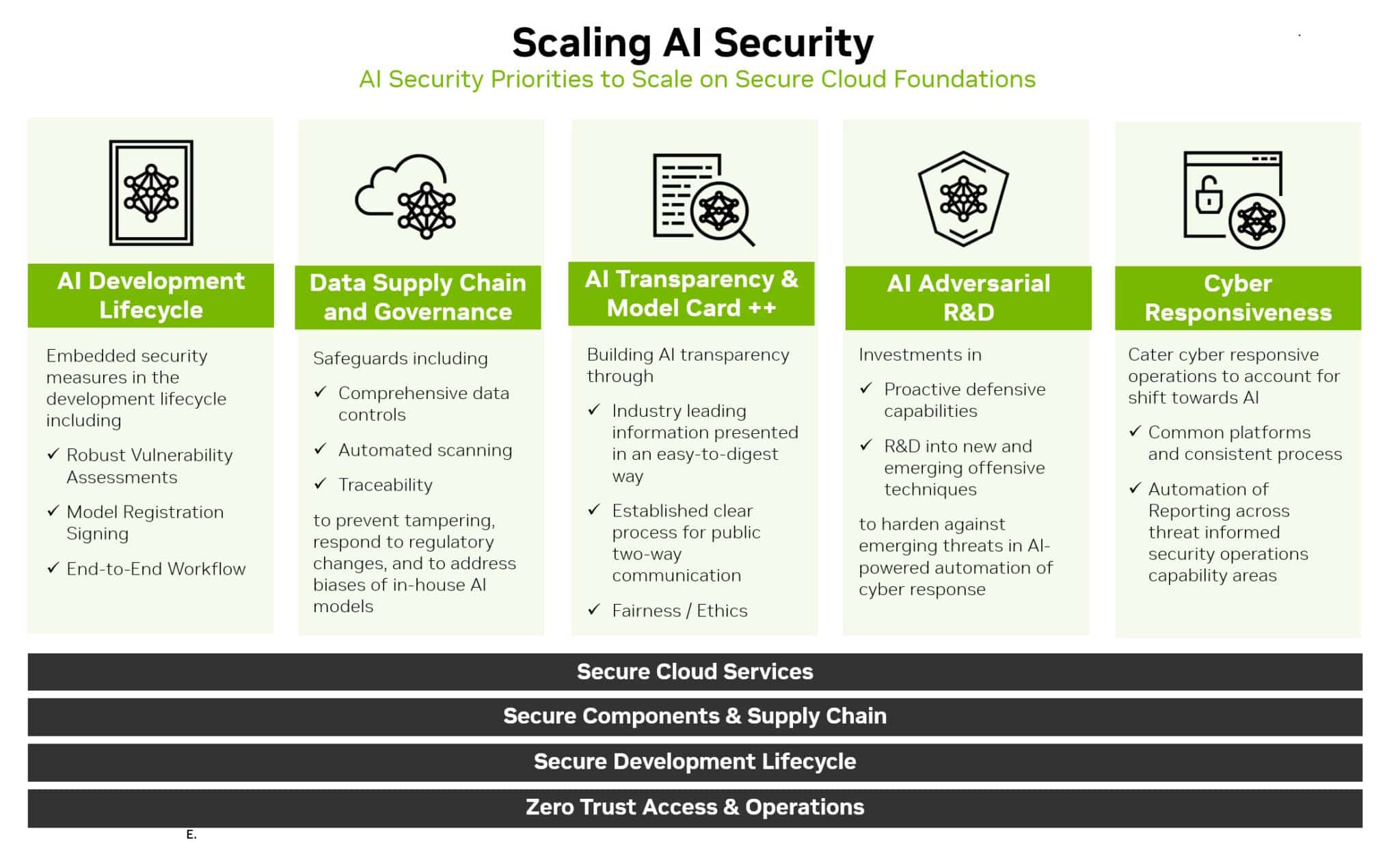
Take in the Expanded Horizon
The first step is to get familiar with the new landscape.
Security now needs to cover the AI development lifecycle. This includes new attack surfaces like training data, models and the people and processes using them.
Extrapolate from the known types of threats to identify and anticipate emerging ones. For instance, an attacker might try to alter the behavior of an AI model by accessing data while it’s training the model on a cloud service.
The security researchers and red teams who probed for vulnerabilities in the past will be great resources again. They’ll need access to AI systems and data to identify and act on new threats as well as help building solid working relationships with data science staff.
Broaden Defenses
Once a picture of the threats is clear, define ways to defend against them.
Monitor AI model performance closely. Assume it will drift, opening new attack surfaces, just as it can be assumed that traditional security defenses will be breached.
Also build on the PSIRT (product security incident response team) practices that should already be in place.
For example, NVIDIA released product security policies that encompass its AI portfolio. Several organizations — including the Open Worldwide Application Security Project — have released AI-tailored implementations of key security elements such as the common vulnerability enumeration method used to identify traditional IT threats.
Adapt and apply to AI models and workflows traditional defenses like:
- Keeping network control and data planes separate
- Removing any unsafe or personal identifying data
- Using zero-trust security and authentication
- Defining appropriate event logs, alerts and tests
- Setting flow controls where appropriate
Extend Existing Safeguards
Protect the datasets used to train AI models. They’re valuable and vulnerable.
Once again, enterprises can leverage existing practices. Create secure data supply chains, similar to those created to secure channels for software. It’s important to establish access control for training data, just like other internal data is secured.
Some gaps may need to be filled. Today, security specialists know how to use hash files of applications to ensure no one has altered their code. That process may be challenging to scale for petabyte-sized datasets used for AI training.
The good news is researchers see the need, and they’re working on tools to address it.
Scale Security With AI
AI is not only a new attack area to defend, it’s also a new and powerful security tool.
Machine learning models can detect subtle changes no human can see in mountains of network traffic. That makes AI an ideal technology to prevent many of the most widely used attacks, like identity theft, phishing, malware and ransomware.
NVIDIA Morpheus, a cybersecurity framework, can build AI applications that create, read and update digital fingerprints that scan for many kinds of threats. In addition, generative AI and Morpheus can enable new ways to detect spear phishing attempts.
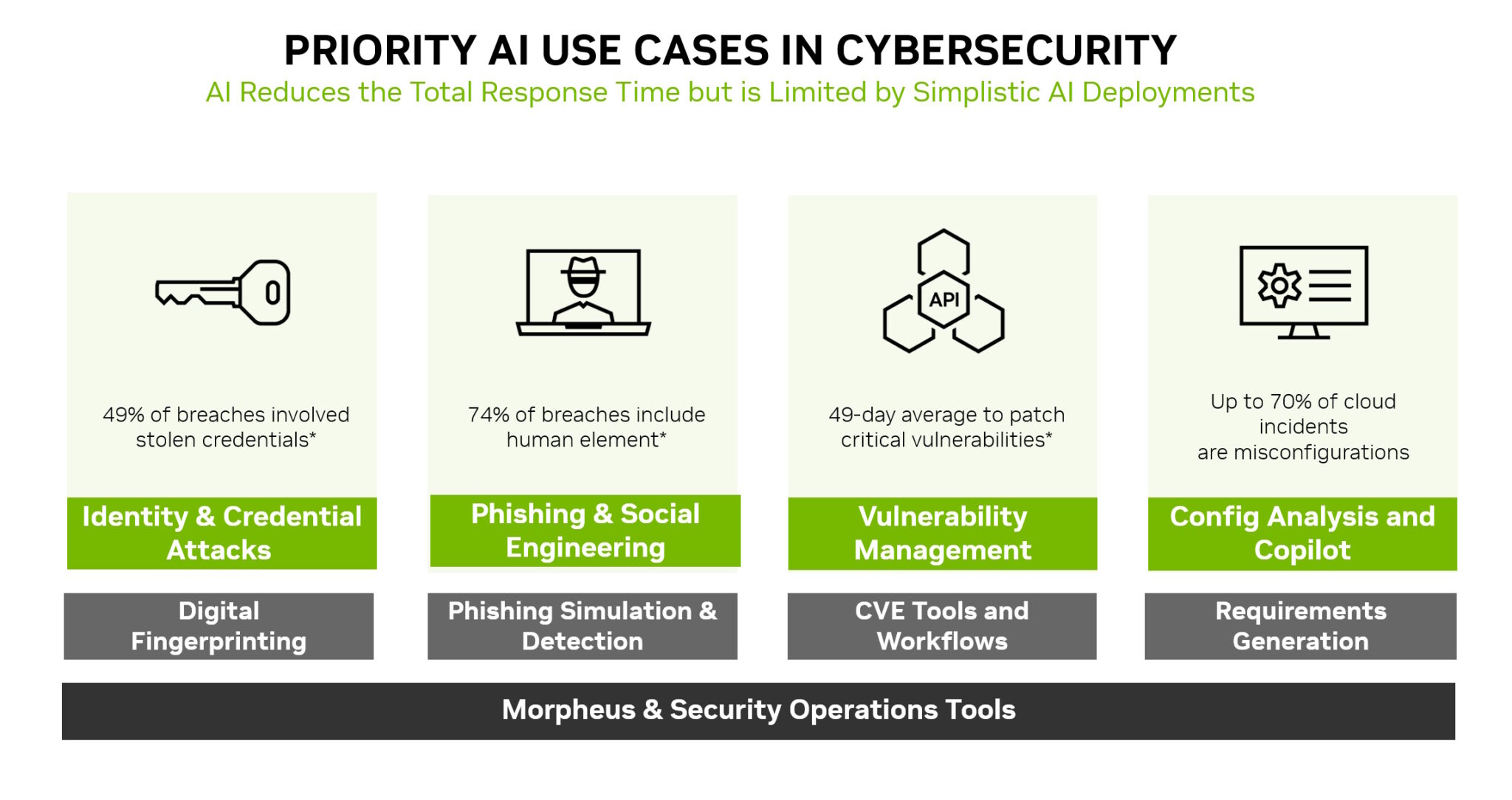
Security Loves Clarity
Transparency is a key component of any security strategy. Let customers know about any new AI security policies and practices that have been put in place.
For example, NVIDIA publishes details about the AI models in NGC, its hub for accelerated software. Called model cards, they act like truth-in-lending statements, describing AIs, the data they were trained on and any constraints for their use.
NVIDIA uses an expanded set of fields in its model cards, so users are clear about the history and limits of a neural network before putting it into production. That helps advance security, establish trust and ensure models are robust.
Define Journeys, Not Destinations
These six steps are just the start of a journey. Processes and policies like these need to evolve.
The emerging practice of confidential computing, for instance, is extending security across cloud services where AI models are often trained and run in production.
The industry is already beginning to see basic versions of code scanners for AI models. They’re a sign of what’s to come. Teams need to keep an eye on the horizon for best practices and tools as they arrive.
Along the way, the community needs to share what it learns. An excellent example of that occurred at the recent Generative Red Team Challenge.
In the end, it’s about creating a collective defense. We’re all making this journey to AI security together, one step at a time.
]]>Gone are the days when AI was the domain of sprawling data centers or elite researchers.
For GeForce RTX users, AI is now running on your PC. It’s personal, enhancing every keystroke, every frame and every moment.
Gamers are already enjoying the benefits of AI in over 300 RTX games. Meanwhile, content creators have access to over 100 RTX creative and design apps, with AI enhancing everything from video and photo editing to asset generation.
And for GeForce enthusiasts, it’s just the beginning. RTX is the platform for today and the accelerator that will power the AI of tomorrow.
How Did AI and Gaming Converge?
NVIDIA pioneered the integration of AI and gaming with DLSS, a technique that uses AI to generate pixels in video games automatically and which has increased frame rates by up to 4x.
And with the recent introduction of DLSS 3.5, NVIDIA has enhanced the visual quality in some of the world’s top titles, setting a new standard for visually richer and more immersive gameplay.
But NVIDIA’s AI integration doesn’t stop there. Tools like RTX Remix empower game modders to remaster classic content using high-quality textures and materials generated by AI.
With NVIDIA ACE for Games, AI-powered avatars come to life on the PC, marking a new era of immersive gaming.
How Are RTX and AI Powering Creators?
Creators use AI to imagine new concepts, automate tedious tasks and create stunning works of art. They rely on RTX because it accelerates top creator applications, including the world’s most popular photo editing, video editing, broadcast and 3D apps.
With over 100 RTX apps now AI-enabled, creators can get more done and deliver incredible results.
The performance metrics are staggering.
RTX GPUs boost AI image generation speeds in tools like Stable Diffusion by 4.5x compared to competing processors. Meanwhile, in 3D rendering, Blender experiences a speed increase of 5.4x.
Video editing in DaVinci Resolve powered by AI doubles its speed, and Adobe Photoshop’s photo editing tasks become 3x as swift.
NVIDIA RTX AI tech demonstrates a staggering 10x faster speeds in distinct workflows when juxtaposed against its competitors.
NVIDIA provides various AI tools, apps and software development kits designed specifically for creators. This includes exclusive offerings like NVIDIA Omniverse, OptiX Denoiser, NVIDIA Canvas, NVIDIA Broadcast and NVIDIA DLSS.
How Is AI Changing Our Digital Experience Beyond Chatbots?
Beyond gaming and content creation, RTX GPUs bring AI to all types of users.
Add Microsoft to the equation and 100 million RTX-powered Windows 11 PCs and workstations are already AI-ready.
The complementary technologies behind the Windows platform and NVIDIA’s dynamic AI hardware and software stack are the driving forces that power hundreds of Windows apps and games.
- Gamers: RTX-accelerated AI has been adopted in more than 300 games, increasing frame rates and enhancing visual fidelity.
- Creators: More than 100 AI-enabled creative applications benefit from RTX acceleration — including the top apps for image generation, video editing, photo editing and 3D. AI helps artists work faster, automate tedious tasks and expand the boundaries of creative expression.
- Video Streamers: RTX Video Super Resolution uses AI to increase the resolution and improve the quality of streamed video, elevating the home video experience.
- Office Workers and Students: Teleconferencing and remote learning get an RTX boost with NVIDIA Broadcast. AI improves video and audio quality and adds unique effects to make virtual interactions smoother and collaboration more efficient.
- Developers: Thanks to NVIDIA’s world-leading AI development platform and technology developed by Microsoft and NVIDIA called CUDA on Windows Subsystem for Linux, developers can now do early AI development and training from the comfort of Windows, and easily migrate to servers for large training runs.
What Are the Emerging AI Applications for RTX PCs?
Generative AI enables users to quickly generate new content based on a variety of inputs — text, images, sounds, animation, 3D models or other types of data — bringing easy-to-use AI to more PCs.
Large language models (LLMs) are at the heart of many of these use cases.

Perhaps the best known is ChatGPT, a chatbot that runs in the cloud and one of the fastest growing applications in history.
Many of these LLMs now run directly on PC, enabling new end-user applications like automatically drafting documents and emails, summarizing web content, extracting insights from spreadsheet data, planning travel, and powering general-purpose AI assistants.
LLMs are some of the most demanding PC workloads, requiring a powerful AI accelerator — like an RTX GPU.
What Powers the AI Revolution on Our Desktops (and Beyond)?
What’s fueling the PC AI revolution?
Three pillars: lightning-fast graphics processing from GPUs, AI capabilities integral to GeForce and the omnipresent cloud.
Gamers already know all about the parallel processing power of GPUs. But what role did the GPU play in enabling AI in the cloud?
NVIDIA GPUs have transformed cloud services. These advanced systems power everything from voice recognition to autonomous factory operations.
In 2016, NVIDIA hand-delivered to OpenAI the first NVIDIA DGX AI supercomputer — the engine behind the LLM breakthrough powering ChatGPT.
NVIDIA DGX supercomputers, packed with GPUs and used initially as an AI research instrument, are now running 24/7 at businesses worldwide to refine data and process AI. Half of all Fortune 100 companies have installed DGX AI supercomputers.
The cloud, in turn, provides more than just vast quantities of training data for advanced AI models running on these machines.
Why Choose Desktop AI?
But why run AI on your desktop when the cloud seems limitless?
GPU-equipped desktops — where the AI revolution began — are still where the action is.
- Availability: Whether a gamer or a researcher, everyone needs tools — from games to sophisticated AI models used by wildlife researchers in the field — that can function even when offline.
- Speed: Some applications need instantaneous results. Cloud latency doesn’t always cut it.
- Data size: Uploading and downloading large datasets from the cloud can be inefficient and cumbersome.
- Privacy: Whether you’re a Fortune 500 company or just editing family photos and videos, we all have data we want to keep close to home.
RTX GPUs are based on the same architecture that fuels NVIDIA’s cloud performance. They blend the benefits of running AI locally with access to tools and the performance only NVIDIA can deliver.
NPUs, often called inference accelerators, are now finding their way into modern CPUs, highlighting the growing understanding of AI’s critical role in every application.
While NPUs are designed to offload light AI tasks, NVIDIA’s GPUs stand unparalleled for demanding AI models with raw performance ranging from a 20x-100x increase.
What’s Next for AI in Our Everyday Lives?
AI isn’t just a trend — it will impact many aspects of our daily lives.
AI functionality will expand as research advances and user expectations will evolve. Keeping up will require GPUs — and a rich software stack built on top of them — that are up to the challenge.
NVIDIA is at the forefront of this transformative era, offering end-to-end optimized development solutions.
NVIDIA provides developers with tools to add more AI features to PCs, enhancing value for users, all powered by RTX.
From gaming innovations with RTX Remix to the NVIDIA NeMo LLM language model for assisting coders, the AI landscape on the PC is rich and expanding.
Whether it’s stunning new gaming content, AI avatars, incredible tools for creators or the next generation of digital assistants, the promise of AI-powered experiences will continuously redefine the standard of personal computing.
Learn more about GeForce’s AI capabilities.
Thanks to “street views,” modern mapping tools can be used to scope out a restaurant before deciding to go there, better navigate directions by viewing landmarks in the area or simulate the experience of being on the road.
The technique for creating these 3D views is called photogrammetry — the process of capturing images and stitching them together to create a digital model of the physical world.

It’s almost like a jigsaw puzzle, where pieces are collected and then put together to create the bigger picture. In photogrammetry, each puzzle piece is an image. And the more images that are captured and collected, the more realistic and detailed the 3D model will be.
How Photogrammetry Works
Photogrammetry techniques can also be used across industries, including architecture and archaeology. For example, an early example of photogrammetry was from 1849, when French officer Aimé Laussedat used terrestrial photographs to create his first perspective architectural survey at the Hôtel des Invalides in Paris.
By capturing as many photos of an area or environment as possible, teams can build digital models of a site that they can view and analyze.
Unlike 3D scanning, which uses structured laser light to measure the locations of points in a scene, photogrammetry uses actual images to capture an object and turn it into a 3D model. This means good photogrammetry requires a good dataset. It’s also important to take photos in the right pattern, so that every area of a site, monument or artifact is covered.
Types of Photogrammetry Methods
Those looking to stitch together a scene today take multiple pictures of a subject from varying angles, and then run them through a specialized application, which allows them to combine and extract the overlapping data to create a 3D model.

There are two types of photogrammetry: aerial and terrestrial.
Aerial photogrammetry stations the camera in the air to take photos from above. This is generally used on larger sites or in areas that are difficult to access. Aerial photogrammetry is one of the most widely used methods for creating geographic databases in forestry and natural resource management.
Terrestrial photogrammetry, aka close-range photogrammetry, is more object-focused and usually relies on images taken by a camera that’s handheld or on a tripod. It enables speedy onsite data collection and more detailed image captures.
Accelerating Photogrammetry Workflows With GPUs
For the most accurate photogrammetry results, teams need a massive, high-fidelity dataset. More photos will result in greater accuracy and precision. However, large datasets can take longer to process, and teams need more computational power to handle the files.
The latest advancements in GPUs help teams address this. Using advanced GPUs like NVIDIA RTX cards allows users to speed up processing and maintain higher-fidelity models, all while inputting larger datasets.
For example, construction teams often rely on photogrammetry techniques to show progress on construction sites. Some companies capture images of a site to create a virtual walkthrough. But an underpowered system can result in a choppy visual experience, which detracts from a working session with clients or project teams.
With the large memory of RTX professional GPUs, architects, engineers and designers can easily manage massive datasets to create and handle photogrammetry models faster.
Photogrammetry uses GPU power to assist in vectorization of the photo, which accelerates stitching thousands of images together. And with the real-time rendering and AI capabilities of RTX professional GPUs, teams can accelerate 3D workflows, create photorealistic renderings and keep 3D models up to date.
History and Future of Photogrammetry
The idea of photogrammetry dates to the late 1400s, nearly four centuries before the invention of photography. Leonardo da Vinci developed the principles of perspective and projective geometry, which are foundational pillars of photogrammetry.
Geometric perspective is a method that enables illustrating a 3D object in a 2D field by creating points that showcase depth. On top of this foundation, aspects such as geometry, shading and lighting are the building blocks of realistic renderings.
Photogrammetry advancements now allow users to achieve new levels of immersiveness in 3D visualizations. The technique has also paved the way for other groundbreaking tools like reality-capture technology, which collects data on real-world conditions to give users reliable, accurate information about physical objects and environments.
NVIDIA Research is also developing AI techniques that rapidly generate 3D scenes from a small set of images.
Instant NeRF and Neuralangelo, for example, use neural networks to render complete 3D scenes from just a few-dozen still photos or 2D video clips. Instant NeRF could be a powerful tool to help preserve and share cultural artifacts through online libraries, museums, virtual-reality experiences and heritage-conservation projects. Many artists are already creating beautiful scenes from different perspectives with Instant NeRF.
Learn More About Photogrammetry
Objects, locations and even industrial digital twins can be rendered volumetrically — in real time — to be shared and preserved, thanks to advances in photogrammetric technology. Photogrammetry applications are expanding across industries and becoming increasingly accessible.
Museums can provide tours of items or sites they otherwise wouldn’t have had room to display. Buyers can use augmented-reality experiences to see how a product might fit in a space before purchasing it. And sports fans can choose seats with the best view.
Learn more about NVIDIA RTX professionals GPUs and photogrammetry in the webinar, Getting Started With Photogrammetry for AECO Reality Capture.
]]>“Please hold” may be the two words that customers hate most — and that contact center agents take pains to avoid saying.
Providing fast, accurate, helpful responses based on contextually relevant information is key to effective customer service. It’s even better if answers are personalized and take into account how a customer might be feeling.
All of this is made easier and quicker for human agents by what the industry calls agent assists.
Agent assist technology uses AI and machine learning to provide facts and make real-time suggestions that help human agents across telecom, retail and other industries conduct conversations with customers.
It can integrate with contact centers’ existing applications, provide faster onboarding for agents, improve the accuracy and efficiency of their responses, and increase customer satisfaction and loyalty.
How Agent Assist Technology Works
Agent assist technology gives human agents AI-powered information and real-time recommendations that can enhance their customer conversations.
Taking conversations as input, agent assist technology outputs accurate, timely suggestions on how to best respond to queries — using a combination of automatic speech recognition (ASR), natural language processing (NLP), machine learning and data analytics.
While a customer speaks to a human agent, ASR tools — like the NVIDIA Riva software development kit — transcribe speech into text, in real time. The text can then be run through NLP, AI and machine learning models that offer recommendations to the human agent by analyzing different aspects of the conversation.
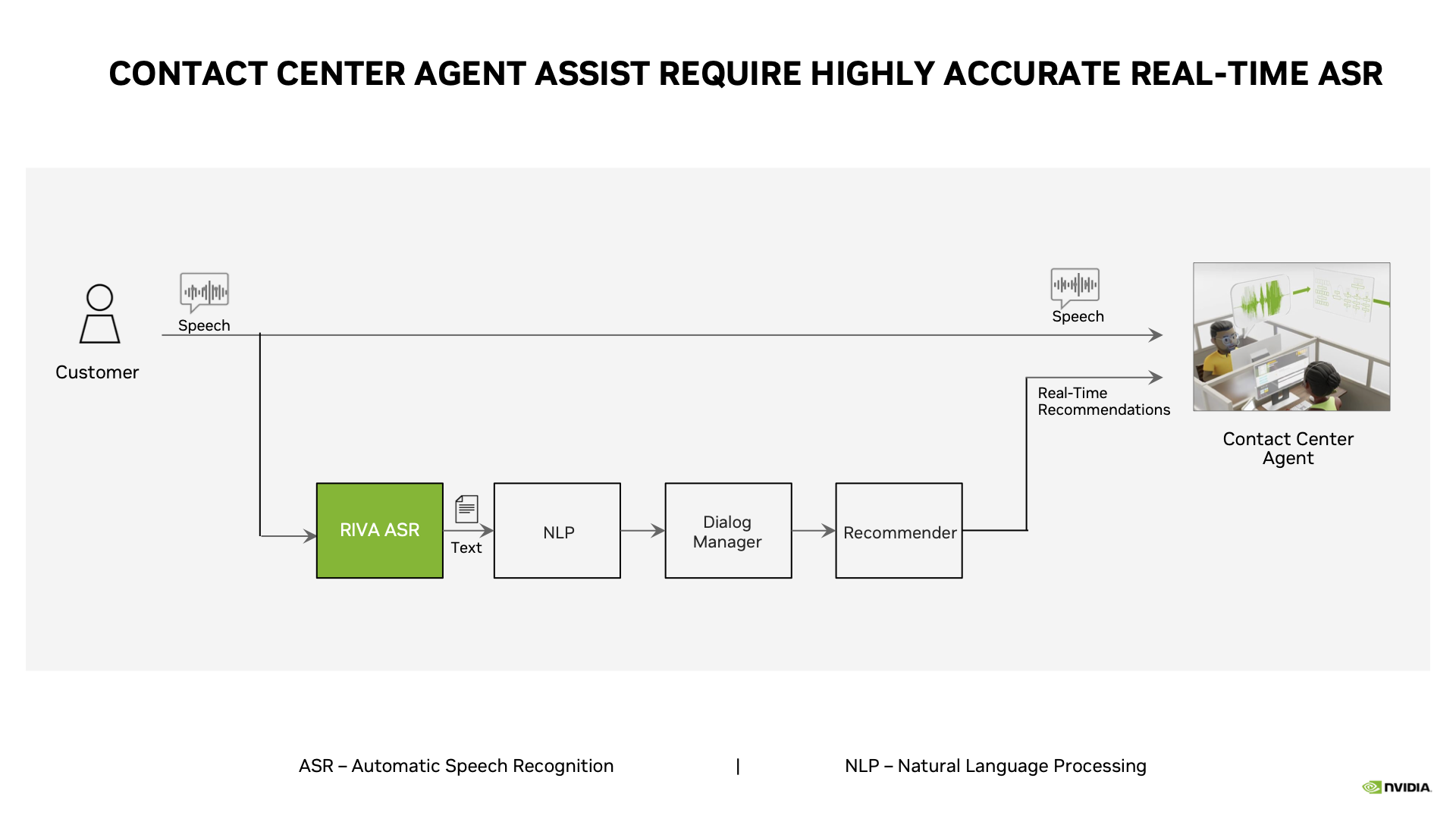
First, AI models can evaluate the context of the conversation, identify topics and bring up relevant information for the human agent — like the customer’s account data , a record of their previous inquiries, documents with recommended products and additional information to help resolve issues.
Say a customer is looking to switch to a new phone plan. The agent assist could, for example, immediately display a chart on the human agent’s screen comparing the company’s offerings, which can be used as a reference throughout the conversation.
Another AI model can perform sentiment analysis based on the words a customer is using.
For example, if a customer says, “I’m extremely frustrated with my cellular reception,” the agent assist would advise the human agent to approach the customer differently from a situation where the customer says, “I am happy with my phone plan but am looking for something less expensive.”
It can even present a human agent with verbiage to consider using when soothing, encouraging, informing or otherwise guiding a customer toward conflict resolution.
And, at a conversation’s conclusion, agent assist technology can provide personalized, best next steps for the human agent to give the customer. It can also offer the human agent a summary of the interaction overall, along with feedback to inform future conversations and employee training.
All such ASR, NLP and AI-powered capabilities come together in agent assist technology, which is becoming increasingly integral to businesses across industries.
How Agent Assist Technology Helps Businesses, Customers
By tapping into agent assist technology, businesses can improve productivity, employee retention and customer satisfaction, among other benefits.
On average, agent assist technology helps increase productivity for human agents by 14%, according to a recent study at the National Bureau of Economic Research.
For one, agent assist technology reduces contact center call times. Through NLP and intelligent routing algorithms, it can identify customer needs in real time, so human agents don’t need to hunt for basic customer information or search databases for answers.
Leading telecom provider T-Mobile — which offers award-winning service across its Customer Experience Centers — uses agent assist technology to help tackle millions of daily customer care calls. The NVIDIA NeMo framework helped the company achieve 10% higher accuracy for its ASR-generated transcripts across noisy environments, and Riva reduced latency for its agent assist by 10x. (Dive deeper into speech AI by watching T-Mobile’s on-demand NVIDIA GTC session.)
Agent assist technology also speeds up the onboarding process for human agents, helping them quickly become familiar with the products and services offered by their organization. In addition, it empowers contact center employees to provide high levels of service while maintaining low levels of stress — which means higher employee retention for enterprises.
Quicker, more accurate conflict resolution enabled by agent assist also leads to more positive contact center experiences, happier customers and increased loyalty for businesses.
Use Cases Across Industries
Agent assist technology can be used across industries, including:
- Telecom — Agent assist can provide automated troubleshooting, technical tips and other helpful information for agents to relay to customers.
- Retail — Agent assist can suggest products, features, pricing, inventory information and more in real time, as well as translate languages according to customer preferences.
- Financial services — Agent assist can help detect fraud attempts by providing real-time alerts, so that human agents are aware of any suspicious activity throughout an inquiry.
Minerva CQ, a member of the NVIDIA Inception program for cutting-edge startups, provides agent assist technology that brings together real-time, adaptive workflows with behavioral cues, dialogue suggestions and knowledge surfacing to drive faster, better outcomes. Its technology — based on Riva, NeMo and NVIDIA Triton Inference Server — focuses on helping human agents in the energy, healthcare and telecom sectors.
History and Future of Agent Assist
Predecessors of agent assist technology can be traced back to the 1950s, when computer-based systems first replaced manual call routing.
More recently came intelligent virtual assistants, which are usually automated systems or bots that don’t have a human working behind them.
Smart devices and mobile technology have led to a rise in the popularity of these intelligent virtual assistants, which can answer questions, set reminders, play music, control home devices and handle other simple tasks.
But complex tasks and inquiries — especially for enterprises with customer service at their core — can be solved most efficiently when human agents are augmented by AI-powered suggestions. This is where agent assist technology has stepped in.
The technology has much potential for further advancement, with challenges including:
- Developing methods for agent assists to adapt to changing customer expectations and preferences.
- Further ensuring data privacy and security through encryption and other methods to strip conversations of confidential or sensitive information before running them through agent assist AI models.
- Integrating agent assist with other emerging technologies like interactive digital avatars, which can see, hear, understand and communicate with end users to help customers while boosting their sentiment.
Learn more about NVIDIA speech AI technologies.
Additional resources:
- Webinar: How Telcos Transform Customer Experiences With Conversational AI.
- Webinar: Empower Telco Contact Center Agents With Multi-Language Speech-AI-Customized Agent Assists.
- On-Demand NVIDIA GTC Sessions: T-Mobile and AT&T
- Customer Story: T-Mobile
What’s the difference between NVIDIA GeForce RTX 30 and 40 Series GPUs for gamers?
To briefly set aside the technical specifications, the difference lies in the level of performance and capability each series offers.
Both deliver great graphics. Both offer advanced new features driven by NVIDIA’s global AI revolution a decade ago. Either can power glorious high-def gaming experiences.
But the RTX 40 Series takes everything RTX GPUs deliver and turns it up to 11.
“Think of any current PC gaming workload that includes ‘future-proofed’ overkill settings, then imagine the RTX 4090 making like Grave Digger and crushing those tests like abandoned cars at a monster truck rally,” writes Ars Technica.

Common Ground: RTX 30 and 40 Series Features
That said, the RTX 30 Series and 40 Series GPUs have a lot in common.
Both offer hardware-accelerated ray tracing thanks to specialized RT Cores. They also have AI-enabling Tensor Cores that supercharge graphics. And both come loaded with support for next-generation AI and rendering technologies.
But NVIDIA’s GeForce RTX 40 Series delivers all this in a simply unmatched way.
Unveiling the GeForce RTX 40 Series
Unveiled in September 2022, the RTX 40 Series GPUs consist of four variations: the RTX 4090, RTX 4080, RTX 4070 Ti and RTX 4070.
All four are built on NVIDIA’s Ada Lovelace architecture, a significant upgrade over the NVIDIA Ampere architecture used in the RTX 30 Series GPUs.
Tensor and RT Cores Evolution
While both 30 Series and 40 Series GPUs utilize Tensor Cores, Ada’s new fourth-generation Tensor Cores are unbelievably fast, increasing throughput by up to 5x, to 1.4 Tensor-petaflops using the new FP8 Transformer Engine, first introduced in NVIDIA’s Hopper architecture H100 data center GPU.
NVIDIA made real-time ray tracing a reality with the invention of RT Cores, dedicated processing cores on the GPU designed to tackle performance-intensive ray-tracing workloads.
Stay updated on the latest news, features, and tips for gaming, creating, and streaming with NVIDIA GeForce; check out GeForce News – the ultimate destination for GeForce enthusiasts.
Advanced ray tracing requires computing the impact of many rays striking numerous different material types throughout a scene, creating a sequence of divergent, inefficient workloads for the shaders to calculate the appropriate levels of light, darkness and color while rendering a 3D scene.
Ada’s third-generation RT Cores have up to twice the ray-triangle intersection throughput, increasing RT-TFLOP performance by over 2x vs. Ampere’s best.
Shader Execution Reordering and In-Game Performance
And Ada’s new Shader Execution Reordering technology dynamically reorganizes these previously inefficient workloads into considerably more efficient ones. SER can improve shader performance for ray-tracing operations by up to 3x and in-game frame rates by up to 25%.
As a result, 40 Series GPUs excel at real-time ray tracing, delivering unmatched gameplay on the most demanding titles, such as Cyberpunk 2077 that support the technology.
DLSS 3 and Optical Flow Accelerator
Ada also advances NVIDIA DLSS, which brings advanced deep learning techniques to graphics, massively boosting performance.
Powered by the new fourth-gen Tensor Cores and Optical Flow Accelerator on GeForce RTX 40 Series GPUs, DLSS 3 uses AI to create additional high-quality frames.
As a result, RTX 40 Series GPUs deliver buttery-smooth gameplay in the latest and greatest PC games.
Eighth-Generation NVIDIA Encoders
NVIDIA GeForce RTX 40 Series graphics cards also feature new eighth-generation NVENC (NVIDIA Encoders) with AV1 encoding, enabling new possibilities for streamers, broadcasters, video callers and creators.
AV1 is 40% more efficient than H.264. This allows users streaming at 1080p to increase their stream resolution to 1440p while running at the same bitrate and quality.
Remote workers will be able to communicate more smoothly with colleagues and clients. For creators, the ability to stream high-quality video with reduced bandwidth requirements can enable smoother collaboration and content delivery, allowing for a more efficient creative process.
Cutting-Edge Manufacturing and Efficiency
RTX 40 Series GPUs are also built at the absolute cutting edge, with a custom TSMC 4N process. The process and Ada architecture are ultra-efficient.
And RTX 40 Series GPUs come loaded with the memory needed to keep its Ada GPUs running at full tilt.
RTX 30 Series GPUs: Still a Solid Choice
All that said, RTX 30 Series GPUs remain powerful and popular.
Launched in September 2020, the RTX 30 Series GPUs include a range of different models, from the RTX 3050 to the RTX 3090 Ti.
All deliver the grunt to run the latest games in high definition and at smooth frame rates.

But while the RTX 30 Series GPUs have remained a popular choice for gamers and professionals since their release, the RTX 40 Series GPUs offer significant improvements for gamers and creators alike, particularly those who want to crank up settings with high frames rates, drive big 4K displays, or deliver buttery-smooth streaming to global audiences.
With higher performance, enhanced ray-tracing capabilities, support for DLSS 3 and better power efficiency, the RTX 40 Series GPUs are an attractive option for those who want the latest and greatest technology.
Related Content
- NVIDIA Ada Lovelace Architecture: Ahead of its Time, Ahead of the Game
- NVIDIA DLSS 3: The Performance Multiplier, Powered by AI
- NVIDIA Reflex: Victory Measured in Milliseconds
- NVIDIA Studio: Your Creativity AI Take
- How to Build a Gaming PC with an RTX 40 Series GPU
- The Best Games to Play on RTX 40 Series GPUs
- How to Stream Like a Pro with an RTX 40 Series GPU
The mics were live and tape was rolling in the studio where the Miles Davis Quintet was recording dozens of tunes in 1956 for Prestige Records.
When an engineer asked for the next song’s title, Davis shot back, “I’ll play it, and tell you what it is later.”
Like the prolific jazz trumpeter and composer, researchers have been generating AI models at a feverish pace, exploring new architectures and use cases. Focused on plowing new ground, they sometimes leave to others the job of categorizing their work.
A team of more than a hundred Stanford researchers collaborated to do just that in a 214-page paper released in the summer of 2021.
They said transformer models, large language models (LLMs) and other neural networks still being built are part of an important new category they dubbed foundation models.
Foundation Models Defined
A foundation model is an AI neural network — trained on mountains of raw data, generally with unsupervised learning — that can be adapted to accomplish a broad range of tasks, the paper said.
“The sheer scale and scope of foundation models from the last few years have stretched our imagination of what’s possible,” they wrote.
Two important concepts help define this umbrella category: Data gathering is easier, and opportunities are as wide as the horizon.
No Labels, Lots of Opportunity
Foundation models generally learn from unlabeled datasets, saving the time and expense of manually describing each item in massive collections.
Earlier neural networks were narrowly tuned for specific tasks. With a little fine-tuning, foundation models can handle jobs from translating text to analyzing medical images.
Foundation models are demonstrating “impressive behavior,” and they’re being deployed at scale, the group said on the website of its research center formed to study them. So far, they’ve posted more than 50 papers on foundation models from in-house researchers alone.
“I think we’ve uncovered a very small fraction of the capabilities of existing foundation models, let alone future ones,” said Percy Liang, the center’s director, in the opening talk of the first workshop on foundation models.
AI’s Emergence and Homogenization
In that talk, Liang coined two terms to describe foundation models:
Emergence refers to AI features still being discovered, such as the many nascent skills in foundation models. He calls the blending of AI algorithms and model architectures homogenization, a trend that helped form foundation models. (See chart below.)
 The field continues to move fast.
The field continues to move fast.
A year after the group defined foundation models, other tech watchers coined a related term — generative AI. It’s an umbrella term for transformers, large language models, diffusion models and other neural networks capturing people’s imaginations because they can create text, images, music, software and more.
Generative AI has the potential to yield trillions of dollars of economic value, said executives from the venture firm Sequoia Capital who shared their views in a recent AI Podcast.
A Brief History of Foundation Models
“We are in a time where simple methods like neural networks are giving us an explosion of new capabilities,” said Ashish Vaswani, an entrepreneur and former senior staff research scientist at Google Brain who led work on the seminal 2017 paper on transformers.
That work inspired researchers who created BERT and other large language models, making 2018 “a watershed moment” for natural language processing, a report on AI said at the end of that year.
Google released BERT as open-source software, spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs. Then it applied the technology to its search engine so users could ask questions in simple sentences.
In 2020, researchers at OpenAI announced another landmark transformer, GPT-3. Within weeks, people were using it to create poems, programs, songs, websites and more.
“Language models have a wide range of beneficial applications for society,” the researchers wrote.
Their work also showed how large and compute-intensive these models can be. GPT-3 was trained on a dataset with nearly a trillion words, and it sports a whopping 175 billion parameters, a key measure of the power and complexity of neural networks.
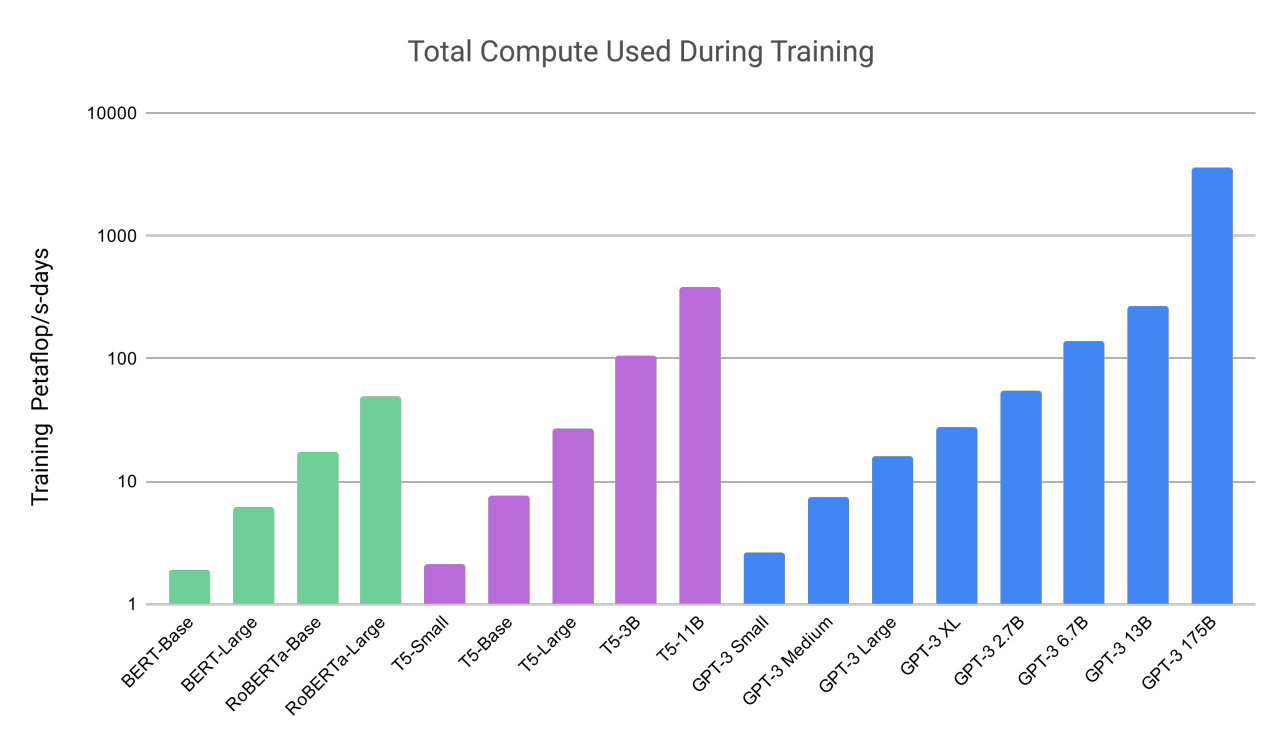
“I just remember being kind of blown away by the things that it could do,” said Liang, speaking of GPT-3 in a podcast.
The latest iteration, ChatGPT — trained on 10,000 NVIDIA GPUs — is even more engaging, attracting over 100 million users in just two months. Its release has been called the iPhone moment for AI because it helped so many people see how they could use the technology.

From Text to Images
About the same time ChatGPT debuted, another class of neural networks, called diffusion models, made a splash. Their ability to turn text descriptions into artistic images attracted casual users to create amazing images that went viral on social media.
The first paper to describe a diffusion model arrived with little fanfare in 2015. But like transformers, the new technique soon caught fire.
Researchers posted more than 200 papers on diffusion models last year, according to a list maintained by James Thornton, an AI researcher at the University of Oxford.
In a tweet, Midjourney CEO David Holz revealed that his diffusion-based, text-to-image service has more than 4.4 million users. Serving them requires more than 10,000 NVIDIA GPUs mainly for AI inference, he said in an interview (subscription required).
Dozens of Models in Use
Hundreds of foundation models are now available. One paper catalogs and classifies more than 50 major transformer models alone (see chart below).
The Stanford group benchmarked 30 foundation models, noting the field is moving so fast they did not review some new and prominent ones.
Startup NLP Cloud, a member of the NVIDIA Inception program that nurtures cutting-edge startups, says it uses about 25 large language models in a commercial offering that serves airlines, pharmacies and other users. Experts expect that a growing share of the models will be made open source on sites like Hugging Face’s model hub.
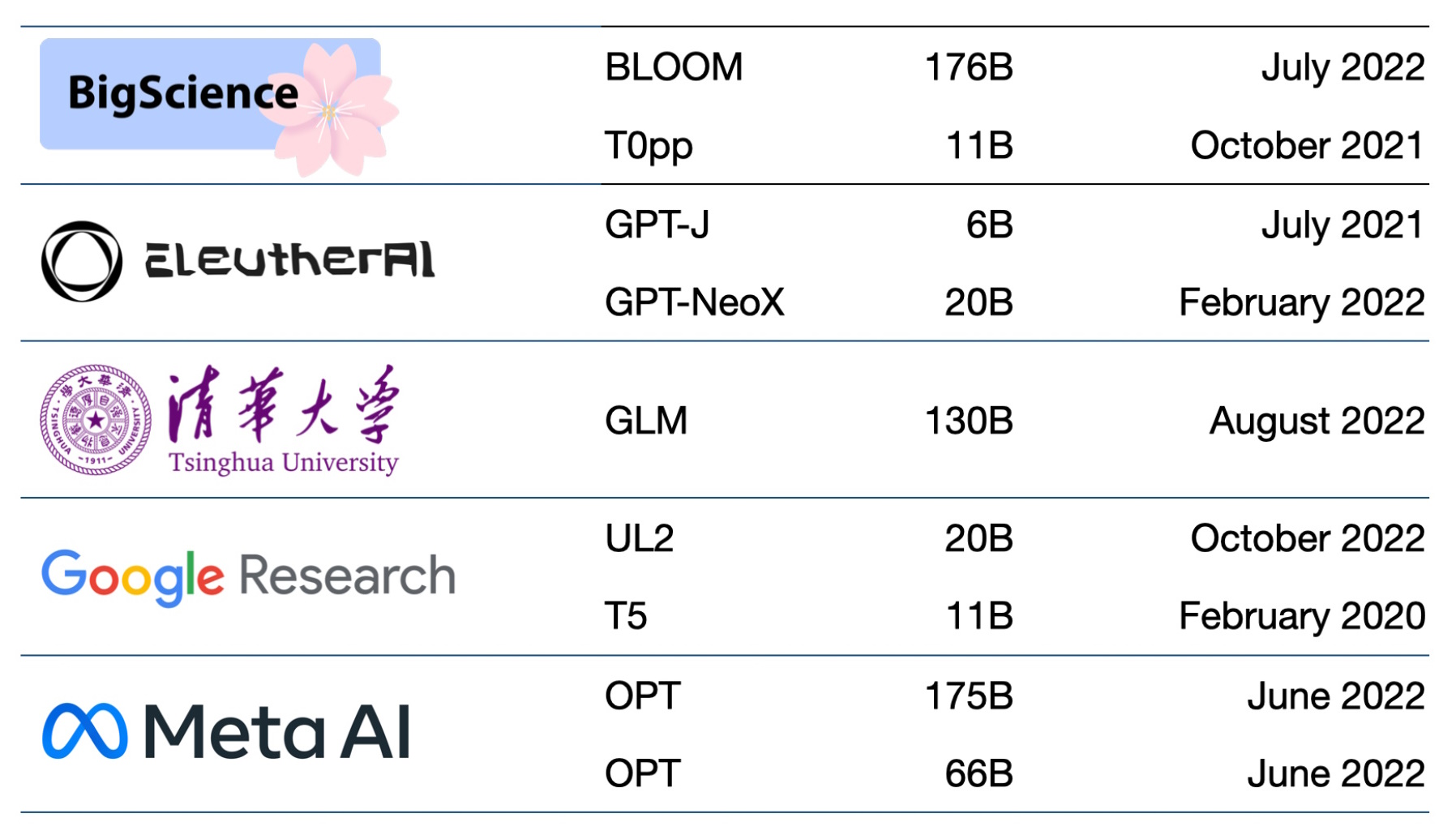
Foundation models keep getting larger and more complex, too.
That’s why — rather than building new models from scratch — many businesses are already customizing pretrained foundation models to turbocharge their journeys into AI, using online services like NVIDIA AI Foundation Models.
The accuracy and reliability of generative AI is increasing thanks to techniques like retrieval-augmented generation, aka RAG, that lets foundation models tap into external resources like a corporate knowledge base.
Foundations in the Cloud
One venture capital firm lists 33 use cases for generative AI, from ad generation to semantic search.
Major cloud services have been using foundation models for some time. For example, Microsoft Azure worked with NVIDIA to implement a transformer for its Translator service. It helped disaster workers understand Haitian Creole while they were responding to a 7.0 earthquake.
In February, Microsoft announced plans to enhance its browser and search engine with ChatGPT and related innovations. “We think of these tools as an AI copilot for the web,” the announcement said.
Google announced Bard, an experimental conversational AI service. It plans to plug many of its products into the power of its foundation models like LaMDA, PaLM, Imagen and MusicLM.
“AI is the most profound technology we are working on today,” the company’s blog wrote.
Startups Get Traction, Too
Startup Jasper expects to log $75 million in annual revenue from products that write copy for companies like VMware. It’s leading a field of more than a dozen companies that generate text, including Writer, an NVIDIA Inception member.
Other Inception members in the field include Tokyo-based rinna that’s created chatbots used by millions in Japan. In Tel Aviv, Tabnine runs a generative AI service that’s automated up to 30% of the code written by a million developers globally.
A Platform for Healthcare
Researchers at startup Evozyne used foundation models in NVIDIA BioNeMo to generate two new proteins. One could treat a rare disease and another could help capture carbon in the atmosphere.
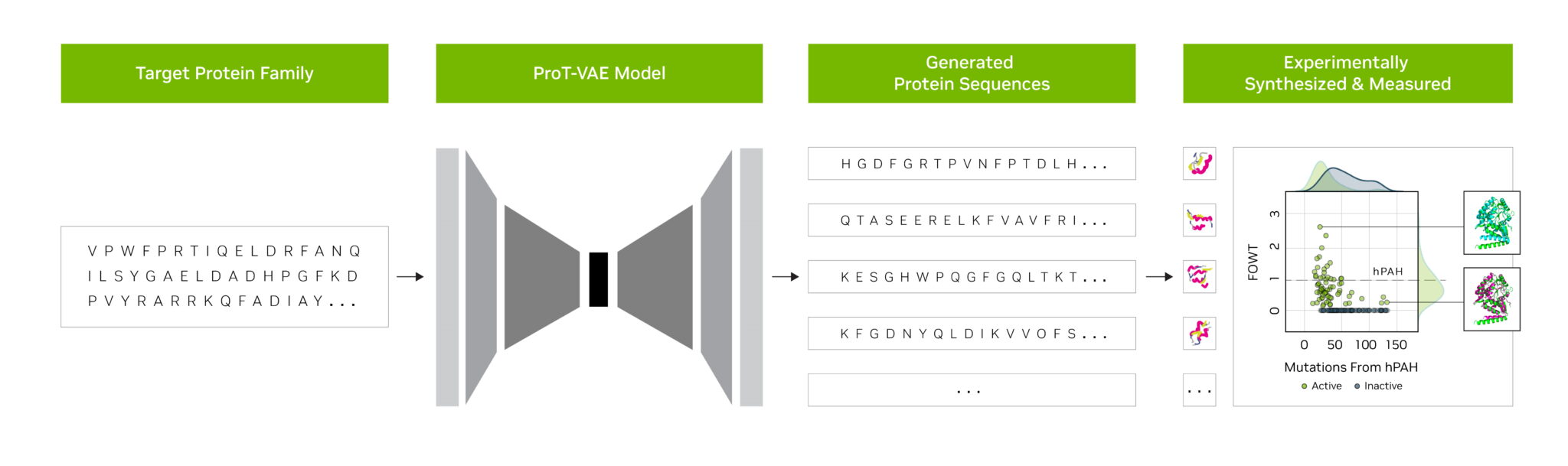
BioNeMo, a software platform and cloud service for generative AI in drug discovery, offers tools to train, run inference and deploy custom biomolecular AI models. It includes MegaMolBART, a generative AI model for chemistry developed by NVIDIA and AstraZeneca.
“Just as AI language models can learn the relationships between words in a sentence, our aim is that neural networks trained on molecular structure data will be able to learn the relationships between atoms in real-world molecules,” said Ola Engkvist, head of molecular AI, discovery sciences and R&D at AstraZeneca, when the work was announced.
Separately, the University of Florida’s academic health center collaborated with NVIDIA researchers to create GatorTron. The large language model aims to extract insights from massive volumes of clinical data to accelerate medical research.
A Stanford center is applying the latest diffusion models to advance medical imaging. NVIDIA also helps healthcare companies and hospitals use AI in medical imaging, speeding diagnosis of deadly diseases.
AI Foundations for Business
Another new framework, NVIDIA NeMo framework, aims to let any business create its own billion- or trillion-parameter transformers to power custom chatbots, personal assistants and other AI applications.
It created the 530-billion parameter Megatron-Turing Natural Language Generation model (MT-NLG) that powers TJ, the Toy Jensen avatar that gave part of the keynote at NVIDIA GTC last year.
Foundation models — connected to 3D platforms like NVIDIA Omniverse — will be key to simplifying development of the metaverse, the 3D evolution of the internet. These models will power applications and assets for entertainment and industrial users.
Factories and warehouses are already applying foundation models inside digital twins, realistic simulations that help find more efficient ways to work.
Foundation models can ease the job of training autonomous vehicles and robots that assist humans on factory floors and logistics centers. They also help train autonomous vehicles by creating realistic environments like the one below.
New uses for foundation models are emerging daily, as are challenges in applying them.
Several papers on foundation and generative AI models describing risks such as:
- amplifying bias implicit in the massive datasets used to train models,
- introducing inaccurate or misleading information in images or videos, and
- violating intellectual property rights of existing works.
“Given that future AI systems will likely rely heavily on foundation models, it is imperative that we, as a community, come together to develop more rigorous principles for foundation models and guidance for their responsible development and deployment,” said the Stanford paper on foundation models.
Current ideas for safeguards include filtering prompts and their outputs, recalibrating models on the fly and scrubbing massive datasets.
“These are issues we’re working on as a research community,” said Bryan Catanzaro, vice president of applied deep learning research at NVIDIA. “For these models to be truly widely deployed, we have to invest a lot in safety.”
It’s one more field AI researchers and developers are plowing as they create the future.
]]>Accelerated computing — a capability once confined to high-performance computers in government research labs — has gone mainstream.
Banks, car makers, factories, hospitals, retailers and others are adopting AI supercomputers to tackle the growing mountains of data they need to process and understand.
These powerful, efficient systems are superhighways of computing. They carry data and calculations over parallel paths on a lightning journey to actionable results.
GPU and CPU processors are the resources along the way, and their onramps are fast interconnects. The gold standard in interconnects for accelerated computing is NVLink.
So, What Is NVLink?
NVLink is a high-speed connection for GPUs and CPUs formed by a robust software protocol, typically riding on multiple pairs of wires printed on a computer board. It lets processors send and receive data from shared pools of memory at lightning speed.

Now in its fourth generation, NVLink connects host and accelerated processors at rates up to 900 gigabytes per second (GB/s).
That’s more than 7x the bandwidth of PCIe Gen 5, the interconnect used in conventional x86 servers. And NVLink sports 5x the energy efficiency of PCIe Gen 5, thanks to data transfers that consume just 1.3 picojoules per bit.
The History of NVLink
First introduced as a GPU interconnect with the NVIDIA P100 GPU, NVLink has advanced in lockstep with each new NVIDIA GPU architecture.

In 2018, NVLink hit the spotlight in high performance computing when it debuted connecting GPUs and CPUs in two of the world’s most powerful supercomputers, Summit and Sierra.
The systems, installed at Oak Ridge and Lawrence Livermore National Laboratories, are pushing the boundaries of science in fields such as drug discovery, natural disaster prediction and more.
Bandwidth Doubles, Then Grows Again
In 2020, the third-generation NVLink doubled its max bandwidth per GPU to 600GB/s, packing a dozen interconnects in every NVIDIA A100 Tensor Core GPU.
The A100 powers AI supercomputers in enterprise data centers, cloud computing services and HPC labs across the globe.
Today, 18 fourth-generation NVLink interconnects are embedded in a single NVIDIA H100 Tensor Core GPU. And the technology has taken on a new, strategic role that will enable the most advanced CPUs and accelerators on the planet.
A Chip-to-Chip Link
NVIDIA NVLink-C2C is a version of the board-level interconnect to join two processors inside a single package, creating a superchip. For example, it connects two CPU chips to deliver 144 Arm Neoverse V2 cores in the NVIDIA Grace CPU Superchip, a processor built to deliver energy-efficient performance for cloud, enterprise and HPC users.
NVIDIA NVLink-C2C also joins a Grace CPU and a Hopper GPU to create the Grace Hopper Superchip. It packs accelerated computing for the world’s toughest HPC and AI jobs into a single chip.
Alps, an AI supercomputer planned for the Swiss National Computing Center, will be among the first to use Grace Hopper. When it comes online later this year, the high-performance system will work on big science problems in fields from astrophysics to quantum chemistry.

Grace and Grace Hopper are also great for bringing energy efficiency to demanding cloud computing workloads.
For example, Grace Hopper is an ideal processor for recommender systems. These economic engines of the internet need fast, efficient access to lots of data to serve trillions of results to billions of users daily.

In addition, NVLink is used in a powerful system-on-chip for automakers that includes NVIDIA Hopper, Grace and Ada Lovelace processors. NVIDIA DRIVE Thor is a car computer that unifies intelligent functions such as digital instrument cluster, infotainment, automated driving, parking and more into a single architecture.
LEGO Links of Computing
NVLink also acts like the socket stamped into a LEGO piece. It’s the basis for building supersystems to tackle the biggest HPC and AI jobs.
For example, NVLinks on all eight GPUs in an NVIDIA DGX system share fast, direct connections via NVSwitch chips. Together, they enable an NVLink network where every GPU in the server is part of a single system.
To get even more performance, DGX systems can themselves be stacked into modular units of 32 servers, creating a powerful, efficient computing cluster.

Users can connect a modular block of 32 DGX systems into a single AI supercomputer using a combination of an NVLink network inside the DGX and NVIDIA Quantum-2 switched Infiniband fabric between them. For example, an NVIDIA DGX H100 SuperPOD packs 256 H100 GPUs to deliver up to an exaflop of peak AI performance.
To get even more performance, users can tap into the AI supercomputers in the cloud such as the one Microsoft Azure is building with tens of thousands of A100 and H100 GPUs. It’s a service used by groups like OpenAI to train some of the world’s largest generative AI models.
And it’s one more example of the power of accelerated computing.
]]>AI applications are summarizing articles, writing stories and engaging in long conversations — and large language models are doing the heavy lifting.
A large language model, or LLM, is a deep learning algorithm that can recognize, summarize, translate, predict and generate text and other forms of content based on knowledge gained from massive datasets.
Large language models are among the most successful applications of transformer models. They aren’t just for teaching AIs human languages, but for understanding proteins, writing software code, and much, much more.
In addition to accelerating natural language processing applications — like translation, chatbots and AI assistants — large language models are used in healthcare, software development and use cases in many other fields.
What Are Large Language Models Used For?
Language is used for more than human communication.
Code is the language of computers. Protein and molecular sequences are the language of biology. Large language models can be applied to such languages or scenarios in which communication of different types is needed.
These models broaden AI’s reach across industries and enterprises, and are expected to enable a new wave of research, creativity and productivity, as they can help to generate complex solutions for the world’s toughest problems.
For example, an AI system using large language models can learn from a database of molecular and protein structures, then use that knowledge to provide viable chemical compounds that help scientists develop groundbreaking vaccines or treatments.
Large language models are also helping to create reimagined search engines, tutoring chatbots, composition tools for songs, poems, stories and marketing materials, and more.
How Do Large Language Models Work?
Large language models learn from huge volumes of data. As its name suggests, central to an LLM is the size of the dataset it’s trained on. But the definition of “large” is growing, along with AI.
Now, large language models are typically trained on datasets large enough to include nearly everything that has been written on the internet over a large span of time.
Such massive amounts of text are fed into the AI algorithm using unsupervised learning — when a model is given a dataset without explicit instructions on what to do with it. Through this method, a large language model learns words, as well as the relationships between and concepts behind them. It could, for example, learn to differentiate the two meanings of the word “bark” based on its context.
And just as a person who masters a language can guess what might come next in a sentence or paragraph — or even come up with new words or concepts themselves — a large language model can apply its knowledge to predict and generate content.
Large language models can also be customized for specific use cases, including through techniques like fine-tuning or prompt-tuning, which is the process of feeding the model small bits of data to focus on, to train it for a specific application.
Thanks to its computational efficiency in processing sequences in parallel, the transformer model architecture is the building block behind the largest and most powerful LLMs.
Top Applications for Large Language Models
Large language models are unlocking new possibilities in areas such as search engines, natural language processing, healthcare, robotics and code generation.
The popular ChatGPT AI chatbot is one application of a large language model. It can be used for a myriad of natural language processing tasks.
The nearly infinite applications for LLMs also include:
- Retailers and other service providers can use large language models to provide improved customer experiences through dynamic chatbots, AI assistants and more.
- Search engines can use large language models to provide more direct, human-like answers.
- Life science researchers can train large language models to understand proteins, molecules, DNA and RNA.
- Developers can write software and teach robots physical tasks with large language models.
- Marketers can train a large language model to organize customer feedback and requests into clusters, or segment products into categories based on product descriptions.
- Financial advisors can summarize earnings calls and create transcripts of important meetings using large language models. And credit-card companies can use LLMs for anomaly detection and fraud analysis to protect consumers.
- Legal teams can use large language models to help with legal paraphrasing and scribing.
Running these massive models in production efficiently is resource-intensive and requires expertise, among other challenges, so enterprises turn to NVIDIA Triton Inference Server, software that helps standardize model deployment and deliver fast and scalable AI in production.
When to Use Custom Large Language Models
Many organizations are looking to use custom LLMs tailored to their use case and brand voice. These custom models built on domain-specific data unlock opportunities for enterprises to improve internal operations and offer new customer experiences. Custom models are smaller, more efficient and faster than general-purpose LLMs.
Custom models offer the best solution for applications that involve a lot of proprietary data. One example of a custom LLM is BloombergGPT, homegrown by Bloomberg. It has 50 billion parameters and is targeted at financial applications.
Where to Find Large Language Models
In June 2020, OpenAI released GPT-3 as a service, powered by a 175-billion-parameter model that can generate text and code with short written prompts.
In 2021, NVIDIA and Microsoft developed Megatron-Turing Natural Language Generation 530B, one of the world’s largest models for reading comprehension and natural language inference, which eases tasks like summarization and content generation.
And HuggingFace last year introduced BLOOM, an open large language model that’s able to generate text in 46 natural languages and over a dozen programming languages.
Another LLM, Codex, turns text to code for software engineers and other developers.
NVIDIA offers tools to ease the building and deployment of large language models:
- NVIDIA NeMo LLM Service provides a fast path to customizing large language models and deploying them at scale using NVIDIA’s managed cloud API, or through private and public clouds.
- NVIDIA NeMo framework, part of the NVIDIA AI platform, enables easy, efficient, cost-effective training and deployment of large language models. Designed for enterprise application development, NeMo provides an end-to-end workflow for automated distributed data processing; training large-scale, customized model types including GPT-3 and T5; and deploying these models for inference at scale.
- NVIDIA BioNeMo is a domain-specific managed service and framework for large language models in proteomics, small molecules, DNA and RNA. It’s built on NVIDIA NeMo for training and deploying large biomolecular transformer AI models at supercomputing scale.
Challenges of Large Language Models
Scaling and maintaining large language models can be difficult and expensive.
Building a foundational large language model often requires months of training time and millions of dollars.
And because LLMs require a significant amount of training data, developers and enterprises can find it a challenge to access large-enough datasets.
Due to the scale of large language models, deploying them requires technical expertise, including a strong understanding of deep learning, transformer models and distributed software and hardware.
Many leaders in tech are working to advance development and build resources that can expand access to large language models, allowing consumers and enterprises of all sizes to reap their benefits.
Learn more about large language models.
]]>The abacus, sextant, slide rule and computer. Mathematical instruments mark the history of human progress.
They’ve enabled trade and helped navigate oceans, and advanced understanding and quality of life.
The latest tool propelling science and industry is AI computing.
AI Computing Defined
AI computing is the math-intensive process of calculating machine learning algorithms, typically using accelerated systems and software. It can extract fresh insights from massive datasets, learning new skills along the way.
It’s the most transformational technology of our time because we live in a data-centric era, and AI computing can find patterns no human could.
For example, American Express uses AI computing to detect fraud in billions of annual credit card transactions. Doctors use it to find tumors, finding tiny anomalies in mountains of medical images.
Three Steps to AI Computing
Before getting into the many use cases for AI computing, let’s explore how it works.
First, users, often data scientists, curate and prepare datasets, a stage called extract/transform/load, or ETL. This work can now be accelerated on NVIDIA GPUs with Apache Spark 3.0, one of the most popular open source engines for mining big data.
Second, data scientists choose or design AI models that best suit their applications.
Some companies design and train their own models from the ground up because they are pioneering a new field or seeking a competitive advantage. This process requires some expertise and potentially an AI supercomputer, capabilities NVIDIA offers.
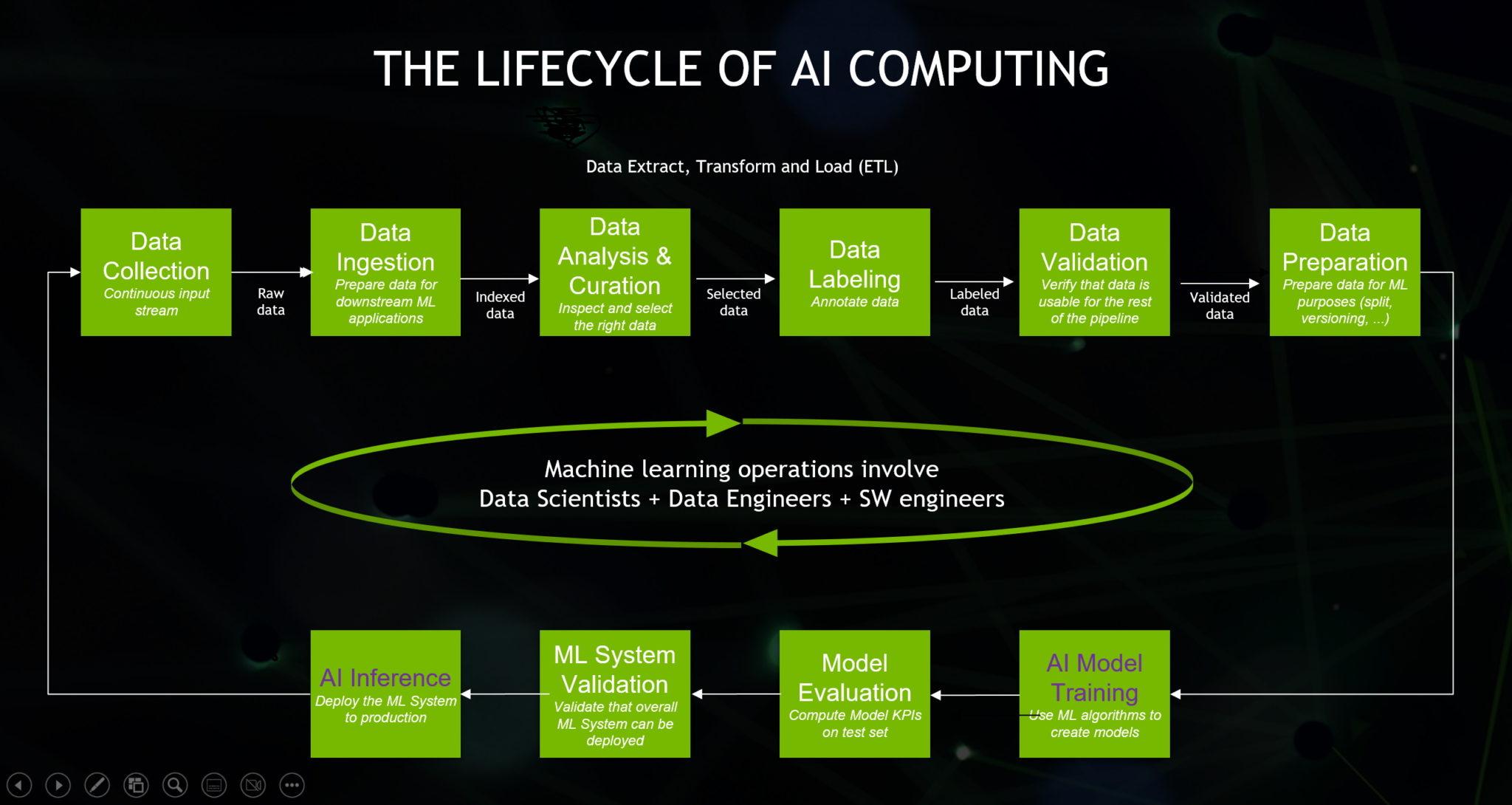
Many companies choose pretrained AI models they can customize as needed for their applications. NVIDIA provides dozens of pretrained models and tools for customizing them on NGC, a portal for software, services, and support.
Third, companies sift their data through their models. This key step, called inference, is where AI delivers actionable insights.
The three-step process involves hard work, but there’s help available, so everyone can use AI computing.
For example, NVIDIA TAO Toolkit can collapse the three steps into one using transfer learning, a way of tailoring an existing AI model for a new application without needing a large dataset. In addition, NVIDIA LaunchPad gives users hands-on training in deploying models for a wide variety of use cases.
Inside an AI Model
AI models are called neural networks because they’re inspired by the web-like connections in the human brain.
If you slice into one of these AI models, it might look like a mathematical lasagna, made up of layers of linear algebra equations. One of the most popular forms of AI is called deep learning because it uses many layers.
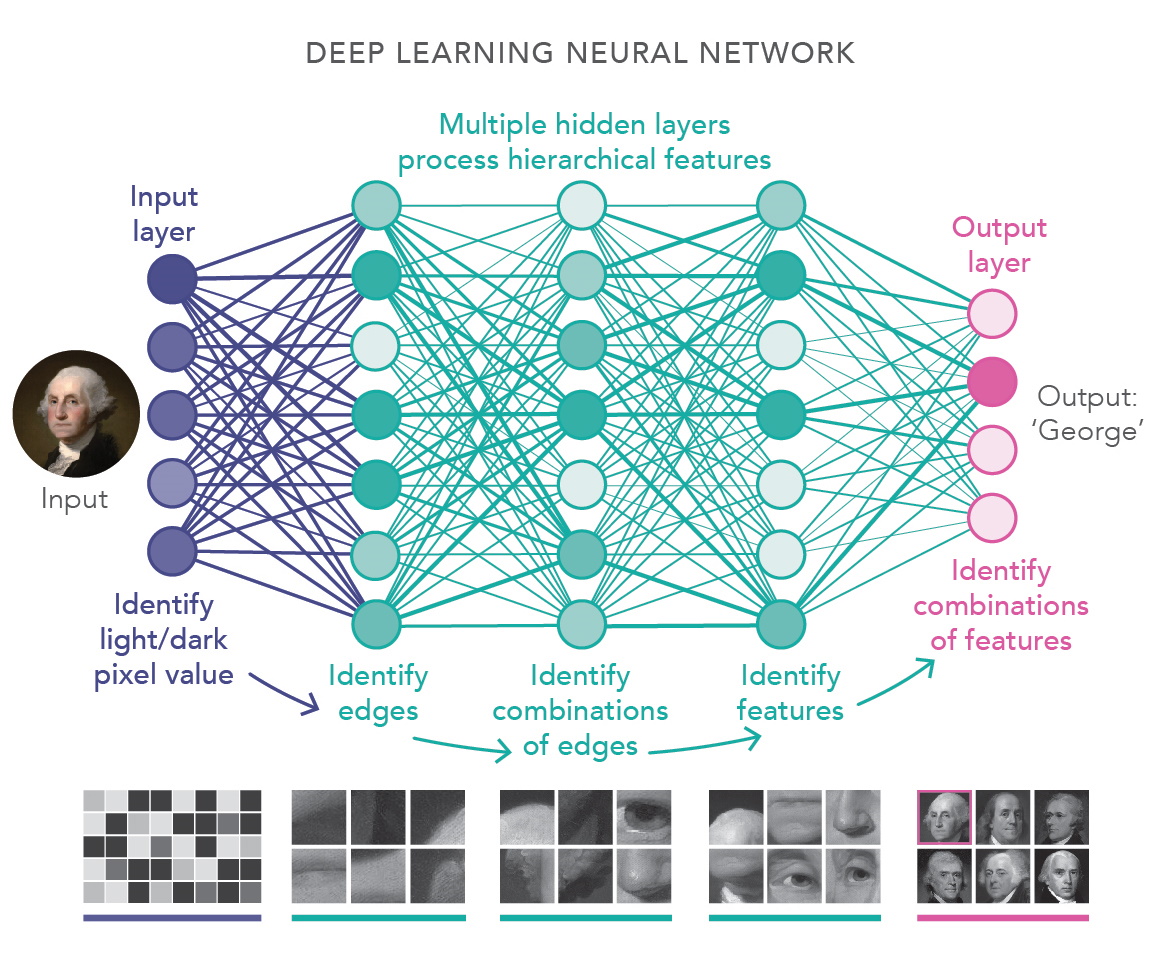
If you zoom in, you’d see each layer is made up of stacks of equations. Each represents the likelihood that one piece of data is related to another.
AI computing multiplies together every stack of equations in every layer to find patterns. It’s a huge job that requires highly parallel processors sharing massive amounts of data on fast computer networks.
GPU Computing Meets AI
GPUs are the de facto engines of AI computing.
NVIDIA debuted the first GPU in 1999 to render 3D images for video games, a job that required massively parallel calculations.
GPU computing soon spread to use in graphics servers for blockbuster movies. Scientists and researchers packed GPUs into the world’s largest supercomputers to study everything from the chemistry of tiny molecules to the astrophysics of distant galaxies.
When AI computing emerged more than a decade ago, researchers were quick to embrace NVIDIA’s programmable platform for parallel processing. The video below celebrates this brief history of the GPU.
The History of AI Computing
The idea of artificial intelligence goes back at least as far as Alan Turing, the British mathematician who helped crack coded messages during WWII.
“What we want is a machine that can learn from experience,” Turing said in a 1947 lecture in London.

Acknowledging his insights, NVIDIA named one of its computing architectures for him.
Turing’s vision became a reality in 2012 when researchers developed AI models that could recognize images faster and more accurately than humans could. Results from the ImageNet competition also greatly accelerated progress in computer vision.
Today, companies such as Landing AI, founded by machine learning luminary Andrew Ng, are applying AI and computer vision to make manufacturing more efficient. And AI is bringing human-like vision to sports, smart cities and more.
AI Computing Starts Up Conversational AI
AI computing made huge inroads in natural language processing after the invention of the transformer model in 2017. It debuted a machine-learning technique called “attention” that can capture context in sequential data like text and speech.
Today, conversational AI is widespread. It parses sentences users type into search boxes. It reads text messages when you’re driving, and lets you dictate responses.
These large language models are also finding applications in drug discovery, translation, chatbots, software development, call center automation and more.
AI + Graphics Create 3D Worlds
Users in many, often unexpected, areas are feeling the power of AI computing.
The latest video games achieve new levels of realism thanks to real-time ray tracing and NVIDIA DLSS, which uses AI to deliver ultra-smooth game play on the GeForce RTX platform.
That’s just the start. The emerging field of neural graphics will speed the creation of virtual worlds to populate the metaverse, the 3D evolution of the internet.

To kickstart that work, NVIDIA released several neural graphics tools in August.
Use Cases for AI Computing
Cars, Factories and Warehouses
Car makers are embracing AI computing to deliver a smoother, safer driving experience and deliver smart infotainment capabilities for passengers.
Mercedes-Benz is working with NVIDIA to develop software-defined vehicles. Its upcoming fleets will deliver intelligent and automated driving capabilities powered by an NVIDIA DRIVE Orin centralized computer. The systems will be tested and validated in the data center using DRIVE Sim software, built on NVIDIA Omniverse, to ensure they can safely handle all types of scenarios.
At CES, the automaker announced it will also use Omniverse to design and plan manufacturing and assembly facilities at its sites worldwide.
BMW Group is also among many companies creating AI-enabled digital twins of factories in NVIDIA Omniverse, making plants more efficient. It’s an approach also adopted by consumer giants such as PepsiCo for its logistic centers as shown in the video below.
Inside factories and warehouses, autonomous robots further enhance efficiency in manufacturing and logistics. Many are powered by the NVIDIA Jetson edge AI platform and trained with AI in simulations and digital twins using NVIDIA Isaac Sim.
In 2022, even tractors and lawn mowers became autonomous with AI.
In December, Monarch Tractor, a startup based in Livermore, Calif., released an AI-powered electric vehicle to bring automation to agriculture. In May, Scythe, based in Boulder, Colo., debuted its M.52 (below), an autonomous electric lawn mower packing eight cameras and more than a dozen sensors.
Securing Networks, Sequencing Genes
The number and variety of use cases for AI computing are staggering.
Cybersecurity software detects phishing and other network threats faster with AI-based techniques like digital fingerprinting.
In healthcare, researchers broke a record in January 2022 sequencing a whole genome in well under eight hours thanks to AI computing. Their work (described in the video below) could lead to cures for rare genetic diseases.
AI computing is at work in banks, retail shops and post offices. It’s used in telecom, transport and energy networks, too.
For example, the video below shows how Siemens Gamesa is using AI models to simulate wind farms and boost energy production.
As today’s AI computing techniques find new applications, researchers are inventing newer and more powerful methods.
Another powerful class of neural networks, diffusion models, became popular in 2022 because they could turn text descriptions into fascinating images. Researchers expect these models will be applied to many uses, further expanding the horizon for AI computing.
]]>